本文由爱奇艺技术团队原创分享,原题《构建通用WebSocket推送网关的设计与实践》,有优化和改动。
1、引言
丛所周之,HTTP协议是一种无状态、基于TCP的请求/响应模式的协议,即请求只能由客户端发起、由服务端进行响应。在大多数场景,这种请求/响应的Pull模式可以满足需求。但在某些情形:例如消息推送(IM中最为常见,比如IM的离线消息推送)、实时通知等应用场景,需要实时将数据同步到客户端,这就要求服务端支持主动Push数据的能力。
传统的Web服务端推送技术历史悠久,经历了短轮询、长轮询等阶段的发展(见《 新手入门贴:史上最全Web端即时通讯技术原理详解》),一定程度上能够解决问题,但也存在着不足,例如时效性、资源浪费等。HTML5标准带来的WebSocket规范基本结束了这一局面,成为目前服务端消息推送技术的主流方案。
在系统中集成WebSocket十分简单,相关讨论与资料很丰富。但如何实现一个通用的WebSocket推送网关尚未有成熟的方案。目前的云服务厂商主要关注iOS和安卓等移动端推送,也缺少对WebSocket的支持。本文分享了爱奇艺基于Netty实现WebSocket长连接实时推送网关时的实践经验总结。

学习交流:
- 即时通讯/推送技术开发交流5群: 215477170 [推荐]
- 移动端IM开发入门文章:《 新手入门一篇就够:从零开发移动端IM》
- 开源IM框架源码: https://github.com/JackJiang2011/MobileIMSDK
(本文同步发布于: http://www.52im.net/thread-3539-1-1.html)
2、专题目录
本文是系列文章的第4篇,总目录如下:
《 长连接网关技术专题(一):京东京麦的生产级TCP网关技术实践总结》
《 长连接网关技术专题(二):知乎千万级并发的高性能长连接网关技术实践》
《 长连接网关技术专题(三):手淘亿级移动端接入层网关的技术演进之路》
《 长连接网关技术专题(四):爱奇艺WebSocket实时推送网关技术实践》(* 本文)
其它相关技术文章:
爱奇艺技术团队分享的其它文章:
《 爱奇艺技术分享:轻松诙谐,讲解视频编解码技术的过去、现在和将来》
3、旧方案存在的技术痛点
爱奇艺号是我们内容生态的重要组成,作为前台系统,对用户体验有较高要求,直接影响着创作者的创作热情。
目前,爱奇艺号多个业务场景中用到了WebSocket实时推送技术,包括:
- 1)用户评论:实时的将评论消息推送到浏览器;
- 2)实名认证:合同签署前需要对用户进行实名认证,用户扫描二维码后进入第三方的认证页面,认证完成后异步通知浏览器认证的状态;
- 3)活体识别:类似实名认证,当活体识别完成后,异步将结果通知浏览器。
在实际的业务开发中,我们发现,WebSocket实时推送技术在使用中存在一些问题。
这些问题是:
- 1)首先:WebSocket技术栈不统一,既有基于Netty实现的,也有基于Web容器实现的,给开发和维护带来困难;
- 2)其次:WebSocket实现分散在在各个工程中,与业务系统强耦合,如果有其他业务需要集成WebSocket,面临着重复开发的窘境,浪费成本、效率低下;
- 3)第三:WebSocket是有状态协议的,客户端连接服务器时只和集群中一个节点连接,数据传输过程中也只与这一节点通信。WebSocket集群需要解决会话共享的问题。如果只采用单节点部署,虽然可以避免这一问题,但无法水平扩展支撑更高负载,有单点的风险;
- 4)最后:缺乏监控与报警,虽然可以通过Linux的Socket连接数大致评估WebSocket长连接数,但数字并不准确,也无法得知用户数等具有业务含义的指标数据;无法与现有的微服务监控整合,实现统一监控和报警。
PS:限于篇幅本文不详细介绍WebSocket技术本身,有兴趣可以详读《 WebSocket从入门到精通,半小时就够!》。
4、新方案的技术目标
如上节所示,为了解决旧方案中存在的问题,我们需要实现统一的WebSocket长连接实时推送网关。
这套新的网关需要具备如下特点:
- 1)集中实现长连接管理和推送能力:统一技术栈,将长连接作为基础能力沉淀,便于功能迭代和升级维护;
- 2)与业务解耦:将业务逻辑与长连接通信分离,使业务系统不再关心通信细节,也避免了重复开发,浪费研发成本;
- 3)使用简单:提供HTTP推送通道,方便各种开发语言的接入。业务系统只需要简单的调用,就可以实现数据推送,提升研发效率;
- 4)分布式架构:实现多节点的集群,支持水平扩展应对业务增长带来的挑战;节点宕机不影响服务整体可用性,保证高可靠;
- 5)多端消息同步:允许用户使用多个浏览器或标签页同时登陆在线,保证消息同步发送;
- 6)多维度监控与报警:自定义监控指标与现有微服务监控系统打通,出现问题时可及时报警,保证服务的稳定性。
5、新方案的技术选型
在众多的WebSocket实现中,从性能、扩展性、社区支持等方面考虑,最终选择了Netty。Netty是一个高性能、事件驱动、异步非阻塞的网络通信框架,在许多知名的开源软件中被广泛使用。
PS:如果你对Netty知之甚少,可以详读以下两篇:
WebSocket是有状态的,无法像直接HTTP以集群方式实现负载均衡,长连接建立后即与服务端某个节点保持着会话,因此集群下想要得知会话属于哪个节点有点困难。
解决以上问题一般有两种技术方案:
- 1)一种是使用类似微服务的注册中心来维护全局的会话映射关系;
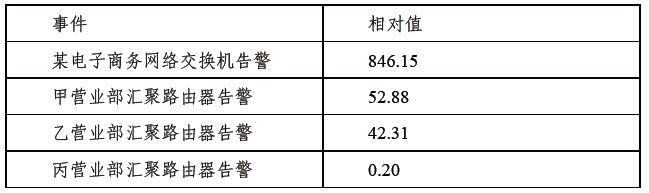
- 2)一种是使用事件广播由各节点自行判断是否持有会话,两种方案对比如下表所示。
WebSocket集群方案:

综合考虑实现成本与集群规模,选择了轻量级的事件广播方案。
实现广播可以选择基于RocketMQ的消息广播、基于Redis的Publish/Subscribe、基于ZooKeeper的通知等方案,其优缺点对比如下表所示。从吞吐量、实时性、持久化、实现难易等方面考虑,最终选择了RocketMQ。
广播的实现方案对比:

6、新方案的实现思路
6.1 系统架构
网关的整体架构如下图所示:

网关的整体流程如下:
1)客户端与网关任一节点握手建立起长连接,节点将其加入到内存维护的长连接队列。客户端定时向服务端发送心跳消息,如果超过设定的时间仍没有收到心跳,则认为客户端与服务端的长连接已断开,服务端会关闭连接,清理内存中的会话。
2)当业务系统需要向客户端推送数据时,通过网关提供的HTTP接口将数据发向网关。
3)网关在接收到推送请求后,将消息写入RocketMQ。
4)网关作为消费者,以广播模式消费消息,所有节点都会接收到消息。
5)节点接收到消息后判断推送的消息目标是否在自己内存中维护的长连接队列里,如果存在则通过长连接推送数据,否则直接忽略。
网关以多节点方式构成集群,每节点负责一部分长连接,可实现负载均衡,当面对海量连接时,也可以通过增加节点的方式分担压力,实现水平扩展。
同时,当节点出现宕机时,客户端会尝试重新与其他节点握手建立长连接,保证服务整体的可用性。
6.2 会话管理
WebSocket长连接建立起来后,会话维护在各节点的内存中。SessionManager组件负责管理会话,内部使用了哈希表维护了UID与UserSession的关系。
UserSession代表用户维度的会话,一个用户可能会同时建立多个长连接,因此UserSession内部同样使用了一个哈希表维护 Channel与ChannelSession的关系。
为了避免用户无限制的创建长连接,UserSession在内部的ChannelSession超过一定数量后,会将最早建立的ChannelSession关闭,减少服务器资源占用。SessionManager、UserSession、ChannelSession的关系如下图所示。
SessionManager组件:

6.3 监控与报警
为了了解集群建立了多少长连接、包含了多少用户,网关提供了基本的监控与报警能力。
网关接入了 Micrometer,将连接数与用户数作为自定义指标暴露,供 Prometheus进行采集,实现了与现有的微服务监控系统打通。
在 Grafana中方便地查看连接数、用户数、JVM、CPU、内存等指标数据,了解网关当前的服务能力与压力。报警规则也可以在Grafana中配置,当数据异常时触发奇信(内部报警平台)报警。
7、新方案的性能压测
压测准备:
- 1)压测选择两台配置为4核16G的虚拟机,分别作为服务器和客户端;
- 2)压测时选择为网关开放了20个端口,同时建立20个客户端;
- 3)每个客户端使用一个服务端端口建立起5万连接,可以同时创建百万个连接。
连接数(百万级)与内存使用情况如下图所示:

给百万个长连接同时发送一条消息,采用单线程发送,服务器发送完成的平均耗时在10s左右,如下图所示。
服务器推送耗时:

一般同一用户同时建立的长连接都在个位数。以10个长连接为例,在并发数600、持续时间120s条件下压测,推送接口的TPS大约在1600+,如下图所示。
长连接10、并发600、持续时间120s的压测数据:

当前的性能指标已满足我们的实际业务场景,可支持未来的业务增长。
8、新方案的实际应用案例
为了更生动的说明优化效果,文章最后,我们也以封面图添加滤镜效果为例,介绍一个爱奇艺号使用新WebSocket网关方案的案例。
爱奇艺号自媒体发表视频时,可选择为封面图添加滤镜效果,引导用户提供提供更优质的封面。
当用户选择一个封面图后,会提交异步的后台处理任务。当异步任务处理完成后,通过WebSocket将不同滤镜效果处理后的图片返回给浏览器,业务场景如下图所示。

从研发效率方面考虑,如果在业务系统中集成WebSocket,至少需要1-2天的开发时间。
如果直接使用新的WebSocket网关的推送能力,只需要简单的接口调用就实现了数据推送,开发时间降低到分钟级别,研发效率大大提高。
从运维成本方面考虑,业务系统不再含有与业务逻辑无关的通信细节,代码的可维护性更强,系统架构变得更加简单,运维成本大大降低。
9、写在最后
WebSocket是目前实现服务端推送的主流技术,恰当使用能够有效提供系统响应能力,提升用户体验。通过WebSocket长连接网关可以快速为系统增加数据推送能力,有效减少运维成本,提高开发效率。
长连接网关的价值在于:
- 1)它封装了WebSocket通信细节,与业务系统解耦,使得长连接网关与业务系统可独立优化迭代,避免重复开发,便于开发与维护;
- 2)网关提供了简单易用的HTTP推送通道,支持多种开发语言接入,便于系统集成和使用;
- 3)网关采用了分布式架构,可以实现服务的水平扩容、负载均衡与高可用;
- 4)网关集成了监控与报警,当系统异常时能及时预警,保证服务的健康和稳定。
目前,新的WebSocket长连接实时网关已在爱奇艺号图片滤镜结果通知、MCN电子签章等多个业务场景中得到应用。
未来还有许多方面需要探索,例如消息的重发与ACK、WebSocket二进制数据的支持、多租户的支持等。
附录:更多相关技术资料
[1] 有关WEB端即时通讯开发:
《 Web端即时通讯技术盘点:短轮询、Comet、Websocket、SSE》
《 SSE技术详解:一种全新的HTML5服务器推送事件技术》
《 Comet技术详解:基于HTTP长连接的Web端实时通信技术》
《 WebSocket详解(一):初步认识WebSocket技术》
《 WebSocket详解(二):技术原理、代码演示和应用案例》
《 WebSocket详解(三):深入WebSocket通信协议细节》
《 WebSocket详解(四):刨根问底HTTP与WebSocket的关系(上篇)》
《 WebSocket详解(五):刨根问底HTTP与WebSocket的关系(下篇)》
《 WebSocket详解(六):刨根问底WebSocket与Socket的关系》
《 LinkedIn的Web端即时通讯实践:实现单机几十万条长连接》
《 Web端即时通讯技术的发展与WebSocket、Socket.io的技术实践》
《 Web端即时通讯安全:跨站点WebSocket劫持漏洞详解(含示例代码)》
《 开源框架Pomelo实践:搭建Web端高性能分布式IM聊天服务器》
《 使用WebSocket和SSE技术实现Web端消息推送》
《 详解Web端通信方式的演进:从Ajax、JSONP 到 SSE、Websocket》
《 MobileIMSDK-Web的网络层框架为何使用的是Socket.io而不是Netty?》
《 理论联系实际:从零理解WebSocket的通信原理、协议格式、安全性》
《 微信小程序中如何使用WebSocket实现长连接(含完整源码)》
《 八问WebSocket协议:为你快速解答WebSocket热门疑问》
《 Web端即时通讯实践干货:如何让你的WebSocket断网重连更快速?》
《 WebSocket硬核入门:200行代码,教你徒手撸一个WebSocket服务器》
>> 更多同类文章 ……
[2] 有关推送技术的文章:
《 一个基于MQTT通信协议的完整Android推送Demo》
《 求教android消息推送:GCM、XMPP、MQTT三种方案的优劣》
《 绝对干货:基于Netty实现海量接入的推送服务技术要点》
《 专访魅族架构师:海量长连接的实时消息推送系统的心得体会》
《 基于WebSocket实现Hybrid移动应用的消息推送实践(含代码示例)》
《 Go语言构建千万级在线的高并发消息推送系统实践(来自360公司)》
《 长连接网关技术专题(四):爱奇艺WebSocket实时推送网关技术实践》
>> 更多同类文章 ……
本文已同步发布于“即时通讯技术圈”公众号。
▲ 本文在公众号上的链接是: 点此进入。同步发布链接是: http://www.52im.net/thread-3539-1-1.html










































 Column Families in BigTable
Column Families in BigTable 















