如果你的java基础较弱,或者不大了解java多线程请先看这篇文章 java多线程(一)线程定义、状态和属性
同步一直是java多线程的难点,在我们做android开发时也很少应用,但这并不是我们不熟悉同步的理由。希望这篇文章能使更多的人能够了解并且应用java的同步。
在多线程的应用中,两个或者两个以上的线程需要共享对同一个数据的存取。如果两个线程存取相同的对象,并且每一个线程都调用了修改该对象的方法,这种情况通常成为竞争条件。
竞争条件最容易理解的例子就是:比如火车卖票,火车票是一定的,但卖火车票的窗口到处都有,每个窗口就相当于一个线程,这么多的线程共用所有的火车票这个资源。并且无法保证其原子性,如果在一个时间点上,两个线程同时使用这个资源,那他们取出的火车票是一样的(座位号一样),这样就会给乘客造成麻烦。解决方法为,当一个线程要使用火车票这个资源时,我们就交给它一把锁,等它把事情做完后在把锁给另一个要用这个资源的线程。这样就不会出现上述情况。
1. 锁对象
synchronized关键字自动提供了锁以及相关的条件,大多数需要显式锁的情况使用synchronized非常的方便,但是等我们了解ReentrantLock类和条件对象时,我们能更好的理解synchronized关键字。ReentrantLock是JAVA SE 5.0引入的, 用ReentrantLock保护代码块的结构如下:
mLock.lock();
try{
...
}
finally{
mLock.unlock();
}这一结构确保任何时刻只有一个线程进入临界区,一旦一个线程封锁了锁对象,其他任何线程都无法通过lock语句。当其他线程调用lock时,它们则被阻塞直到第一个线程释放锁对象。把解锁的操作放在finally中是十分必要的,如果在临界区发生了异常,锁是必须要释放的,否则其他线程将会永远阻塞。
2. 条件对象
进入临界区时,却发现在某一个条件满足之后,它才能执行。要使用一个条件对象来管理那些已经获得了一个锁但是却不能做有用工作的线程,条件对象又称作条件变量。
我们来看看下面的例子来看看为何需要条件对象
假设一个场景我们需要用银行转账,我们首先写了银行的类,它的构造函数需要传入账户数量和账户金额
public class Bank {
private double[] accounts;
private Lock bankLock;
public Bank(int n,double initialBalance){
accounts=new double[n];
bankLock=new ReentrantLock();
for (int i=0;i<accounts.length;i++){
accounts[i]=initialBalance;
}
}
}接下来我们要提款,写一个提款的方法,from是转账方,to是接收方,amount转账金额,结果我们发现转账方余额不足,如果有其他线程给这个转账方再存足够的钱就可以转账成功了,但是这个线程已经获取了锁,它具有排他性,别的线程也无法获取锁来进行存款操作,这就是我们需要引入条件对象的原因。
public void transfer(int from,int to,int amount){
bankLock.lock();
try{
while (accounts[from]<amount){
//wait
}
}finally {
bankLock.unlock();
}
}一个锁对象拥有多个相关的条件对象,可以用newCondition方法获得一个条件对象,我们得到条件对象后调用await方法,当前线程就被阻塞了并放弃了锁
public class Bank {
private double[] accounts;
private Lock bankLock;
private Condition condition;
public Bank(int n,double initialBalance){
accounts=new double[n];
bankLock=new ReentrantLock();
//得到条件对象
condition=bankLock.newCondition();
for (int i=0;i<accounts.length;i++){
accounts[i]=initialBalance;
}
}
public void transfer(int from,int to,int amount) throws InterruptedException {
bankLock.lock();
try{
while (accounts[from]<amount){
//阻塞当前线程,并放弃锁
condition.await();
}
}finally {
bankLock.unlock();
}
}
}
等待获得锁的线程和调用await方法的线程本质上是不同的,一旦一个线程调用的await方法,他就会进入该条件的等待集。当锁可用时,该线程不能马上解锁,相反他处于阻塞状态,直到另一个线程调用了同一个条件上的signalAll方法时为止。当另一个线程准备转账给我们此前的转账方时,只要调用condition.signalAll();该调用会重新激活因为这一条件而等待的所有线程。
当一个线程调用了await方法他没法重新激活自身,并寄希望于其他线程来调用signalAll方法来激活自身,如果没有其他线程来激活等待的线程,那么就会产生死锁现象,如果所有的其他线程都被阻塞,最后一个活动线程在解除其他线程阻塞状态前调用await,那么它也被阻塞,就没有任何线程可以解除其他线程的阻塞,程序就被挂起了。
那何时调用signalAll呢?正常来说应该是有利于等待线程的方向改变时来调用signalAll。在这个例子里就是,当一个账户余额发生变化时,等待的线程应该有机会检查余额。
public void transfer(int from,int to,int amount) throws InterruptedException {
bankLock.lock();
try{
while (accounts[from]<amount){
//阻塞当前线程,并放弃锁
condition.await();
}
//转账的操作
...
condition.signalAll();
}finally {
bankLock.unlock();
}
}当调用signalAll方法时并不是立即激活一个等待线程,它仅仅解除了等待线程的阻塞,以便这些线程能够在当前线程退出同步方法后,通过竞争实现对对象的访问。还有一个方法是signal,它则是随机解除某个线程的阻塞,如果该线程仍然不能运行,那么则再次被阻塞,如果没有其他线程再次调用signal,那么系统就死锁了。
3. Synchronized关键字
Lock和Condition接口为程序设计人员提供了高度的锁定控制,然而大多数情况下,并不需要那样的控制,并且可以使用一种嵌入到java语言内部的机制。从Java1.0版开始,Java中的每一个对象都有一个内部锁。如果一个方法用synchronized关键字声明,那么对象的锁将保护整个方法。也就是说,要调用该方法,线程必须获得内部的对象锁。
换句话说,
public synchronized void method(){
}等价于
public void method(){
this.lock.lock();
try{
}finally{
this.lock.unlock();
}上面银行的例子,我们可以将Bank类的transfer方法声明为synchronized,而不是使用一个显示的锁。
内部对象锁只有一个相关条件,wait放大添加到一个线程到等待集中,notifyAll或者notify方法解除等待线程的阻塞状态。也就是说wait相当于调用condition.await(),notifyAll等价于condition.signalAll();
我们上面的例子transfer方法也可以这样写:
public synchronized void transfer(int from,int to,int amount)throws InterruptedException{
while (accounts[from]<amount) {
wait();
}
//转账的操作
...
notifyAll();
}可以看到使用synchronized关键字来编写代码要简洁很多,当然要理解这一代码,你必须要了解每一个对象有一个内部锁,并且该锁有一个内部条件。由锁来管理那些试图进入synchronized方法的线程,由条件来管理那些调用wait的线程。
4. 同步阻塞
上面我们说过,每一个Java对象都有一个锁,线程可以调用同步方法来获得锁,还有另一种机制可以获得锁,通过进入一个同步阻塞,当线程进入如下形式的阻塞:
synchronized(obj){
}于是他获得了obj的锁。再来看看Bank类
public class Bank {
private double[] accounts;
private Object lock=new Object();
public Bank(int n,double initialBalance){
accounts=new double[n];
for (int i=0;i<accounts.length;i++){
accounts[i]=initialBalance;
}
}
public void transfer(int from,int to,int amount){
synchronized(lock){
//转账的操作
...
}
}
}在此,lock对象创建仅仅是用来使用每个Java对象持有的锁。有时开发人员使用一个对象的锁来实现额外的原子操作,称为客户端锁定。例如Vector类,它的方法是同步的。现在假设在Vector中存储银行余额
public void transfer(Vector<Double>accounts,int from,int to,int amount){
accounts.set(from,accounts.get(from)-amount);
accounts.set(to,accounts.get(to)+amount;
}Vecror类的get和set方法是同步的,但是这并未对我们有所帮助。在第一次对get调用完成以后,一个线程完全可能在transfer方法中被被剥夺运行权,于是另一个线程可能在相同的存储位置存入了不同的值,但是,我们可以截获这个锁
public void transfer(Vector<Double>accounts,int from,int to,int amount){
synchronized(accounts){
accounts.set(from,accounts.get(from)-amount);
accounts.set(to,accounts.get(to)+amount;
}
}客户端锁定(同步代码块)是非常脆弱的,通常不推荐使用,一般实现同步最好用java.util.concurrent包下提供的类,比如阻塞队列。如果同步方法适合你的程序,那么请尽量的使用同步方法,他可以减少编写代码的数量,减少出错的几率,如果特别需要使用Lock/Condition结构提供的独有特性时,才使用Lock/Condition。











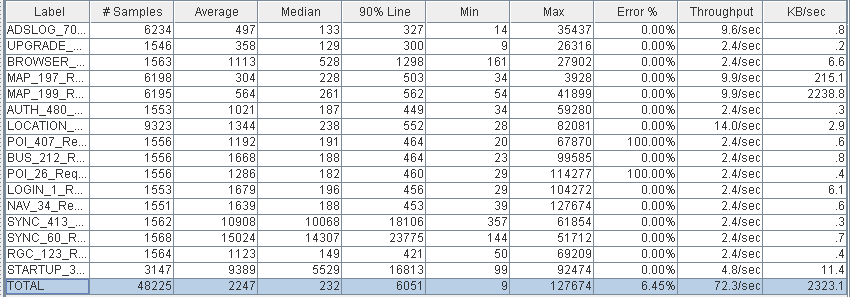 (PS Scavenge和PS MarkSweep)
(PS Scavenge和PS MarkSweep) 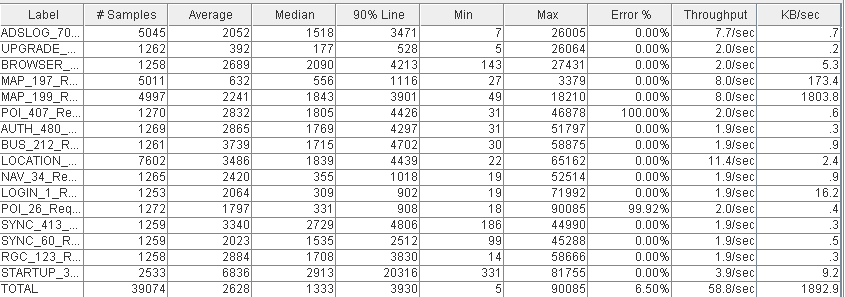 (ParNew和CMS)
(ParNew和CMS)  (PS Scavenge和PS MarkSweep)
(PS Scavenge和PS MarkSweep) 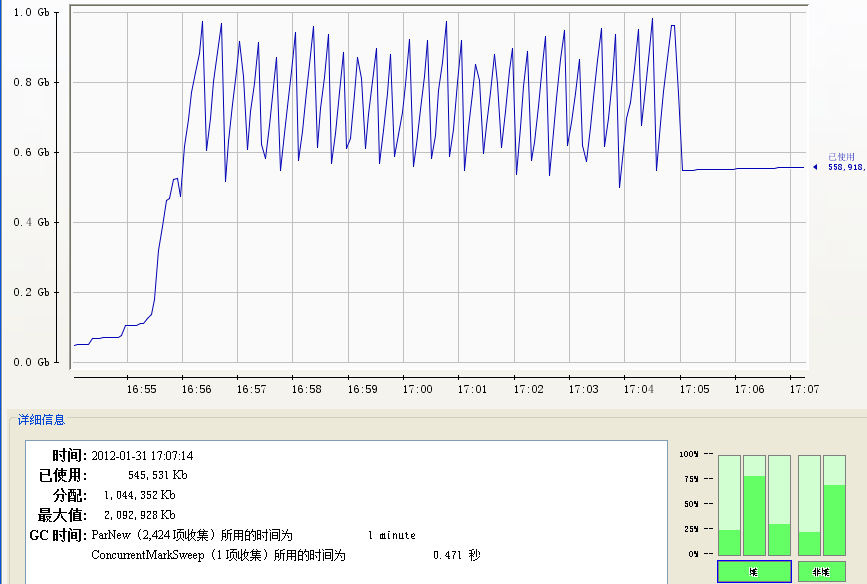 (ParNew和CMS)
(ParNew和CMS)  200m
200m  600m
600m 




.jpg)

