DB2版本 v9.5.0.4
weblogic版本 10.3
aix版本 6.1.0.0
jdk版本 1.6.64
mysql:Server version: 5.5.32-enterprise-commercial-advanced MySQL Enterprise Server
Linux上jdk版本:sun:jdk1.6.0_37
linux上无法使用jps、jstat等工具:
执行这个命令即可使用:
export PATH=/usr/java/jdk1.6.0_37/bin:$PATH
weblogic启动脚本:
C:\bea\user_projects\domains\mapsDomain\bin\startWebLogic.cmd
C:\bea\user_projects\domains\mapsDomain\servers\AdminServer
flex编辑工具
C:\Program Files\Adobe\Flex Builder 3 Plug-in
D:\MyEclipse 6.0\eclipse
flex project
会自动编译生成*.swf
生成完swf文件以后,将*.html和*.swf拷贝到
maps_mng\WebContent\com\cup\maps\portal\jpf\flex
<2010-6-4 上午10时14分06秒 CST> <Warning> <JDBC> <BEA-001129> <Received exceptio
n while creating connection for pool "mapswebDS": [jcc][t4][2043][11550][3.50.15
2] 异常 java.net.ConnectException:打开端口 60,000 上服务器 /172.17.252.84 的套
接字时出错,消息为:Connection refused: connect。 ERRORCODE=-4499, SQLSTATE=0800
1>
com.cup.common.dao.util.PersistenceException: Unable to resolve 'jdbc.glmondb'. Resolved 'jdbc'; - nested throwable: (javax.naming.NameNotFoundException: Unable to resolve 'jdbc.glmondb'. Resolved 'jdbc'; remaining name 'glmondb')找不到数据源.
原因:没配数据源
URL:jdbc:db2://172.17.252.151:60001/glmondb:currentSchema=GL_MONDB;
Driver Class Name:com.ibm.db2.jcc.DB2Driver
user=gl_monap
portNumber=60001
databaseName=glmondb
serverName=172.17.252.151
Password:glmonap
JNDI Name: jdbc/glmondb
log位置:
D:\bea\user_projects\domains\base_domain\appLog\cups_maps.log
flex项目改好的swf和jsp文件需要copy到如下目录:
maps_mng\WebContent\com\cup\maps\portal\jpf\monitor\
然后必须要ant build项目maps_mng,然后重启weblogic才可以显示改动地方。
ant build 脚本位置:
maps_mng\script\build.xml
那cvs上传的文件应该是swf还是我改的mxml文件
都上传,swf是编译出来的目标文件,mxml是源文件
公共参数管理代码流程:
入口:
CommonParaSyncMainOperBean.operEtl(String paraCom,Integer syncBatNo,Map<String, String> jmsMap)
参数:paraCom 当前类型所包含的主题域
syncBatNo 批次号
jmsMap jms传递的map,包含参数类型和是否强制同步信息
syncService.syncPara(Integer.toString(syncBatNo), mainPt.getTblId(), userId, mainTableData);(CommonParaSyncServiceBean.syncPara)做了下面几件事:
1、通过同步批次号、表ID、用户ID、参数数据集合同步参数数据
2、如果没有任务(para_task),则创建;如果任务和正式表存在,进行任务状态校验
3、如果临时表中有可修改的、显示在页面上的字段,则将这些字段值复制到etlData中
4、ETL数据覆盖到TEMP
5、记载审计日志
6、更新Etl表,设置ETL表的sync_st=1
本主题域从ETL同步后是否可编辑,即可以在多渠道进行维护部分字段,如果不可以在多渠道维护,那么自动生效
CommonParaSyncMainOperBean.activateSubject
做了几件事:
对需要自动生效的任务:
1、将para_task状态改为“复核通过”
2、syncService.activateTask(task);(CommonParaSyncServiceBean.activateTask)将状态改为5(生效中),设置一些ts和userid,做一些检查;forwardOthers()-》sendQueue()发送jms(类型是:ParaConstants.JMS_SUB_SYS_SYNC-JMS子系统同步)
3、ParameterEventBean.process()接受到这个jms消息开始处理:
sucess = syncExecute.activate(requestId);
参数同步生效方法
1.同步临时表数据至正式表
2.同步成功后,执行同步至其他子系统操作
4、if(sucess==true)并且该主题域是可以自动生效自动关闭的(entry_wizd_in=2),
那么设置任务状态是:"S", "同步成功",然后执行关闭任务:syncService.closeTask(task);(CommonParaSyncServiceBean.closeTask(ParaTask task))
备份一张表(ixf为二进制,del为字符型)
db2 "export to ./backup/ETL_MAMGM_TRANS_CHNL_CD.ixf of ixf select * from ETL_MAMGM_TRANS_CHNL_CD"
覆盖一张表
db2 "import from /maps/usr/ma_mgmdb/backup/ETL/ETL_MAMGM_TRANS_CHNL_CD.ixf of ixf insert into ETL_MAMGM_TRANS_CHNL_CD"
查询schema下所有表
list tables for schema "ZHAOWM"
select * from table fetch first 10 rows only;
select * from table where v_time = timestamp('2008-01-01-00.00.01.000000');
weblogic配置data sources时提示jdbc找不到。
解决:要把d2cc.jar拷贝到domain\lib下。
myeclipse有时会报找不到某一类的错误,但是实际上是能找到的。
解决:clean project
修改好的swf文件要放在这里:
\maps_mng\WebContent\com\cup\maps\portal\jpf\monitor\maps_monitor.swf
取路径的最后文件名并排序
sed 's/.*\///;s/.*\\//' 1 | sort >2
用室内CVS上的代码与研究院上的代码比较,按时间降序
PARA_SUB_AREA_INF
ENTRY_WIZD_IN: 该字段在java中使用。
0: 参数维护页面上有“任务创建”按钮;公参任务自动生效。
1: 参数维护页面上有“任务创建”按钮;公参任务执行在“录入中”状态停住。
2: 参数维护页面上没有“任务创建”按钮,只有“查询”;公参任务自动生效。
无论0还是1,在页面上手工创建任务时,都需要手工经历录入中,待复核,复核通过,同步正式表,同步成功等状态。
BAT_EFF_IN: 0:只读 1:可以新增、修改。 该字段在页面上使用
subject.as中存在该字段,如果0的话,“任务创建”按钮还是不存在的。如果是1的话,“任务创建”按钮会在的。
是否同步子系统:
para_tbl_attr:
ma_subsys_bmp 10位位图
每位顺序代表:联机(第一位),批量(第二位 ),通讯,管理,健康,NASA(第6位)
PUB_PARA_CD 该字段在公参同步时使用,当子表的该字段值为空时,该子表不做同步处理;当子表的该字段值为01,即有值时,该子表会同步数据。
表是否支持插入,更新,删除,查询
para_tbl_attr:
main_tp 4位 0表示可以做,1表示不可以做
para_tbl_attr的ini_exp字段,是页面初始化使用的字段
具体使用在:TableForm.as中(引用了ParaTable.as的initExp值,该值对应着上述字段)
字段
para_fld_attr:
readonly_bmp 两位,分别对应“新增/修改” 0表示具有这个权限,即具有新增或修改权限,1代表不具有该权限
Form_in: 一位, 1 表示 在创建参数修改任务中,在创建参数新增任务中,会显示这个字段; 0 表示 页面中不显示这个字段
SHOW_TP: 一位: 0 表示使用默认值,在CommonSyncCommand.copyUpdatableFields()中,会将TBL_MAMGM_PARA_FLD_ATTR表中配置的dft_value值,覆盖到etl表中。
LIST_IN: 1 表示在检索结果中,会显示这个字段
INQ_FLD_IN 1 表示在参数维护页面,检索时显示的条件项。 0表示该字段不在检索条件里。
COMP_TP 00 表示一般单行文字输入框, 01 表示下拉框 11 表示可以输入的下拉框 04 日期 07 时间 06 多行文本框
DRDL_VAL_TBL_NM 下拉框里面选择的内容。对应于TBL_MAMGM_DRDL_CFG表。
fld_data_tp:00:string 01:INT 02:timestamp 03:float 04:BIGDECIMAL
DFT_VALUE: 页面上新建参数任务时,该字段的默认值。
所有表的字段都会在TBL_MAMGM_PARA_FLD_ATTR中,但是并不是所有SHOW_TP为0的字段,都会被覆盖默认值,必须满足下面条件:
1、FORM_IN=1,该字段在页面上显示
2、READONLY_BMP = 10或00 (第二位是0) ,该字段可以修改
3、SHOW_TP为0
4、tmp表在etl表数据覆盖之前是没有值的。
任务提示
页面:todolist.mxml
页面初始化:ParameterFlexFacade。countTaskBySubject()。另:那个URL是在renderCountTaskList(taskGroup)方法中定义
点每个主题域链接:初始化中的链接,是取缓存access_inf表中的url。
这个表里的url,对技术参数而言是类似于parameter.jsp?subject=X;---》parameter.mxml-----> <taskView:Start> ----> 它指向Start.mxml---> 在parameter.mxml里有一个初始执行函数init()---》 调用执行 main.as里面的init()函数-----》调用startPage.init()---->调用Start.as里面的init()函数
进入主题域的参数维护页面:
1、“任务批次状态”、“任务生效状态”--->overview.mxml
"录入中"、“待复核”、“复核通过”、“复核不通过”--->ParameterFlexFacade。countTaskByStatus(),保存在response中的batchStatusCountList属性里
2、“同步正式表成功”、“同步正式表失败”。。。。--->保存在response中的effectStatusCountList属性里。
“同步子系统成功”、“同步子系统失败”、“部分同步共享内存” 三个按钮是否存在,是在ParameterServiceBean。countTaskByStatus(String subjectId)里面做了判断。因为有些表不需要同步子系统,另外一些表不需要同步共享内存。
3、点诸如“录入中”“待复核”等链接。是在overview.as里initQueryButtons()方法中设置了一个监听器,监听函数就是queryTask(),它又调用了ParameterFlexFacade.queryTaskByStatus()方法。
4、至于随之变化的底部的按钮,是在初始化时就保存好的。在点击诸如“录入中”“待复核”等链接并调用了
queryTask(),这个函数会调用initActionButtons()函数,会将初始化保存好的状态信息与各个按钮对应的显示在底部。
5、底部的按钮的action也是在初始化时就设置好的。由ParameterFlexFacade静态调用TaskStatusHelper.init(),这个方法将每个状态对应有多少动作按钮都设置好。会保存在response的statusMap属性里。
6、response中的actionMap属性保存的是涉及流程的操作类型,供之后处理,比如:删除,提交,复核通过,复核不通过等等。
7、switchPage在flex/ParamNew/main.as中定义,函数switchPage(event : MapsEvent)中执行,参数只有三种:OVERVIEW、PARA_QUERY、PARA_EDIT
8、“检索”按钮
9、“创建参数修改任务”和“创建参数删除任务”调用ParameterFlexFacade.queryProdPara(),查询主表和子表相关内容。
10、“创建参数新增任务”不需要查询记录。
11、任务状态“录入中”、“待复核”、“复核通过”等链接下面的按钮如“任务提交”、“任务查看”、“任务信息”、“任务修改”等是保存在response的statusMap里面,
且在ParameterFlexFacade.getGrantedActionMap()函数里面设置。
查询按钮是所有任务状态链接下都有的按钮。
"创建参数新增任务"\"创建参数修改任务"\"创建参数删除任务"按钮在Query.mxml页面中,点击按钮的触发的函数分别是gotoCreateInsert()、gotoCreateUpdate()、gotoCreateDelete()。
对于修改任务gotoCreateUpdate(在Query.as中):
1、校验是否选中一条记录:getSelectedRecId
2、执行checkOper("U"),调用checkParaOperatable(mainTable.tblId, getSelectedRecId())
3、执行回调函数checkParaOperatableHandler -》 getSwitchEvent("U",recid,eventid)-> ParamNew/main.as中定义的事件switchPage,traget=ParaConstants.PAGE_PARA_FORM
4、mainFrame.selectedIndex = 2;paraEdit.initParaPage(event.data);意思是页面展示Edit.mxml,并且执行Edit.as的initParaPage函数,函数参数是ParaUtil种定义的switchEvent的data
参数中包括target=“PARA_EDIT” type=“U” recId eventId这四个参数,
5、该initParaPage函数首先执行ParameterFlexFacade.queryProdPara()
6、执行回调函数queryParaHandler() -> shown() 多表的要加上多表 -》 showForm();表数据引入 -> reloadButtons()置入按钮
获取一开始的处理操作,即参数管理中每个表的初始进入页面中“查询”、“任务创建”。
这两个按钮是否存在的判断在:
ParameterFlexFacade.blankGrantedActionList()
1、该用户是否有这两个按钮的权限
2、该主题域是否具有可以查询,可以任务创建的功能。(TBL_MAMGM_PARA_SUB_AREA_INF.ENTRY_WIZD_IN)
3、点“任务创建”后,“创建参数新增任务”“创建参数修改任务”“创建参数删除任务”“查看参数”是由TBL_MAMGM_PARA_TBL_ATTR.MAIN_TP字段控制。位图1111表示上述四个按钮全都存在,0000表示上述四个按钮全不存在。
tmp表数据怎么来的?
1、从etl表读数据到一个rowset中
2、增加一些时间和人的信息
3、给特殊情况的字段赋默认值
商户路由表为什么单拿出来?
商户路由的etl表与tmp表表名不一致。tmp表和tbl表的表名一致。公参同步是将ETL_MAMGM_SETTLE_TRE_MCHNT_INF表(财税库银商户表,该表从商户平台来,且由商户平台发起同步命令)
的一部分内容同步到tbl_mamgm_mchnt_rout_det,另一部分内容同步到tbl_mamgm_mchnt_rout_inf(该表是主表)。
这两个表公参时特殊处理,不走优化后的公参代码。
卡号转换表没有etl表?
不是所有tmp,tbl表都有对应的etl表,etl是给公参同步时,外系统用的
公参同步的web services接口在:
BatchSynchResultNotifyImpl。notify()
这个方法调用EJB,EJB的名字是CommonParaJmsService,它又对应了CommonParaJmsServiceBean。sendJmsRequester()来处理
查看目录下文件或文件夹得大小,并按照从大到小排序
du -sg * |sort -nr
在VI中,将字符串str1替换成str2
:g/str1/s//str2/g
aix中vi一文件,删除^M符号,执行如下命令:
:%s/^V^M//
:%s/^M//
^V和^M指的是Ctrl+V和Ctrl+M
公参同步任务是如何执行的?
商户平台使用web services访问接口BatchSynchResultNotifyService,而这个类BatchSynchResultNotifyImpl又用ejb的形式调用了local接口CommonParaJmsService。并由CommonParaJmsServiceBean.sendJmsRequester()
通过CommonParaSyncRequester给JMS服务队列发送消息,MsgProperty是"common_para_sync"。
CommonParaSyncMDB 通过JMS消息队列 接收到这个消息后,把ObjectMessage转发给CommonParaSyncEventBean,由ObjectMessage中的MsgProperty决定,把ObjectMessage中包含的两个参数,一是参数类型,一是批次号。
发给CommonParaSyncMainOperBean。operEtl来处理
1、正在同步的公参批次,如果由另外一页面发起强制同步的话,很容易报911,表锁问题;原因在改ETL表的状态为1时与MERGE语句使用了相同的表。
2、公参成功后,查看的是紧接着的同参数类型的一个批次是否成功,如果是待同步,则执行,如果是成功的就不会往下做了。隔着的那些待同步批次不会执行的。
公共参数管理页面对应的jsp:
/com/cup/maps/portal/jpf/flex/CommonParaQuery.jsp
“重新同步”命令调用ParameterFlexFacade.reSyncCommonPara(String batNo,String paraTp,boolean force)函数。
该函数调用 CommonParaJmsService.sendJmsRequesterForce() 发送jms消息,(跟商户平台的公参同步类似,不过它走了另外一个函数sendJmsRequester)
“重新同步”与“强制同步”均要走同步正式表和生效接口,它们的不同在于:
1、“强制同步”无视 还小的批次号,可以绕过之前失败的批次做同步。
2、如果该批次同步成功,公参任务表的最终状态会改成“3-强制同步成功”
研究院-电话支付-CVS
:pserver:leishen@172.17.238.150:2401/cvsout
Module:tams
checkout某一标签tag的cvs文件:
cvs co -r branch_tipsp_codemerge_20120530 isvr_mgm
查看标签语句
cvs status -v
ant在编译指定文件夹中的java类时,会将该java类引用到的所有java类同时编译。
在打war时就可以把引用到的java生成的class文件一起打入war包中。
db2在某一列创建索引时会让你选择该列是否设置成unique。
对于显示的查询结果,如果要有水平的滚动条,需要修改这个dataGrid的属性,
增加一个:horizontalScrollPolicy="auto"
商户同步的参数中,也就下面表需要编辑。其它的都是自动生效的
卡bin 01010601 TBL_MAMGM_BIN+TBL_MAMGM_BIN_REGION 0000000000
机构信息(成员机构静态信息表) 01010101 TBL_MAMGM_INS_STATIC_INF 0000000000
商户类型表 01071101 TBL_MAMGM_MCHNT_TP 0000000000
交易代码表 01071401 TBL_MAMGM_TRANS_ID 0100000000
行业机构静态信息表:服务提供机构、渠道接入机构、行业商户
industry_ins_static_inf
成员机构信息表:多渠道平台、银联总分公司、转接机构、发卡机构、收单机构
ins_static_inf
商户静态信息表:直连终端商户、渠道接入机构商户、服务提供机构商户、行业商户、虚拟商户
mchnt_static_inf
终端静态信息表:直连POS、ATM、电话终端、各种虚拟终端
term_static_inf
对于“参数同步”这个交易,tbl_mamgm_para_tbl_attr中配置了两条记录如下:
TBL_CDTBL_NMTBL_NM_CNMA_SUBSYS_BMPSUB_CDENTRY_WIZD_SEQ
0803010208030102参数同步到数据库(返回)00010000000803011
0803010108030101参数同步到数据库(发送)11000000000803010
OnlCommon.getSTMGBySubCd(subjectId,subsysId);
该函数取ENTRY_WIZD_SEQ=0的记录,由subsysId(是BAT、ONL)来得到联机或者批量的默认节点
OnlCommon.getRTMG(subjectId);
该函数取管理的默认节点(节点的意思是tbl_maps_gfs_deploy_inf这张表的一条记录,包括ip,port,openid等信息)
批量应用重启:
taskcom stop all
停应用
MPubTask &
启动
管理数据库停止后,再开启,不影响管理应用继续使用,管理应用无需重启即可。
jdbc:db2://172.17.252.84:60032/mamgmdb
是ma_onldb/ma_onl用户建的。端口60032是这个用户在/etc/services文件设置好的。
ma_onldb@/etc>cat /etc/services |grep 60032
DB2_ma_onldb 60032/tcp
多渠道管理有5个web service 接口,页面上可以测试。CommonParaJmsServiceBean类是第一层处理接口:
1、公参管理
http://172.17.252.85:4866/maps_service/BatchSynchResultNotifyService?wsdl
http://172.17.252.63:7001/csb/shcenter/BillDomain/MultiAcquiringSystem/ParamSyncNotiry/ParamSyncNotiryProxy?wsdl
http://172.17.248.158:40423/maps_service/BatchSynchResultNotifyService?wsdl
http://172.17.248.40:4867/maps_service/BatchSynchResultNotifyService?wsdl
2、改变交易规则状态交易(changeFilterAppInf)
改变指定商户的交易状态(changeMchntTransSt)
改变指定终端的交易状态(changeTermTransSt)
根据任务事件号查询的事件状态(queryTransSt)
http://172.17.252.85:4866/maps_service/TransStateAndRuleSwtService
3、行业机构状态查询
http://172.17.248.74:8888/MapsServicePortal/IndustryInsStateActionService?wsdl
4、bps接口
http://172.17.248.74:8888/MapsServicePortal/BpsServiceImplService?wsdl
对应csb地址:
http://172.17.252.63:7001/csb/shcenter/BillDomain/MultiAcquiringSystem/BpsServiceImplService/BpsServiceImplServiceProxy?wsdl
5、多渠道交易状态查询接口(过滤应用信息表状态、商户状态、终端状态查询) 未上线
http://172.17.248.74:8888/MapsServicePortal/TransStateActionService?wsdl
6、供mtqj调用接口
http://172.17.248.74:11000/MapsServicePortal/MjcCallActionService?wsdl
7、手工交易
http://172.17.248.74:11000/MapsServicePortal/MjcCallActionService?wsdl
MTQJ的webservice地址
http://172.17.252.88:10000/mjc/MtqWebService?wsdl
行综平台管理系统目前有1个web service 接口
csb地址:http://172.17.252.63:7001/csb/shcenter/BillDomain/IntegratedServicePlatformForIndustry/IsvrBatchParaSynchNotifyService/IsvrBatchParaSynchNotifyServiceProxy
对应的行综环境:http://172.17.248.188:7004/IsvrServicePortal/BatchParaSynchNotifyService?wsdl
csb地址:
http://172.17.252.63:7001/sbconsole
用户名/密码:weblogic/weblogic
多渠道在Projects->csb->shcenter->MultiAcquiringSystem
行综在Projects->csb->shcenter->IntegratedServicePlatformForIndustry
通讯重启:
1、hgcom1/nasa/bin/reload_cfg 100 300 0 shutdown
2、mtqshutdown
3、mtqstartup
4、hgcom1/nasa/bin/nasad
5、shmadmin
5.1--- h
5.2--- create COMALL
5.3--- q
6、reload_cfg 100 300 0 start
7、ml
8、ps -ef |grep $USER
用户管理平台(权限相关):
系统权限导入:只会更新已有数据+插入新增数据。不会删除系统已有数据。
EJB3里面
@TransactionAttribute(TransactionAttributeType.NEVER)的函数中,调用了
@TransactionAttribute(TransactionAttributeType.REQUIRES_NEW)的函数,子函数的事务不起作用,无法回滚
bytes[]类型的参数同步后的数据与etl表原始数据不一致,最后部分的00 00 00内容被截断了,需要修复。
修改:SqlUtil.java下面这行
fieldValue = StringUtils.defaultString(new String(rowset.getBytes(fieldCount))); //byte[]的类型特殊处理
管理系统使用DBPM
自己开发一应用程序,用modifyPasswd.sh执行,读取config.properties配置的DBPM服务器地址,通过socket的方式获得数据库密码。
然后调用调用WLST工具类,修改Domain中的JDBC数据源中设置的密码。
然后启动domain。
下面5个交易由之前的同步交易,改成异步交易,发送流程是:首先管理发MTQ消息给联机1,联机1通过通讯发给CUPS,cups做完后会返回结果给联机,但是由于通讯是负载均衡的,所以有可能发给了联机2,联机2通过异步邮箱134, 发送给管理,管理得到134邮箱的内容后,会更新联机交易日志表(manage_trans_log),此时管理端仍然在轮询联机日志表,找到状态是1(收到事件请求报文),2(已经事件处理完毕),99(出错)的对应event_id记录后,返回前台成功或出错信息,如果超过60秒,仍然没有找到,那么返回前台超时标志。
签到:多渠道向cups签到,激活状态。
签退:多渠道向cups签退。
申请重置密钥:通知cups,让cups给成员机构发送密钥。
重置密钥下发:通知行业机构重置密钥
线路测试:通知cups,让cups给成员/行业机构发送测试交易。
终端签到:
先去查联机的终端静态表,如果状态为1-冻结,直接报错,如果状态为0,接着校验交易位图等,最后更新联机终端动态表状态为0-开启。
终端状态启用冻结
只更新联机的终端静态表
查找主题域/表对应的下拉框的内容:
select t5.sub_cd,t5.SUB_NM_CN,t4.TBL_CD,t4.TBL_NM_CN,t1.*
from TBL_MAMGM_DRDL_ITEM_DEF t1,TBL_MAMGM_DRDL_CFG t2,
tbl_mamgm_para_fld_attr t3,tbl_mamgm_para_tbl_attr t4,TBL_MAMGM_PARA_SUB_AREA_INF t5
where t1.DRDL_ID = t2.DRDL_ID and t2.DRDL_NM = t3.DRDL_VAL_TBL_NM
and t3.tbl_cd = t4.TBL_Cd and t4.SUB_CD = t5.SUB_CD
and t4.TBL_CD = '07010301'
and t5.SUB_CD = '070103';
公参同步用到的一系列表:
select * from TBL_MAMGM_PARA_SYNC_TASK;
select * from TBL_MAMGM_PARA_TASK;
select * from TBL_MAMGM_ACCESS_INF;
select * from TBL_MAMGM_PARA_SUB_AREA_INF;
select * from TBL_MAMGM_PARA_TBL_ATTR;
select * from TBL_MAMGM_PARA_FLD_ATTR;
取得当前时间:
select current timestamp from (values 1);
取得sequence的下一取值:(两种方法)
select nextval for sqn_mamgm_ei from (values 1);
select nextval for sqn_mamgm_ei from sysibm.dual;
values nextval for sqn_mamgm_ei;
设置管理数据库的REC_ID对应的sequence下一取值为108000003
alter sequence ma_mgmdb.sqn_mamgm_ri restart with 8000003
CHAR型转INTEGER
select CAST(INS_ID_CD AS INTEGER) max from etl_mamgm_ins_static_inf;
TBL_MAMGM_PARA_FLD_ATTR表中配置的字段如果少于TBL表中的字段,在创建新增参数任务、创建修改参数任务时都会报错。
具体表现为:
1、关闭记录时tmp记录删不掉。
2、修改参数任务时也没显示的字段值不对应。
下拉框配置表TBL_MAMGM_DRDL_CFG:
DRDL_TP: 2 表示用sql执行的结果,进入页面时,读数据库一次下拉框的代码
DRDL_REMARK:sql语句
SHOW_KEY_IN: 0 表示格式像“代码中文名称” 1 表示格式像“代码-代码中文名称”
DRDL_SORT_TP: 1
JMS server参数配置:
Messages Maximum: -1。 JMS消息队列最大值。设为-1表示没有限制,容易引起内存不足。
Maximum Message Size:2147483647 The maximum number of bytes allowed in individual messages on this JMS server
虚拟终端确定信息表TBL_MAMGM_VIRTUAL_TERM_DET的ETL表比TBL表多一个字段CUP_BRANCH_INS_ID_CD,此时无论公参优化前后,该表都可以同步成功。
但是如果公参同步失败,需要页面上人工操作,走参数维护流程,那么将出错,
出错情况和上面所讲的TBL_MAMGM_PARA_FLD_ATTR表中配置的字段如果少于TBL表中的字段情况相同。
目前多渠道代码的问题缺陷错误:
1、TBL_MAMGM_DRDL_ITEM_DEF.drdl_id=9254名称写错:“本平手工台录入”
2、商户黑名单etl_MAMGM_MCHNT_BLKBILL没有sync_bat_no字段,无法做公参同步,报错。好在这个表联机批量都不用。
3、中奖奖项限制配置表TBL_MAMGM_PRIZE_LIMIT_CFG该表没有ETL表,但是该表是子表且pub_para_cd值为空,该表不做同步处理,公参同步时不报错。
4、子表被删除了,在页面中通过主表查询子表内容还是能看到。
5、下拉框表TBL_MAMGM_DRDL_CFG中,WINUSEFLG有2个。
java的substring问题
String ss = "1234567890123456";
System.out.println(ss.substring(1,2));//2
System.out.println(ss.substring(2,4));//34
System.out.println(ss.substring(5,8));//678
在参数删除时,不对字段进行校验
ParameterFlexFacade.checkParaByValidators()根据Validator进行校验
新建“链路信息表”记录时,输入“链路编号”字段,只有两位,保存到TMP表以后,该字段变成13位,原因:
TBL_MAMGM_PARA_TBL_ATTR配置表时,BEFORE_INSERT_EXP字段配置了处理代码,如下:
import com.cup.maps.parameter.util.*;
String s=map.get("LINE_NO"); if (s.length()==2)
{ map.put("LINE_NO",map.get("ACCESS_INS_ID_CD")+s);
ParaExpressions.checkExistRecordForTask("01100701", map); }
此外该表在TBL_MAMGM_PARA_VFY中有很多校验信息,具体有15条,列出如下:
无效的接入系统标识!
链路编号C开头本方监听端口应为0
链路编号A开头本方监听端口不为0
链路编号C开头对方监听端口不为0
链路编号A开头对方监听端口应为0
本方监听端口输入错误!
对方监听端口输入错误!
登录用户不能为空
登录密码不能为空
短信窗口大小不能为空
短信源发序列号不能为空
短信接入角色不能为空
检测时间间隔不能为空
单条链路超时时间不能为空
接入模式 0001 /0006,才能选支持
在管理应用上部mtq时,除了常规参数配置外,还要保证/glb/mtq/etc/mtq.ini文件中
SHMKEY_MB和MSGKEY这两个参数,在应用主机上与其他用户的mtq配置的不重复。
用winrar软件更新jar文件中的一个class,压缩进去,生成的新的jar文件,仍然可以像之前一样引用,且更新的地方也会生效。
假如程序A.java引用了XX.JAR包中的B.java,且B.java又引用了XXX.JAR中的内容。那么:
1、把B.java打成XX.jar包的操作,不应该将XXX.JAR打入XX.JAR中
2、在javac A.java时,classpath应该只包括XX.jar和.
3、在执行java A.java时,应该将XX.JAR和XXX.jar均包进classpath中。
例子Testjar.java中引用了tools.jar的XmlRead类,而XmlRead类又引用了dom4j-1.5-rc1.jar包的内容,下面是正确编译和执行的语句:
D:\>javac -classpath "d:/tools.jar" Testjar.java
D:\>java -classpath ".;d:/tools.jar;D:/workspace/TOOLS/lib/dom4j-1.5-rc1.jar" Testjar
下面两个sql,第一个取全部字段,走全表扫描,第二个sql由于取主键,走索引。两边取出的值不一定一样。
select * from ETL_MAMGM_TERM_STATIC_INF where sync_bat_no = 999 fetch first 1000 rows only with ur;
select term_id,mchnt_cd,sync_bat_no from ETL_MAMGM_TERM_STATIC_INF where sync_bat_no = 999 fetch first 1000 rows only with ur;
商户折扣信息表,中奖等级表,中奖基本表等按照规划是营销平台通过公参平台公参同步到多渠道,但是营销平台没有这些接口,
多渠道本身也没有用这些表。
商户黑名单和卡号黑名单这两张表是在商户维护的吗?
答:是风险平台维护。但现在他们还没有作
mtq.ini中有:
BEGIN GROUP
31 172.17.252.87 8113 20 S
END GROUP
mtq重启以后,端口8113会被监听
netstat -an|grep 8113
查看当前用户的进程
ps -ef |grep mtq|grep $USER
BEGIN GROUP里面的配置的S要大写。
0 172.17.248.57 8100 20 S这个0的行是什么含义?
异步邮箱组连接数及发送报文个数:
mtqmng list或者ml(需要创建别名alias ml="mtqmng list")
su - iisp1onl
iisp1onl@/iisp/usr/iisp1onl>db2 connect to ISMGMDB user iisp1db using iisp1db
db2 reorg table ma_mgmdb.TBL_MAMGM_MSG_FMT_CONV_MTO
多渠道管理回归数据库82
telnet 172.17.252.82
su - ma_mgmdb
db2 list db directory
/maps/usr/ma_mgmdb>db2 connect to GMAMGMDB user ma_mgmdb using ma_mgmdb
db2 reorg table ma_mgmdb.etl_mamgm_mchnt_static_inf
db2 reorg table ma_mgmdb.tmp_mamgm_mchnt_static_inf
db2 reorg table ma_mgmdb.tbl_mamgm_mchnt_static_inf
查询db2错误代码
db2 ? sql-30082|more
82联机回归数据库,发生668错误
maps/usr/ma_mgmdb>db2 connect to GMAONLDB user ma_onldb using ma_onldb
db2 runstats on table ma_mgmdb.TBL_MAMGM_AUDIT_LOG2
/maps/usr/ma_mgmdb>db2 reorg table TBL_MAONL_MCHNT_STATIC_INF
获取前台flex发送到后台的值
OnlCommon.getSentFlied(String subjectId, Map<String, String> map)
根据主题域ID取到参数表对象列表
OnlCommon.java List<ParaTable> getParaTable(String subjectId)
过滤应用信息的下拉内容来源于业务参数(fml域转换配置信息表),
成员机构静态信息表在页面上做“创建参数修改任务”后,复核通过,会在同步正式表成功那里卡住,
然后在“参数刷新-参数同步到共享内存”页面做了参数刷新以后,回到参数管理页面,该参数已在同步成功栏内。
刷新共享内存及更新para_task状态的地方在:SyncExecuteBean.refreshSchemeStatus(Map<String, String> map)
这里面maps的内容是子系统subsysCd和内存编号zoneId
这个函数做了两件事:
1、更新TBL_MAMGM_PARA_TASK_SYNCSHM_STATUS状态为4-成功
2、更新TBL_MAMGM_PARA_TASK为S-同步成功或者A-部分同步到共享内存成功
同步子系统的地方:
ParaSyncServiceBean。sendMsg(ParaTask batch, Map<String, String> map)
需要的内容包括:batch里面的eventid,map里面的子系统名称、多个表名
db2取当前时间
SELECT current date FROM SYSIBM.DUAL;--取得当前年月日
SELECT current time FROM SYSIBM.DUAL;--取得当前时分秒
SELECT current timestamp FROM SYSIBM.DUAL;--取得当前年月日时分秒
select current timestamp,microsecond(current timestamp) from SYSIBM.DUAL;
select 1,to_char(current timestamp,'yyyymmdd') from sysibm.dual;--日期格式
axis,unix取当前时间
dateWed Mar 9 11:22:07 GMT+08:00 2011
date +%Y2011
date +%y11
date +%m03
date +%M22
date +%d09
date +%D03/09/11
date +%S07
date +%s1299669809
错误:
DB2 SQL error: SQLCODE: -20154, SQLSTATE: 23513, SQLERRMC: MA_MGMDB.VIW_MAMGM_AUDIT_LOG;2
sqlcode-20154原因:指定的视图包含一个UNION ALL查询
1、不符合任何基础基表的检查约束。
2、满足所有多个基础基表检查约束。
解释:视图VIW_MAMGM_AUDIT_LOG是由TBL_MAMGM_AUDIT_LOG1和TBL_MAMGM_AUDIT_LOG2这两个表组成的。在这两张表的create时,
没有增加CHECK (SUBMIT_MON BETWEEN 1 and 6)和 CHECK (SUBMIT_MON BETWEEN 7 and 12)语句,导致在insert viw时,db2不知道要插入哪张表。
db2 修改字段属性
alter table tmp_maps_gfs_fmt_grp alter trantype set data type char(6);
select current schema from sysibm.dual
db2 values current schema
菜单的顺序是跟access_inf表的event_id相关的。只有event_id相同的情况下,才看access_cd.
unix vi命令
01 G 移至最后一行行首
02 nG 移至第n行行首
03 n+ 下移n行,行首
04 n- 上移n行,行首
05 n$ 下移n行(1表示本行),行尾
06 0 所在行行首
07 $ 所在行行尾
08 ^ 所在行首字母
09 h,j,k,l 左移,下移,上移,右移
10 H 当前屏幕首行行首
11 M 屏幕显示文件的中间行行首
12 L 当前屏幕最底行行首
管理系统里面不常用的两个sequence:
TBL_MAMGM_FLOW_CD的主键Sequence
public static final String TBL_MAMGM_FLOW_CD_KEY="sqn_mamgm_fck";
审计日志sequence
public static final String AUDITLOG_SEQUENCE = "sqn_mamgm_aui";
db2中select语句最多可以选择1012个字段,超过以后就会报sqlcode=840的错误。说选择的列太多。
ultraedit每行最多显示4096个字符
感觉db2的sql长度没啥限制一个18k的select语句也是可以被执行的。
如果select出来一个字段没有值,那么rs.getString()取出来的值是空:"",并不是null
我们的页面根本没有对用户的权限做限制,比如:
在url上输入:https://172.17.252.85:8889/maps/com/cup/maps/portal/jpf/flex/cacheRefresh.jsp
然后再登录的地方输入分公司的用户名和密码
页面仍然可以显示,并且刷新的功能也能完成。
查看aix的版本
oslevel
将System.out.println输出到文件中。
OutputStream os = new FileOutputStream("d:/output.txt");
PrintStream p = new PrintStream(os);
System.setOut(p);
System.out.println("ee");
从jar文件中读取资源文件
//方法一,直接读取该文件的每行内容
BufferedReader br1 = new BufferedReader(new InputStreamReader(
((ReadXmlFileFromJar.this.getClass().getResourceAsStream("1.txt")))));
String s1;
while((s1=br1.readLine())!=null)
System.out.println(s1);
//方法二,读取xml文件内容后组装成document对象
BufferedReader br = new BufferedReader(
new InputStreamReader(((ReadXmlFileFromJar.this.getClass()
.getResourceAsStream("1.xml")))));
String s;
while ((s = br.readLine()) != null)
System.out.println(s);
SAXReader saxReader = new SAXReader();
Document document;
try {
document = saxReader.read(ReadXmlFileFromJar.this.getClass()
.getResourceAsStream("1.txt"));
Element incomingForm = document.getRootElement();
String ss = document.asXML().toString();
System.out.println("ss=" + ss);
} catch (DocumentException e) {
e.printStackTrace();
}
从jar中读取资源文件
1、方法一
URL fileURL=this.getClass().getResource("/resource/res.txt");
System.out.println(fileURL.getFile()); //file:/C:/ResourceJar.jar!/resource/res.txt
2、方法二
InputStream is=this.getClass().getResourceAsStream("/resource/res.txt");
BufferedReader br=new BufferedReader(new InputStreamReader(is));
String s="";
while((s=br.readLine())!=null)
System.out.println(s);
参数查询角色功能代码 :1001999014
是指参数维护页面上那个查询按钮
下面这条sql的执行计划是:
1、首先执行4)中的子查询,IXSCAN
2、然后执行3)查询表TBL_MAPS_GFS_TASK,TBSCAN
3、对1、2的查询结果进行HSJOIN,从而获得了行号ROWNO_以及t.*
4、对查询的结果进行排序bmqid
5、选取前40行记录
1)SELECT ROW_NUMBER() OVER() AS ROWNO_, t.*
2)FROM TBL_MAPS_GFS_TASK t
3)WHERE OPER_IN != 'd'
4)AND (node_id in (select NODE_ID from TBL_MAPS_GFS_DEPLOY_INF where SUBSYS_CD='BAT'))
5)order by bmqid
6)FETCH FIRST 40 ROWS ONLY
下面这条sql不同的地方就是第4)行,但是db2的执行计划就变成了:
因为node_id是索引查询,3)、4)、5)条件一起执行,IXSCAN,
然后再获得排完序的行号ROWNO_
1)SELECT ROW_NUMBER() OVER() AS ROWNO_, t.*
2)FROM TBL_MAPS_GFS_TASK t
3)WHERE OPER_IN != 'd'
4)AND (node_id in ('21','22'))
5)order by bmqid
6)FETCH FIRST 40 ROWS ONLY
DB2存储主键的地方
select * from SYSIBM.SYSKEYCOLUSE;
select * fROM sysibm.SYSINDEXES;--存储索引
select * from sysibm.syscolumns;--存储字段
select * from sysibm.systables;
select * from SYSIBM.SYSTABLESPACES;
select * from sysibm.sysschemata;
java中读取下拉框内容:
TransMonitorFacade.getDrdp(String name, false)
数据库中DECIMAL (8,2)
表示的意思是:
小数点前的位数最多是6位,小数点后的位数一定是2位,不够的话补0
appCfg/config.properties文件中的provider_url是给管理系统自己的webservice用的EJB接口
ajax发送到后台的字符编码与form提交使用的字符编码不同
正确的代码:
javascript:GET方式
var phone = document.getElementById("phone").value;
var url = "<%=request.getContextPath()%>/upload?phone=" + (phone);
url = encodeURI(url);
req.open("GET", url, true);
req.onreadystatechange = updatePage;
req.send(null);
java:
String phone = request.getParameter("phone");
phone = new String(phone.getBytes( "ISO-8859-1"), "UTF-8");
//设置响应内容类别
response.setContentType("text/html;charset=UTF-8");
response.setCharacterEncoding("UTF-8");
//传回浏览器
response.getWriter().println("i know your phonedddd d的上少时诵诗书 : "+phone);
//不需再forward
javascript:POST方式
var xmlString = document.getElementById("phone").value;
xmlString = encodeURI(xmlString);
var url = "<%=request.getContextPath()%>/uploadxml";
req.open("POST", url, true);
// Tell the server you're sending it XML
req.setRequestHeader("Content-Type", "text/xml");
// Set up a function for the server to run when it's done
req.onreadystatechange = confirmUpdate;
// Send the request
req.send(xmlString);
java端后台,接受XML格式 + POST方式,乱码解决:
StringBuffer xml = new StringBuffer();
String line = null;
BufferedReader reader = request.getReader();
while((line=reader.readLine())!=null)
xml.append(line);
String temp = xml.toString();
temp = java.net.URLDecoder.decode(temp, "UTF-8");
//设置响应内容类别
response.setContentType("text/html;charset=UTF-8");
response.setCharacterEncoding("UTF-8");
//传回浏览器
response.getWriter().println("i know your phonedddd d的上少时诵诗书 : "+temp);
浏览器访问链接上有中文时,如http://localhost/import/dbpatch?ss=aaa东东东东dd,浏览器会转成如下链接:
http://localhost/import/dbpatch?ss=aaa%B6%AB%B6%AB%B6%AB%B6%ABdd
doGet方法中有两种方式获取:
1、String query = request.getQueryString();
System.out.println("query="+query);//ss=aaa%B6%AB%B6%AB%B6%AB%B6%ABdd
query = java.net.URLDecoder.decode(query, "gbk");//直接访问的servlet
System.out.println("query2="+query);//ss=aaa东东东东dd
2、String ss = new String(request.getParameter("ss").getBytes("iso8859-1"),"gbk");//说明requst.getParameter方法做了转码decode
System.out.println("@@@@@@@ss="+ss);
DB2
如果一个字段设置为NOT NULL 但是没有默认值。比如如下语句:
CREATE
TABLE a
(
MSG_SPEC_TP CHARACTER(4) DEFAULT ' ' NOT NULL,
INS_ID_CD_CAPTURE_MD CHARACTER(1) NOT NULL,
INS_ID_CD_CAPTURE_EXPRESS VARCHAR(152) NOT NULL,
RID CHARACTER(10) DEFAULT ' ' NOT NULL,
CONSTRAINT TIX_MAMGM_MIT_PK PRIMARY KEY (MSG_SPEC_TP)
);
那么在INSERT记录的时候,就必须带上该列,
甚至可以在该列的VALUES里面填'',当然不能不填或者填个NULL
正确:INSERT INTO a(MSG_SPEC_TP,INS_ID_CD_CAPTURE_MD,INS_ID_CD_CAPTURE_EXPRESS)VALUES('5555','','');
(注:执行上述语句后,VARCHAR类型的字段值是'',而CHAR类型的字段值是' ',多一个空格,是DB2数据库自动添加的值。)
错误:INSERT INTO a(MSG_SPEC_TP,INS_ID_CD_CAPTURE_MD,INS_ID_CD_CAPTURE_EXPRESS)VALUES('5555',,'');
错误:INSERT INTO a(MSG_SPEC_TP,INS_ID_CD_CAPTURE_MD,INS_ID_CD_CAPTURE_EXPRESS)VALUES('5555',null,'');
错误:INSERT INTO a(MSG_SPEC_TP,INS_ID_CD_CAPTURE_MD)VALUES('5555','');
错误:INSERT INTO a(MSG_SPEC_TP,INS_ID_CD_CAPTURE_EXPRESS)VALUES('5555','');
如果这个列有默认值,那么INSERT语句就可以不出现该字段,比如上述的正确语句中就没有RID字段。
在FLD_ATTR中字段名配置为小写,不影响其在页面上进行录入,但是查询的时候字段值会显示不出来。
从cache中读取下拉框的值
List<Map<String, String>> ParameterFlexFacade.getDropdownListByFld(String fldCd)
TBL表中重复的EVENT_ID也没有关系
同步正式表的操作:ParaSyncServiceBean.activate。从batch取出的event_id是从TMP表中取得记录,然后根据记录的主键值
更新TBL中的记录。
appCfg/securityClient.properties文件详解:
defaultSSOUrl=http://172.17.249.56:6008
##maps ip
172.17.252.85=http://172.17.248.56:6008
##F5 ip
172.17.248.31=https://172.17.248.31:1215
Remote_NewSecurityEJB_Url=t3://172.17.248.56:6008
##maps system str assigned by sso
SysIdStr=6018724E9A708E13CB0156465E8E8384
isPortalLogin=false
loginClassName=com.cup.portal.security.utils.CupPortalSecurityUtil
如果Remote_NewSecurityEJB_Url这个配错了的话,重启后登陆会报如下错误:
Caused by: java.net.UnknownHostException: 172.17.258.56
at java.net.InetAddress.getAllByName0(InetAddress.java:1275)
at java.net.InetAddress.getAllByName(InetAddress.java:1197)
at java.net.InetAddress.getAllByName(InetAddress.java:1119)
at weblogic.rjvm.RJVMFinder.getDnsEntries(RJVMFinder.java:409)
at weblogic.rjvm.RJVMFinder.findOrCreate(RJVMFinder.java:180)
at weblogic.rjvm.ServerURL.findOrCreateRJVM(ServerURL.java:153)
at weblogic.jndi.WLInitialContextFactoryDelegate.getInitialContext(WLInitialContextFactoryDelegate.java:352)
... 24 more
com.cup.newSecurity.exception.LdapBaseException:
at com.cup.securityClient.client.service.UserService.getLoginUserAndPrivileges(UserService.java:95)
at com.cup.maps.portal.common.filter.SessionFilter.doFilter(SessionFilter.java:66)
at weblogic.servlet.internal.FilterChainImpl.doFilter(FilterChainImpl.java:42)
at com.cup.maps.portal.common.filter.SetCharacterEncoding.doFilter(SetCharacterEncoding.java:64)
at weblogic.servlet.internal.FilterChainImpl.doFilter(FilterChainImpl.java:42)
at edu.yale.its.tp.cas.client.filter.CASFilter.doFilter(CASFilter.java:221)
at weblogic.servlet.internal.FilterChainImpl.doFilter(FilterChainImpl.java:42)
at weblogic.servlet.internal.WebAppServletContext$ServletInvocationAction.run(WebAppServletContext.java:3496)
at weblogic.security.acl.internal.AuthenticatedSubject.doAs(AuthenticatedSubject.java:321)
at weblogic.security.service.SecurityManager.runAs(Unknown Source)
at weblogic.servlet.internal.WebAppServletContext.securedExecute(WebAppServletContext.java:2180)
at weblogic.servlet.internal.WebAppServletContext.execute(WebAppServletContext.java:2086)
at weblogic.servlet.internal.ServletRequestImpl.run(ServletRequestImpl.java:1406)
at weblogic.work.ExecuteThread.execute(ExecuteThread.java:201)
at weblogic.work.ExecuteThread.run(ExecuteThread.java:173)
java文件中:
String s = "工作就";
使用各种编码进行javac,语句如:javac -encoding GBK TestString.java
然后class文件中这三个汉字如何显示。
iso8859-1
String s = "\271\244\327\367\276\315";
默认编码
String s = "\u5DE5\u4F5C\u5C31";
GBK
String s = "\u5DE5\u4F5C\u5C31";
UTF-8
String s = "\uFFFD\uFFFD\uFFFD\uFFFD\uFFFD\uFFFD";
编成class文件以后,这个字符串的长度,就是用length()函数得到的长度就比较好理解了。
用iso8859-1编码进行编译后执行length()函数得到的长度是6,gbk编码进行编译的长度是3,utf-8编码进行编译的长度也是6。
注:
java中byte使用1个字节(8 bit)表示,char使用2个字节(16bit位)来表示。
还可以按某种编码来执行,如下:
java -Dfile.encoding=ISO8859-1 TestString
查看哪个进程绑定哪个邮箱
mtqmng pid
管理应用上的mtq是为了异步邮箱而安装的,生产上面两台管理应用就有两台MTQ,其中mtq2没有作用。
因为第二台管理上getmsgservice这个线程在启动时,读取deploy_inf表中的管理MGM默认节点,所以会与mtq1的134邮箱绑定。
同步模块在往管理发的时候也仅仅发送31号管理应用,也即第一台管理。
在Unix下获取多个IP的方法
ifconfig -au |grep inet |grep -v inet6 |grep -v 127.0.0.1 |awk '{print $2}'
EVENT_ST:事件状态
0-交易已发送
1- 交易被接受
2 - 交易已处理
99-交易出错
RESP_CD:请求应答码
00 - 成功
01 - 失败
99 - 确认收到请求/应答报文
response.code:返回报文中的应答码
00 -交易成功
XX-交易已接受
其它 - 交易失败
记联机交易日志MANAGE_TRANS_LOG时,首先根据逻辑一得出EVENT_ST:
if response.code == 00
EVENT_ST = 2
else if response.code == XX
EVENT_ST = 1
else
EVENT_ST = 99
然后根据逻辑二得出RespCode:
if ("99".equals(EVENT_ST)) {
tmmtl.setRespCode("01");
} else if ("2".equals(EVENT_ST)) {
tmmtl.setRespCode("00");
} else if ("1".equals(EVENT_ST)) {
tmmtl.setRespCode("99");
}
但是,在读取异步邮箱的代码GemMsgService中,却忘记了逻辑二,
直接将response.code中的代码更新到联机交易日志MANAGE_TRANS_LOG的RESP_CD字段。
删除子表记录:应该在创建修改任务中,再选择新增、修改、删除子表记录。
172.17.252.85上ma_mgm用户/mgmtest目录有最大50m的限制。
可以在console中的Security Realms->myrealm->users and groups ->点用户->passwords->save,
然后修改/mapsDomain/servers/MapsServer/security/boot.properties,这样该用户的登录weblogic的密码就改好了。
但是,改完之后执行stopWL.sh的时候报错,说密码错误。要改动bin/stopWebLogic.sh把其中的password改成正确的。就可以关掉weblogic了(或者删除也可以)
反编译资源文件
native2ascii -reverse -encoding gbk MessageResources.properties MessageResources_cn.properties
查看AIX系统资源
cpu:
vmstat(lcpu=8逻辑cpu有8个)
prtconf( Number Of Processors: 4 ==》物理cpu有4个)
查看系统使用情况 topas
查看aix内存svmon -G
例:
size inuse free pin virtual mmode
memory 2621440 2612781 8659 640841 3284826 Ded
pg space 1048576 898467
单位是4k,memory是实际物理内存:2621440*4/1024/1024=10g,
pg space是换页空间大小:1048576*4/1024/1024=4g
aix上查看java进程所占内存
svmon -P pid
例:
svmon -P 52363278
-------------------------------------------------------------------------------
Pid Command Inuse Pin Pgsp Virtual 64-bit Mthrd 16MB
52363278 java 132076 7764 5865 158615 Y Y N
进程实际使用内存Inuse:132076*4/1024 = 516M
查看AIX系统资源
prtconf
逻辑cpu
topas
bindprocessor -q
vmstat
物理cpu
prtconf
查看cpu的详细信息,如主频,是否支持SMT,是否开启了SMT等等
lsattr -El proc0
查看网卡相信信息,网卡ent0
netstat -v ent0
Eclipse @override报错
在JAVA 1.5和1.6中@override的用法是有些区别的,虽然改变了JRE但eclipse还是会报错。
解决办法:Windows->Preferences-->java->Compiler-->compiler compliance level设置成6.0就OK了
weblogic.xml中 weblogic-web-app 标签的 xsi:schemaLocation 属性,在myecplise下面报错如下:
Referenced file contains errors (http://www.bea.com/ns/weblogic/weblogic-web-app/1.0/weblogic-web-app.xsd). For more information, right click on the message and select "Show Details..."tips/tamcx/WEB-INFweblogic.xmlline 1131191929944315159
解决办法,在xsi:schemaLocation属性增加一段内容,如下:
http://java.sun.com/xml/ns/javaee
myeclipse6.0.1注册码生成:
TOOLS/MyEclipseGen.java执行后,输入名字就可以生成序列号。比如:
用户名shenlei
序列号Serial:fLR8ZC-855575-69527357679415182
myeclipse中js乱码问题,我导入项目后,发现js里的中文全部变成乱码
解决办法:
window->Preferences->Myeclipse->Files and Editors->JSP(以及javascript等)把encoding改成UTF-8。
workshop的webservice项目无法generate wsdl文件解决:
右键项目 Targeted Runtimes,勾上:Runtimes Oracle weblogic server v10.3
workshop中创建webservice工程,它的web.xml文件与weblogic.xml文件
与它export出的war包中的两个文件有所不同,需注意。
因为export出的war包中必须包括一些application启动类的配置。
行业机构静态信息表TBL_MAMGM_INDUSTRY_INS_STATIC_INF内的
INDUSTRY_INS_ST机构状态字段,0表示打开,1表示关闭
而对应联机库 TBL_MAONL_INDUSTRY_INS_DYN_INF表中的INDUSTRY_INS_ST字段 0表示关闭,1表示打开
workshop appxray编译时间过长解决:
右键工程——》properties->builders——》去掉勾选 workshop AppXRay
List<Map<String, String>> list = ms.findAllBySql(sql.toString(),
values);
这个方法竟然把我sql里面的列全变成大写字母放入MAP中
db2 创建远程节点连接
http://www.ibm.com/developerworks/cn/data/library/techarticles/0301chong/0301chong2.html
db2 catalog tcpip node mpwrnode remote mpower.ca.ibm.com server 50000
注: “mpwrnode”是为该节点所选择的任意名称。
mpower.ca.ibm.com = 数据库服务器 的主机名。 可以使用 IP 地址来代替主机名。
50000 = 数据库服务器实例 所使用的端口。
db2 catalog db a42ds1 at node mpwrnode
db2 connect to a42ds1 user <userid> using <password>
这样就可以再本地使用远程数据库。
例子如下:
1、db2 catalog tcpip node isvrfffffffff remote 172.17.248.188 server 60020
2、db2 catalog db ismgmdb at node isvrfffffffff
3、db2 terminate
4、db2 connect to ismgmdb user isvrdb3 using isvrdb3
删除catalog
db2 uncatalog node isvrfffffffff
在91ma_mgm上建的catelog,指向联机性能库
db2 catalog tcpip node maonldb remote 172.17.252.133 server 60000
db2 catalog db maonldb at node maonldb
db2 terminate
db2 connect to maonldb user ma_onldb using ma_onldb
当前用户的当前实例
db2 get instance
The current database manager instance is: ma_mgmdb
查看当前实例是否在
db2pd - -alldbpartitionnum
Database Partition 0 -- Active -- Up 129 days 07:30:50 -- Date 05/18/2012 17:02:26
查看活动日志使用如下命令:
db2pd -db arc -logs
当前实例的配置
db2 get dbm cfg
数据库的配置
db2 get db cfg for DBNAME
修改日志文件大小:db2 update db cfg for mamgmdb using LOGFILSIZ 40960
修改主日志文件个数:db2 update db cfg for mamgmdb using LOGPRIMARY 15
修改辅助日志文件个数:db2 update db cfg for mamgmdb using LOGSECOND 0
DB2 数据库一旦创建就无法再修改字符集的编码方式了。
可以在创建的时候指定字符集,如下指定为GBK:
create db SRCDB using codeset GBK territory CN
设置在锁上等待的时间
db2 "update db cfg for DBNAME using LOCKTIMEOUT 15"
主机上所有实例(其实就是用户)
db2ilist
显示的是当前实例下catalog的DB信息
db2 list db directory
查看catalog中远程节点node的信息(实际就是远程数据库的信息)
db2 list node directory
查看表空间信息
db2 list tablespaces show detail
查看DB2 instance是启动还是停止的
1、db2_ps
2、db2pd -inst
3、ps -ef | grep -i "db2sysc" | grep -i "<instance name>"
4、db2gcf -s
通过端口来查看哪个用户建了这个数据库
vi /etc/services
该文件里面有用户以及对应的端口,如:
DB2_ma_onldb 60032/tcp
DB2_ma_onldb_1 60033/tcp
DB2_ma_onldb_2 60034/tcp
财税库银实现类查询
select a.*,b.tran_name,b.tran_type,b.tran_class from t_sub_tran a ,t_tran b where a.tran_code=b.tran_code;
预置刷新共享内存表tbl_mamgm_para_task_syncshm_status和预置同步子系统表tbl_mamgm_para_task_syncsys_status
在公参同步中,一个1000条的批次,会插入2条(联机+批量)记录。
创建参数新增任务、创建参数修改任务,创建参数删除任务
这些动作之前要校验是否可以操作:
ParameterFlexFacade.checkParaOperatable()
其中checkParaRecordSyncIn函数调用了para_tbl_attr表的sync_in_exp字段,该字段是一个表达式,其中替换以后可以验证,如果验证失败将会抛exception,比如:
throw new BizException("主表正式表记录不存在,不允许操作!");
throw new BizException("此记录是只读的,不允许修改和删除操作!");
过滤条件组信息表,修改时报:“此记录是只读的,不允许修改和删除操作!”
原因是:tbl_mamgm_para_tbl_attr中该记录的字段SYNC_IN_EXP配置了下面语句:只有6开头的过滤条件组id才可以修改。
boolean result = !"#{RULE_GRP_ID}".startsWith("6");
01030201TBL_MAMGM_FILTER_RULE_GRP_INF过滤条件组信息表
报错的地方在:ParameterFlexFacade。checkParaRecordSyncIn函数
maps_sys是表示该记录是技术参数,不能操作
这个限制是指:para_tbl_attr表中sync_in_exp字段配置的:
boolean result = "maps_sys".equalsIgnoreCase("#{REC_UPD_USR_ID}");
目前多渠道包括两张表有此限制:
TBL_MAPS_GFS_MSG_SPEC_INF报文规范类型信息表,TBL_MAMGM_ACCESS_SYS接入系统标识表
sync_in_exp字段配置的其它包括:
TBL_MAMGM_FILTER_RULE_GRP_INF过滤条件组信息表boolean result = !"#{RULE_GRP_ID}".startsWith("6"); 不以6开头的的,就
TBL_MAMGM_FILTER_APP_INF过滤应用信息表boolean result = !"#{APP_ID}".startsWith("9");
批量的两张表任务表:
TBL_MABAT_BAT_TASK_CTRL
TBL_MABAT_RECNCL_TASK_INF
订单页面宽度变小后,多出一条横杆,解决办法:
1、main.css
.table_head 中去掉
background:url(../images/table_top_back.jpg) left top repeat-x;
这样换行就不会有一条杠了
2、WebContent/com/cup/isvr/portal/jpf/orderview/index.jsp中<th>与汉字之间加上
<div nowrap="nowrap">
</div>
3、把.datashow th行的line-height:27px;删除
HTTP GET和POST的区别
1、都是明文传输,都是不安全的
2、GET是在url上追加参数,POST在浏览器的地址栏中看不见参数,它是将表单内各个字段与其内容放置在HTML HEADER内
3、POST不会被浏览器缓存
4、GET是获取指定URL上的资源,是读操作,不论对某个资源GET多少次,它的状态是不会改变的
POST的语意是对指定资源“追加/添加”数据
5、长度限制,GET不能大于2k,POST一般认为不受大小限制。
浏览器中get方式:request.getContentLength()=-1,http规范中没有限制get方式不可以设置cotent-length,
GET /mjc/webtrans/PBRG HTTP/1.1
HOST: 172.17.248.74:11000
Accept: */*
Content-Length: 3
q=a
webservice的war包中wsdl和xsd文件既可以放在\WEB-INF\src\com\cup目录下,
也可以放在\WEB-INF\classes\com\cup在,用ant脚本编译workshop建的webservice工程时要修改web.xml文件
<2011-12-2 下午02时21分49秒 CST> <Warning> <Socket> <BEA-000402>
<There are: 5 active sockets, but the maximum number of socket reader threads allowed by the configuration is: 4.
You may want to alter your configuration.>
解决:左边菜单servers -> configuration -> tuning下,将Socket Readers:由33改成99
注:上面一行勾上Enable Native IO可显著提供weblogic性能
使用ant打包时,如果仅仅是import一个类,不在程序中使用该类的任何方法,或者new该类
就算这个类不在classpath中,也不会报错,且生成的class文件中没有import那句话。
W.java文件内容:
class W{
static{
System.out.println(org.apache.commons.net.ntp.TimeStamp.getCurrentTime());
}public static void main(String[] args){
}}
在cmd中执行情况是:成功、成功、成功、失败。
javac -cp "d:\bea\modules\com.bea.core.apache.commons.net_1.0.0.0_1-4-1.jar" W.java
java -cp ".;d:\bea\modules\com.bea.core.apache.commons.net_1.0.0.0_1-4-1.jar" W
javac -cp "D:\bea\wlserver_10.3\server\lib\weblogic.jar" W.java
java -cp "D:\bea\wlserver_10.3\server\lib\weblogic.jar" W
1、很明显weblogic.jar中没有org.apache.commons.net.ntp.TimeStamp类,为什么能编译通过
2、把weblogic.jar拷贝到比如D:\bea\wlserver_10.3\server目录下,就编译不过了。为什么?
对于db2中字段是char型的后面补了空格的情况,在java中用sql查出来时也是带空格的。
要在sql中或者resultset结果中使用trim()去掉空格。
启动多渠道管理应用时,执行分别会执行下面脚本
mapsDomain/startWL.sh
mapsDomain/startWebLogic.sh
mapsDomain/bin/startWebLogic.sh 配置DOMAIN_HOME、JAVA_OPTIONS
${DOMAIN_HOME}/bin/setDomainEnv.sh 配置WL_HOME、JAVA_VM、JAVA_HOME、USER_MEM_ARGS、PRODUCTION_MODE、DOMAIN_PRODUCTION_MODE、SERVER_NAME、JAVA_OPTIONS
${WL_HOME}/common/bin/commEnv.sh 配置BEA_HOME、WL_HOME、JAVA_HOME、JAVA_VENDOR、WEBLOGIC_CLASSPATH、PATCH_CLASSPATH、CLASSPATHSEP
现在想要做一个java的socket客户端,C的socket服务端。客户端向服务端发送的报文中头四个字节是整型,表示报文总长度,
之后才是报文内容。在C里很好做,先把长度转成网络字节序,再拷贝到四个字节的缓冲区里。但是JAVA中要怎么做呢?
答:使用DataOutputStream,用其中的writeInt方法
此方法是如下操作:>>>表示无符号右移,左移没有无符号一说,即没有<<<
out.write((v >>> 24) & 0xFF);
out.write((v >>> 16) & 0xFF);
out.write((v >>> 8) & 0xFF);
out.write((v >>> 0) & 0xFF);
int v =-2;
int s = v >> 1;
System.out.println(s);//-1
s = v >>> 1;
System.out.println(s);//2147483647
//00000000 00000000 00000000 00000000表示0
//01111111 11111111 11111111 11111111表示2147483647
//10000000 00000000 00000000 00000000表示-2147483648
//10000000 00000000 00000000 00000001表示-2147483647
//11111111 11111111 11111111 11111111表示-1 //通过System.out.println(Integer.toBinaryString(-1));方法可以看到二进制码
* Java 和一些windows编程语言如c、c++、delphi所写的网络程序进行通讯时,需要进行相应的转换
* 高、低字节之间的转换
* windows的字节序为低字节开头
* linux,unix的字节序为高字节开头
* java则无论平台变化,都是高字节开头
使用weblogic的jta全局事务
ctx = getInitialContext();//创建一个上下文环境
javax.transaction.UserTransaction ut = (javax.transaction.UserTransaction)ctx.lookup("javax.transaction.UserTransaction");
ut.begin();
...
ut.commit();
transient
java语言的关键字,变量修饰符,如果用transient声明一个实例变量,当对象存储时,它的值不需要维持。
Java的serialization提供了一种持久化对象实例的机制。当持久化对象时,可能有一个特殊的对象数据成员,
我们不想用serialization机制来保存它。为了在一个特定对象的一个域上关闭serialization,可以在这个域前加上关键字transient。
当一个对象被串行化的时候,transient型变量的值不包括在串行化的表示中,然而非transient型的变量是被包括进去的。
如果不implements Cloneable的话,那么调用super.clone()函数将抛出CloneNotSupportedException异常
shell脚本中获得日期
CURTIME=`date +%Y%m%d%H%M%S`
echo $CURTIME
JAVA四个方位修饰符
private--类内部
default--类内部,同包无继承关系类,同包子类
protected--类内部,同包无继承关系类,同包子类,不同包子类
public-类内部,同包无继承关系类,同包子类,不同包子类,不同包无继承关系类
@SuppressWarnings("serial")在Java中有什么作用?
@SuppressWarnings可以抑制一些能通过编译但是存在有可能运行异常的代码会发出警告,你确定代码运行时不会出现警告提示的情况下,可以使用这个注释。
("serial") 是序列化警告,当实现了序列化接口的类上缺少serialVersionUID属性的定义时,会出现黄色警告。可以使用@SuppressWarnings将警告关闭
表清理问题
TBL_MAMGM_TABLE_CLEAN_CFG
clean_md:0-多表清理;1-清理无效数据;2-清理指定表
ma_batdb.tbl_mabat_trans_log_chk_fail勾兑差错流水表,属于2-清理指定表;共7张,清理星期几的那张表的数据
ma_onldb.tbl_maonl_trans_refund退货表,也属于2-清理指定表,共3张,每月3号清理 第(month % 3 + 1)张表。
像众多的“0-多表清理”方式的表,表号取自ma_gfsdb.TBL_MAPS_GFS_DYN_SYS_PARA
ma_batdb.tbl_mabat_elct_prod_infBAT电子产品表,属于1-清理无效数据
ma_batdb.tbl_mabat_trust_data_infBAT托管数据表,属于1-清理无效数据
批量应用绑管理库
执行/maps/usr/hg_bat1/glb/gfs/sbin/mgmbind.sh
联机批量报818错,bind管理库有问题,需要将glb/gfs/bin/MDatasync_bat进程和glb/gfs/bnd/MDatasync_mgmdb.bnd文件一同拷贝
,注意进程的可执行chmod
taskcom list
进程扫描管理库的TBL_MAPS_GFS_TASK表,共享内存里面去
HttpServlet为什么要实现serializable?
我认为主要的原因是servlet容器可能会钝化servlet,把不活跃的servlet暂时持久化到IO设备
The servlet engine is not required to keep a servlet loaded for any period of time or
for the life of the server. Servlet engines are free to use servlets or retire them at any
time. Therefore, you should not rely on class or instance members to store state
information.
When the servlet engine determines that a servlet should be destroyed (for example,
if the engine is shut down or needs to conserve resources), the engine must allow the
servlet to release any resources it is using and save persistent state. To do this, the
engine calls the servlet’s destroy method.
The servlet engine must allow any calls to the service method either to complete
or to end with a time out (as the engine defines a time out) before the engine can
destroy the servlet. Once the engine destroys a servlet, the engine cannot route any
more requests to the servlet. The engine must release the servlet and make it eligible
for garbage collection.
容器不要求每个servlet都一直维持在内存,可以钝化,servlet也支持多种类加载方式,包括反序列化。
下拉框的两表DRDL_CFG和DRDL_ITEM_DEF都不支持oper_in in ('d','D')的过滤
DRDL_CFG表:DropDownCache.queryAll()
DRDL_ITEM_DEF表:
DataDropDown.java的构造函数调用了DropDownBaseImpl的构造函数,再调用了DataDropDown的init(),sql=SQL_LBLCD+...
SQL_LBLCD是在DropDownBaseImpl中定义:
static final String SQL_LBLCD="SELECT A.drdl_item_key,A.drdl_item_val FROM TBL_MAMGM_DRDL_ITEM_DEF A,"
+"TBL_MAMGM_DRDL_CFG B WHERE A.drdl_id=B.drdl_id AND B.drdl_nm=";
查看系统使用表空间的方法:
1、连接到目标数据库
命令:db2 connect to mamgmdb user username using password(username和password需要替换为正确的值)
2、查看数据库表空间使用情况
命令:db2 list tablespaces show detail
查看表空间所属容器信息
db2 list tablespace containers for 1 show detail
3、判断数据库表空间使用率是否正常的方法:
首先判断表空间类型(Type),如果Type= System managed space,说明表空间是操作系统管理的表空间,表空间自增长,只需关注表空间所在的文件系统的利用率。
如果Type= Database managed space,说明表空间是数据库管理的表空间,表空间非自增长,需要关注Used pages与Useable pages的比值,当(Used pages/Useable pages)>80%,需要及时向系统室值班岗报告。
查看数据库是否使用了归档日志,OFF为循环日志
db2 get db cfg for gmabatdb|grep LOGRETAIN
Log retain for recovery enabled (LOGRETAIN) = OFF
Log retain for recovery enabled (LOGRETAIN) = RECOVERY (为归档日志)
AIX主机名:
hostname
主机名对应的IP
vi /etc/hosts
aix查看某进程打开的文件数量
procfiles -n pid
对某进程强制垃圾收集
procfiles -F pid
UdpServlet的启动日志在cup_maps_alarm.log里面
多渠道和行综也会被xss跨站脚本攻击,原因就是这次新加的titleNm值
https://172.17.248.188:7002/isvr/com/cup/isvr/portal/jpf/flex/parameter.jsp?subjectId=010911&titleNm=ddd");}alert('xss');>
https://172.17.248.188:7002/isvr/com/cup/isvr/portal/jpf/flex/parameter.jsp?subjectId=010911&titleNm=ddd");}alert(request.getParameter('subjectId'));>
Apache JMeter是Apache组织开发的基于Java的压力测试工具。用于对软件做压力测试
SQL
对于查不出结果的sql语句的ResultSet一点不同:
select * from tbl_mamgm_para_task where EVENT_ID =2rs.next() == false
select 1 from tbl_mamgm_para_task where EVENT_ID =2rs.next() == false
select sum(1) from tbl_mamgm_para_task where EVENT_ID =2rs.next() == true,且rs.getInt(1)==0
flex的DateField日期组件,默认是不可修改。如果需要修改增加属性:
editable="true"
weblogic热部署必须要把启动模式改成开发模式,方法是config.xml中标签<production-mode-enabled>改成false。
热部署的build.xml关键语句
<target name="redeploy" description="redeploy ear to WebLogic on ${wls.ip}:${wls.port};">
<wldeploy user="${user}" password="${password}" adminurl="t3://${wls.ip}:${wls.port}" debug="true" remote="true" upl
oad="true" action="redeploy" name="${map.earApp.name}" source="${dest.home}/dest/${map.earApp.name}.ear" verbose="true" />
</target>
在TimerTaskStartThread类中增加了catch NoSuchEJBException{break;}的原因是:
答:在redeploy管理应用ear包的时候,增加了一个TimerTaskStartThread线程,但是原先的TimerTaskStartThread线程仍在,
只是原先线程缓存了之前的ejb对象,导致了一直报错,虽然新的TimerTaskStartThread线程使得功能无影响,
但是break出去以后就不会在nohup.out里面报错了。
当db2中某表被锁,当使用weblogic数据源select该表,或者java应用通过jdbc select该表,均在10秒钟后报错,一个的errorcode=-4470,
另一个的SQLCODE=-911,这个超时时间10秒设置在:
1、db2 "update db cfg for DBNAME using LOCKTIMEOUT 15" 此处15是指设置锁上等待15秒
2、重启db2实例,才能生效
AIX查看某个端口被哪个进程占用
1. netstat -Aan|grep <portnumber>
2. 如果是 tcp 连接,则 rmsock <PCB/ADDR> tcpcb,如果是 udp 连接,则 rmsock <PCB/ADDR> inpcb
下面我们以 telnet 服务所使用的 23 号端口为例,说明该方法:
#netstat -Aan|grep 23
f1000200019ce398 tcp 0 0 *.23 *.* LISTEN
可以看到 PCB/ADDR 为 f1000200019ce398 ,且协议类型为 tcp
#rmsock f1000200019ce398 tcpcb
The socket 0x19ce008 is being held by proccess 185006 (inetd).
命令报告该端口正在被 inetd 进程使用, PID 为 185006 。
3. ps -ef |grep PID
windows查看端口占用命令
1、netstat -aon|findstr "80"
2、tasklist|findstr "2448"
windows杀死进程命令
tskill PID或者
HttpServletResponse的getBufferSize()方法获取Web容器的以kb为单位的目前缓冲区大小
cvs上被remove和commit的文件,恢复的办法:
答:根据版本号或者标签号checkout下来,例如historyFrame.html文件已经被彻底删除:
cvs co -r maps-7760-20120724 maps_mgm/flex/comm/html-template/history/historyFrame.html
日切日期:
同步模块会校验:管理发给的日期 = TBL_MAPS_GFS_DYN_SYS_PARA.MAPS_SETT_DATE + 1 校验不过直接报错
这个字段表示当前使用哪张表:
TBL_MAPS_GFS_DYN_SYS_PARA.multi_tab_act
第一位:0表示不在日切窗口期,1表示在日切窗口
第二位:2套表使用第几张
第三位:3套表使用第几张
第四位:7套表使用第几张
应用启动时数据源连接池的驱动用的是mapsDomain/lib/db2jcc.jar,
启动时,weblogic会自动去mapsDomain/lib下加载所有jar包。
FAQ
Some solutions to common problems:
Exception
java.lang.IllegalStateException: Application was not properly initialized at startup, could not find Factory: javax.faces.context.FacesContextFactory
Solution
Include a listener in your web.xml:
<listener>
<listener-class>com.sun.faces.config.ConfigureListener</listener-class>
</listener>
问题:jsf的javax.faces.application.ViewExpiredException异常
答:去掉richfaces4的jar包
数据库字段,前面加上函数就不走索引了
select * from TBL_MAMGM_POS_PARA_INF WHERE LOWER(mchnt_cd) LIKE '11%';
RETURN0.0 %13993.33593751.350166272E913474.07.85886144638061513993.32128906251.35012864E913474.00.00.013474.00.00.0
MA_MGMDB.TBL_MAMGM_POS_PARA_INF TBSCAN100.0 %13993.33593751.350166272E913474.07.85886144638061513993.32128906251.35012864E913474.00.00.013474.00.00.044675.437512
weblogic上ssl的端口默认是7002,所以有可能7002不出现在config.xml文件中
eclipse默认启动内存在eclipse.ini文件中配置:
诸如:
-Xms128m
-Xmx512m
-Duser.language=en
-XX:PermSize=128M
-XX:MaxPermSize=256M
boolean offer(E e)
Inserts the specified element into this queue if it is possible to do so immediately without violating capacity restrictions. When using a capacity-restricted queue, this method is generally preferable to add(E), which can fail to insert an element only by throwing an exception.
它们的区别就是add 方法在插入失败的时候会抛出 IllegalStateException 异常
而offer可以通过返回值来判断成功与否
Server监听
Socket clientSocket = serverSocket.accept();
tcp 0 0 *.8886 *.* LISTEN
已建立的链接
cp4 0 0 172.17.248.74.8886 172.17.236.133.3966 ESTABLISHED
java做webservice时获得客户端的信息
import javax.servlet.http.HttpServletRequest;
import javax.xml.ws.WebServiceContext;
import javax.xml.ws.handler.MessageContext;
@Resource
WebServiceContext messageContext;
MessageContext mc = messageContext.getMessageContext();
HttpServletRequest request = (HttpServletRequest)mc.get(MessageContext.SERVLET_REQUEST);
String remortAddress = request.getRemoteAddr();
/*request.getLocale()=zh_CN
request.getLocalAddr()=172.17.248.74
request.getLocalName()=host01
request.getLocalPort()=8888
remortAddress=172.17.236.133
request.getRemoteHost()=172.17.236.133
request.getRemotePort()=3823
request.getRemoteUser()=null*/
System.out.println("request.getLocale()="+request.getLocale());
System.out.println("request.getLocalAddr()="+request.getLocalAddr());
System.out.println("request.getLocalName()="+request.getLocalName());
System.out.println("request.getLocalPort()="+request.getLocalPort());
System.out.println("remortAddress="+remortAddress);
System.out.println("request.getRemoteHost()="+request.getRemoteHost());
System.out.println("request.getRemotePort()="+request.getRemotePort());
System.out.println("request.getRemoteUser()="+request.getRemoteUser());
j2se开启webservice服务:
String wsUrl= "http://172.17.236.133:8888/MtqWebService?wsdl";
Endpoint.publish(wsUrl, new MtqWebService());
MtqWebService是一个类,需要标注@WebService、@WebMethod。
如果想让webservice服务的方法抛出异常必须要把异常包装成SOAPException,如:
@WebMethod
public String callByXml(String xmlData) throws Exception{
throw new SOAPException("dqqqqq");
}
Exception in thread "main" javax.xml.ws.WebServiceException: org.apache.cxf.service.factory.ServiceConstructionException
at org.apache.cxf.jaxws.EndpointImpl.doPublish(EndpointImpl.java:331)
at org.apache.cxf.jaxws.EndpointImpl.publish(EndpointImpl.java:234)
at org.apache.cxf.jaxws.spi.ProviderImpl.createAndPublishEndpoint(ProviderImpl.java:112)
at javax.xml.ws.Endpoint.publish(Endpoint.java:170)
at com.sl.ws.threadpool.MtqWebAction.main(MtqWebAction.java:22)
解决:去掉jbosslib的user library
Caused by: java.security.PrivilegedActionException: com.sun.xml.internal.bind.v2.runtime.IllegalAnnotationsException: 2 counts of IllegalAnnotationExceptions
Class has two properties of the same name "msg"
this problem is related to the following location:
at public java.lang.String com.sl.ws.model.Request.getMsg()
at com.sl.ws.model.Request
this problem is related to the following location:
at public java.lang.String com.sl.ws.model.Request.msg
at com.sl.ws.model.Request
Class has two properties of the same name "msgRes"
this problem is related to the following location:
at public java.lang.String com.sl.ws.model.Response.getMsgRes()
at com.sl.ws.model.Response
this problem is related to the following location:
at public java.lang.String com.sl.ws.model.Response.msgRes
at com.sl.ws.model.Response
解决:将com.sl.ws.model.Request和 com.sl.ws.model.Response类中的属性从public改成private
weblogic在console中做update、stop、delete应用时,会调用Servlet的destroy()方法。
对于某些类的静态static实例变量,要在destroy方法中做clear,否则执行update、stop、delete后,static实例变量被认为是null值。
原先的static实例变量所指的对象将永远存在,直到domain被stoped
java socket的连接超时时间:
Socket socket = new Socket();
socket.connect( new InetSocketAddress( "172.17.236.133", 4700 ),5000); //比如此处设置成5s
如果端口4700在server上没有监听:
1、如果该client与server的ip在同一网关内,java较容易找到该server机器,则直接抛错:java.net.ConnectException: 远程主机拒绝 connect 操作尝试。
2、如果该client与server的ip不在同一网关内,java将会去DNS上找路由,时间较长,那么超时抛错会出现:java.net.SocketTimeoutException: connect timed out
由于AIX(或UNIX)系统和Windows系统对于文本文件的行末结束符(或回车换行符)的处理方式不同,
当我们将Windows格式的一个文本文件以BIN格式(而不是ASCII方式)上传至AIX上时,用vi查看该文件会发现每行的行末出现一个^M的符号。
这会导致AIX系统下对该文本文件的处理出现异常,并且在该文件是脚本的情况下,也会导致脚本执行异常。
杀死本用户下的weblogic进程
ps -fu $USER |grep weblogic|grep -v grep|awk '{print $2}'|xargs kill -9 $1
乱码
public static String getEncodedString(Object p) {
boolean isDefaultChinese = Locale.getDefault().getLanguage()
.toLowerCase().indexOf("zh") != -1;
String tmpStr = p.toString();
if (!isDefaultChinese)
try {
tmpStr = new String(tmpStr.getBytes("GBK"), "ISO8859_1");
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
return tmpStr;
}
网络传输中有个二进制0的概念,一个字节8位全是二进制0,在java里面表示byte b = '\0',
对于new String(byte[])以后,二进制0还会存在,只要做了trim()就去掉了。
如果把二进制0赋予整型会变化成ascii的0.
int i = '\0';
System.out.println("i="+i);//i=0
weblogic的web应用:
提交了重新编译的class文件,哪怕是其中一个文件,或者不相干的class文件,
原先class中static变量的值都被赋null了。
JDK5.0 java.util.concurrent包中引入对Map线程安全的实现ConcurrentHashMap
java.util.concurrent包也提供了一个线程安全的ArrayList替代者CopyOnWriteArrayList
如何讲二进制流 加入XML报文中发送?
// 将 s 进行 BASE64 编码
public static String getBASE64(String s) {
if (s == null) return null;
return (new sun.misc.BASE64Encoder()).encode( s.getBytes() );
}
// 将 BASE64 编码的字符串 s 进行解码
public static String getFromBASE64(String s) {
if (s == null) return null;
BASE64Decoder decoder = new BASE64Decoder();
try {
byte[] b = decoder.decodeBuffer(s);
return new String(b);
} catch (Exception e) {
return null;
}
}
只要在xsd中,将某个字段类型设置成base64Binary,jaxb能自动讲xml中的BASE64 编码的字符串解析成正确的byte[]数组。
Socketsocket = new Socket();
//socket.setSoTimeout(5000);
InetSocketAddress local = new InetSocketAddress("172.17.246.1",0);
socket.bind(local);
socket.connect( new InetSocketAddress( "145.17.236.133", 4700 ),1000);
socket.setSendBufferSize(100);
mian2 aix测试结论:
1、新增一个new NioSocketConnector(1),增加4个句柄的使用。只开一个NioProcessor,即只用一个cpu,只开一个select.open()
2、新增一个new NioSocketConnector(),增加了4*(4+1)个句柄。第2个4:是248.74上有4核的cpu 4+1是默认值
3、做一次connector.connector()操作,即新增一条链路的话,增加1个句柄
4、new NioSocketConnector()和new NioSocketConnector(Runtime.getRuntime().availableProcessors() + 1)是一样的。
log4j.properties、CommPacket.ini、FilePacket.ini、mtq.properties 先找mtqCfg/ ,再找appCfg/,再找当前路径下
mtqNetwork.xml、mtqService.xml 必须在mtqCfg目录下,或者mtqCfg/sysname/目录下
如何使用JDK自带的JConsole监控Weblogic
http://172.17.249.10/NewSys/OA/KnowledgeBase/ShowKb.aspx?Id=6440&Key=
在java启动时添加:
-Dcom.sun.management.jmxremote.port=41125 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false
在windows path中:
Jconsole
myeclipse6.0
今天安装完eclipse和myeclipse以后,发现启动后窗口的标题栏显示:wtp java ee(myeclipse incompatible)?
选其它的perspective(视图): MyEclipse Java Enterprise
官方文档指出,WebLogic 9 / WebLogic 10 的线程池是自调优的,并且在WebLogic 9的时候,
通过修改config.xml可以修改默认线程池的最小值、最大值,但是很麻烦。
到了WebLogic 10gR3,连修改config.xml的办法都给取消了。
但是,可以通过在启动脚本增加如下参数,可以指定默认线程池的最小值、最大值:(http连接数)
-Dweblogic.threadpool.MinPoolSize=100 -Dweblogic.threadpool.MaxPoolSize=500
HashMap map.get(null) 返回null
ConcurrentHashMap concurmap.get(null) 报错java.lang.NullPointerException
ConcurrentHashMap concurmap.put(Integer.valueOf(2),null);报错java.lang.NullPointerException
Map遍历方式
for(Map.Entry<String, String> map : formFldValues.entrySet()){
queryString += map.getKey()+" like ? and";
values.add(map.getValue());
}
xml 转 javabean方式
//方式一 jaxb ,无需额外lib包
/*InputStream is = null; 效率最差
try {*/
// System.out.println(REQ.class.getPackage().getName());
/*JAXBContext jc = JAXBContext.newInstance(REQ.class.getPackage()
.getName());// 包名
Unmarshaller u = jc.createUnmarshaller();
is = new ByteArrayInputStream(xmlStr.getBytes("GBK"));
REQ req = (REQ) u.unmarshal(is);*/
//方式二 xsream ,需xstream-1.3.1.jar 10w次 78390ms
/*XStream xs1 = new XStream(new DomDriver());
xs1.alias("REQ", REQ.class);
REQ req = (REQ) xs1.fromXML(xmlStr);*/
//方式三 dom4j,需dom4j-1.6.1.jar 10W次 54203ms
Document doc=null;
try {
doc = DocumentHelper.parseText(xmlStr);
} catch (DocumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} // 将字符串转为XML
Element rootElt = doc.getRootElement(); // 获取根节点
System.out.println("根节点:" + rootElt.getName()); // 拿到根节点的名称
System.out.println(rootElt.elementTextTrim("SYSTEMNAME"));
//方式四 stax 10w次 6125ms
static XMLInputFactory inputFactory = XMLInputFactory.newInstance();
byte[] byteArray = xml.getBytes("GBK");
ByteArrayInputStream inputStream = new ByteArrayInputStream(byteArray);
XMLStreamReader reader = inputFactory.createXMLStreamReader(inputStream);
int event = reader.getEventType();//获取节点类型,结果是以整形的方式返回的。
while (reader.hasNext()) {
switch (event) {
case XMLStreamConstants.START_DOCUMENT://表示的是文档的开通节点。
break;
case XMLStreamConstants.START_ELEMENT://开始解析开始节点
if (reader.getLocalName().equals("SYSTEMNAME")) {//判断节点的名字
mr.setSystemName(reader.getElementText());
}
break;
}
event = reader.next();
}
//方式五 自解 10w次 1437ms
mr.setSystemName(sb.substring(sb.indexOf("<SYSTEMNAME>")+12,sb.indexOf("</SYSTEMNAME>")));
使用cxf测试了csb上webservice,证明可行:
但是csb似乎不支持使用一个url获取wsdl,原因是解析后的wsdl文件倒数第四行address location是主机名,而不是ip
如:
http://P570_F_3:7001/csb/shcenter/BillDomain/MultiAcquiringSystem/BpsServiceImplService/BpsServiceImplServiceProxy
所以需要把wsdl保存在d:/BpsServiceImplServiceProxy.wsdl,然后将上述address location替换如下:
http://172.17.252.63:7001/csb/shcenter/BillDomain/MultiAcquiringSystem/BpsServiceImplService/BpsServiceImplServiceProxy
其效果与使用应用自己的webservice一样。
http://172.17.252.85:4866/MapsServicePortal/BpsServiceImplService?wsdl
此外还可以把解析好的变量设置成final类型:
JaxWsDynamicClientFactory dcf = JaxWsDynamicClientFactory.newInstance();
final Client client = dcf.createClient("d:/BpsServiceImplServiceProxy.wsdl");
Object[] res = client.invoke("excuteBpsService","<CUPBPS></CUPBPS>","BPS", "MAPSQUERY");
System.out.println("Echo response: " + res[0]);
如果xml请求报文中无<FILECONTENT>标签,则进不去这个if中
} else if (reader.getLocalName().equals("FILECONTENT")) {//判断节点的名字
如果xml请求报文中有,且值为空,如<FILECONTENT></FILECONTENT>,则
String s = reader.getElementText();
System.out.println((s==null));//false
System.out.println((s.equals(""))); //true
byte[] b = s.getBytes();
System.out.println((b==null));//false
System.out.println((b.length));//0
log4j级别依次下降
// Field descriptor #56 Lorg/apache/log4j/Level;
public static final org.apache.log4j.Level OFF;
// Field descriptor #56 Lorg/apache/log4j/Level;
public static final org.apache.log4j.Level FATAL;
// Field descriptor #56 Lorg/apache/log4j/Level;
public static final org.apache.log4j.Level ERROR;
// Field descriptor #56 Lorg/apache/log4j/Level;
public static final org.apache.log4j.Level WARN;
// Field descriptor #56 Lorg/apache/log4j/Level;
public static final org.apache.log4j.Level INFO;
// Field descriptor #56 Lorg/apache/log4j/Level;
public static final org.apache.log4j.Level DEBUG;
// Field descriptor #56 Lorg/apache/log4j/Level;
public static final org.apache.log4j.Level TRACE;
// Field descriptor #56 Lorg/apache/log4j/Level;
public static final org.apache.log4j.Level ALL;
持卡人管理upjas配置文件
$HOME/upjas/upjas-minimal/server/default/cup-deploy/mtqCfg
domain启动时脚本,以及nohup.out文件位置
$HOME/upjas/upjas-minimal/bin
java使用udp
客户端:
DatagramPacket packet = new DatagramPacket(msg.getBytes(), Integer
.valueOf(msg.length()), address, Integer.valueOf(port));
DatagramSocket socket = new DatagramSocket();
socket.send(packet);
//发送以后socket记下了本机使用的临时端口:socket.getLocalPort()
//所以之后可以监听端口等待了
byte[] message = new byte[256];
DatagramPacket recpacket = new DatagramPacket(message, message.length);
socket.setSoTimeout(10 * 1000);
socket.receive(recpacket);
//从udp包中获取数据是这样的:
String recmsg = new String(recpacket.getData(),0,recpacket.getLength());
System.out.println("client:"+recmsg);
服务端:
DatagramSocket socket = new DatagramSocket(Integer.valueOf(port)); //监听一端口
byte rb[] = new byte[1024];//申请一块内存
DatagramPacket pac = new DatagramPacket(rb, rb.length);//装成udp包
socket.receive(pac);//阻塞读,一旦收到内容,往udp包里面写信息,如:客户端ip、port;真实数据写入内存rb中
//使用接收时用的udp包中的客户端ip和port,将信息返回到客户端
String message = "toclient";
DatagramPacket recpacket = new DatagramPacket(message.getBytes(),message.length(), pac.getAddress(), pac.getPort());
socket.send(recpacket);// 发送回去
//另一种方式,原路返回客户端
pac.setData(message.getBytes());
socket.send(pac);// 发送回去
实践证明如果主机网卡上有两个ip(逻辑ip),那么下面代码,未绑定一个ip时,udp服务将在两个ip的端口上监听,udp客户端可以往两个ip的这个端口发消息
DatagramSocket socket = new DatagramSocket(Integer.valueOf(port));
且可以绑定两个ip的一个端口2次,下面的两个ip在一块网卡上。
String ip = "172.17.236.134";
InetAddress serveraddress = InetAddress.getByName(ip);
DatagramSocket socket = new DatagramSocket(Integer.valueOf(port),serveraddress);
String ip = "172.17.236.133";
InetAddress serveraddress = InetAddress.getByName(ip);
DatagramSocket socket = new DatagramSocket(Integer.valueOf(port),serveraddress);
如果ip是null或者“”,那么返回值是127.0.0.1的地址,
InetAddress serveraddress = InetAddress.getByName(ip);
----> impl.loopbackAddress();
AIX5.3上如何查IP配置及子网掩码!
smitty tcpip选中你要看的网卡,回车.看完后按ESC+0退出就可以了.
查看网卡信息
lsdev -Cc adapter|grep ent
ifconfig -a 查出有几个网络接口,因为可能装有多个网卡。假设有ent0、ent1
lscfg -v -l ent0,就可以查到这块网卡的包括子网掩码、所在插槽位置等多个信息。
count(*)和order by一起会报错?
select count(*) from TBL_MAMGM_DRDL_CFG order by drdl_id;
从javaEE5开始,jpa规范脱离了EJB规范,好处是J2SE环境也可以使用jpa持久化层了。
eclipse生成javadoc
Project -> Genetate JavaDoc
如果项目编码不是GBK而是UTF-8,那么在Extra javadoc options写上:
-encoding UTF-8
-charset UTF-8
ApplicationInfoUtil的属性是无法通过管理页面刷新获得更新的,要改?
为什么API里FileReference有load()方法和data属性却不能使用?
FileReference的load()方法和data属性需要使用flashplayer 10的版本,
要添加playerglobal.swc,在你所用的sdk包下面,我这里的路径是sdk3.5.0.12683/frameworks/libs/player/10/playglobal.swc
flex builder3 默认要求flash player 最低要9,需要改成10.0,修改方法如下:
右键点击项目,在项目属性中找 flex compile, 修改 html wrapper,把9.0.24改为10.0.0
flex工程ParaCommon报如下错误:'isNaN' is marked as extern, but '__AS3__.vec:Vector$int' is not?
右键工程-》Flex Library Compiler -》 Additional compiler arguments ->-target-player=10
so I went back to my application project to see if I had any special compiler settings, and remembered I had :
-target-player=10
Facade类的方法抛出BizExcpetion前台也获取不了。
@Column放在setPageImport上竟然获取不了数据库的值,只有放在getPageImport才正确。
flash10开始,FileReference增加了一个save方法,参数为(data:Object, defaultFileName:String = null),在调用save方法时,只需将文件内容传给data,
浏览器会自动打开一个保存对话框,让用户选择保存目录。有两个要注意的地方,1、save方法flash10及以上才有,客户端flash版本需跟上,
且代码编译环境也要在10以上,eclipse环境下,选中项目,右键properties,flex compiler选项,将required flash player version 设为10.0.0或以上,
否则将找不到save方法。2、save方法只能通过用户交互来调用。怎么理解用户交互,例如,点击一个下载按钮这算是用户交互,
而一般的回调方法则不是用户交互。如下载一张图片,如果图片还没加载进来,我们经常是先要进行加载,然后监听事件,然后在回调函数里进行处理,
如果将save方法写在回调函数里面,将会报错:Error #2176: 某些动作(如显示弹出窗口的动作)只能通过用户交互来调用。
所以很多时候我们必须采用双按钮,一个用来加载数据,一个用来下载数据。
点“模版文件下载”按钮没反应:
解决:eclipse环境下,选中项目,右键properties,flex compiler选项,将required flash player version 设为10.0.0或以上,
treemap是自然顺序(默认自然顺序,是指如果key是int型就是按数字大小,如果key是string则按照字母顺序排列,如果实现了Comparator接口即可按照想要的顺序了),
linkedmap是插入顺序,ListOrderedMap,LRUMap等都是有一定规则的顺序的map...
PrepardStatement语句中占位符?不能在select的字段中,只能在where条件后?
持续insert时候,db2报如下错误:ERRORCODE=-805,SQLSTATE=51002
问题的根本是因为程序里有很多游标没有关闭
问题解决了,谢谢你的提醒!!
pstmt.executeUpdate();
pstmt.close();//加上这一行
就可以了。
新增菜单无法通过刷新管理缓存立刻可见?
原因:tbl_mamgm_access_inf表中的access_cd字段值最后多了一个空格
同步子系统失败了以后竟然到了同步成功这一状态???
flex3中datagrid组件中某个单元格可编辑时,如何在键盘输入值之后触发事件函数获得值?
有两个事件可以itemEditEnd、itemFocusOut。
<mx:DataGrid id="defindInfoGrid" editable="true" itemEditEnd="valueVaildate(event)"/>
public function valueVaildate(event : DataGridEvent) : void
{
//第几列
Logger.info("event.columnIndex1 :"+event.columnIndex);
//dataField值
var dataField:String = event.currentTarget.columns[event.columnIndex].dataField;;
Logger.info("dataField :"+dataField);
//编辑前值
var oldValue:String=event.itemRenderer.data[dataField];//对已知的dataField:event.itemRenderer.data.FIELD_DESC
Logger.info("oldValue :"+oldValue);
var cols:DataGridColumn=defindInfoGrid.columns[event.columnIndex];
//编辑后新的值
var newValue:String=defindInfoGrid.itemEditorInstance[cols.editorDataField];
Logger.info("newValue :"+newValue);
}
db2查询sql时报如下错
09:06:16 [SELECT - 0 row(s), 0.000 secs]
[Error Code: -968, SQL State: 57011] DB2 SQL error: SQLCODE: -968, SQLSTATE: 57011, SQLERRMC: null
增加你的system temp tablespace所在文件系统大小,或者database temp tablespace空间利用率
在weblogic中,如果有多个war、war包应用,默认的部署顺序都是100,改变方法是修改config.xml中的<deployment-order>98</deployment-order>项
<app-deployment>
<name>mjc</name>
<target>MapsServer</target>
<module-type>war</module-type>
<source-path>/GGZF/usr/mapsweb/shenlei/dest/mjc.war</source-path>
<deployment-order>98</deployment-order>
<security-dd-model>DDOnly</security-dd-model>
</app-deployment>
或者在console中,点deployment中的某一项应用。
页面新增参数,点保存时报“当前用户没有此操作权限!”
原因:TBL_MAMGM_PARA_SUB_AREA_INF表中的ACCESS_CD没写对
参数维护时,创建新增任务,点保存,报“用户没有权限”错误
原因:subject表上access_url填写错误。
使用ThreadLocal以空间换时间解决SimpleDateFormat线程安全问题,同时提高了每次new SimpleDateFormat的效率
class DateUtil2 {
private static final String DATE_FORMAT = "yyyy-MM-dd";
private static ThreadLocal<DateFormat> threadLocal = new ThreadLocal<DateFormat>() {
protected synchronized DateFormat initialValue() {
System.out.println("initial");
return new SimpleDateFormat(DATE_FORMAT);
}
};
public static DateFormat getDateFormat() {
return threadLocal.get();
}
public static String format(Date date) throws ParseException {
return getDateFormat().format(date);
}
public static Date parse(String textDate) throws ParseException {
return getDateFormat().parse(textDate);
}
}
PreparedStatement中进行模糊查询:
String = "select * from tbl_mamgm_comm_line_cfg where line_no like ?"
PreparedStatement ps = conn.prepareStatement(sql);
ps.setObject(1, "%000HCSN0001A1%");
ResultSet rs = ps.executeQuery();
java.util.zip
GZIPOutputStream类用于压缩
GZIPInputStream类用于解压缩
2012 年餐饮业收入23,283 亿元,同比增长13.6%。其中限额以上餐饮业收入7,799 亿元,同比增长12.9%
限额以上餐饮业是指年主营业务收入200 万元及以上的餐饮业企业 (单位)
sleep三秒
TimeUnit.SECONDS.sleep(3);
poi中设置单元格为文本格式:
HSSFCellStyle cellStyle2 = demoWorkBook.createCellStyle();
HSSFDataFormat format = demoWorkBook.createDataFormat();
cellStyle2.setDataFormat(format.getFormat("@"));
cell.setCellStyle(cellStyle2);
excel 2003 工作表最大有2^16=65536行,2^8=256列
excel 2007 和excel 2010最大有2^20=1048576行,2^14=16384列
ibm jdk gc(xml格式) 查看工具ga441.jar
Used Tenured(After) gc过后老年代使用的内存大小
Free Tenured(After) gc过后年老代未使用内存大小
Total Tenured(After) gc过后老年代总大小
Free Tenured(Before) gc之前年老代未使用内存大小
Total Tenured(Before) gc之前老年代总大小
Free Nursery(After) gc之后年轻代未使用内存大小
Total Nursery(After) gc之后年轻代总大小
Free Nursery(Before) gc之前年轻代未使用内存大小
Total Nursery(Before) gc之前年轻代总大小
分配失败(AF)导致的垃圾收集的verbosegc输出
compact压缩
如果未设置虚拟机参数-Xnocompactgc并且以下几个条件任何一个为true,那么就会发生堆压缩动作:
· 设置了虚拟机参数-Xcompactgc
· 清理阶段结束之后,还是无法满足分配需求
· 调用System.gc()并且在最后一次分配失败发生或者并发标识收集之前发生了压缩动作
· TLH消耗了至少一半的存储,并且TLH的平均大小低于1000字节
· 堆的空闲空间小于5%
· 堆的空闲空间小于128KB
其实IBM的gc的停止比我们想象中要短的多。STW(stop total world)只有在下面这些条件才执行:
1.到达heap limited或者allocation fail
2.System.gc方法被调用
3.Concurrent mark 完成所有的工作
调大nursery尺寸会导致垃圾回收的停顿时间加长。
对于1GB的堆,如果进行了压缩动作,垃圾收集的暂停时间可能增加到40秒。
增量压缩技术就是将压缩动作分散到多次垃圾收集周期中,以减少暂停时间。
-Xpartialcompactgc,表示每次垃圾收集都使用增量压缩,除非必须进行完整的压缩动作
使用ibm的HeapAnalyzer查看aix的dump文件(jdk有个工具:jmap -dump:live,format=b,file=d:\java.dump pid),内存映射--------ha445.jar
heapdump.20130605.160859.24969368.0004.phd
使用ibm的Thread and Monitor Dump Analyzer for java查看aix的core文件(通过kill -3 pid获得),查看线程、内存等完整信息--------jca432.jar
javacore.20130604.171533.10027244.0011.txt
java -Xmx1000m -jar jca432.jar
jmap 的用途是为了展示java进程的内存映射信息,或者堆内存详情
使用命令:
jmap pid 打印内存使用的摘要信息
jmap -histo:live pid 展示class的内存情况,展示的信息为编号,实例数,字节,类名
jmap -heap pid 展示pid的整体堆信息
jmap -dump:live,format=b,file=d:\java.dump pid导出的文件可以供分析用,比如jhat或者mat、ha445.jar,以便查找内存溢出原因
Jstat是Sun JDK中自带的监控工具,利用了JVM内建的指令对Java应用程序的资源和性能进行实时的命令行的监控,包括了对Heap size和垃圾回收状况的监控等等
jstat -gcutil 7432 5000 10每隔5000ms采样一次,一共采样10次
C:\Documents and Settings\沈雷>jstat -gcutil 7432 5000 10
S0 S1 E O P YGC YGCT FGC FGCT GCT
0.00 0.00 0.00 1.41 3.13 0 0.000 3 0.887 0.887
0.00 0.00 0.00 1.41 3.13 0 0.000 3 0.887 0.887
0.00 0.00 0.00 1.41 3.13 0 0.000 3 0.887 0.887
0.00 0.00 0.00 1.41 3.13 0 0.000 3 0.887 0.887
0.00 0.00 0.00 1.41 3.13 0 0.000 3 0.887 0.887
0.00 0.00 0.00 1.41 3.13 0 0.000 3 0.887 0.887
0.00 0.00 0.00 1.41 3.13 0 0.000 3 0.887 0.887
0.00 0.00 0.00 1.41 3.13 0 0.000 3 0.887 0.887
0.00 0.00 0.00 1.41 3.13 0 0.000 3 0.887 0.887
0.00 0.00 0.00 1.41 3.13 0 0.000 3 0.887 0.887
S0:年轻代中第一个survivor(幸存区)已使用的占当前容量百分比
S1:年轻代中第二个survivor(幸存区)已使用的占当前容量百分比
E:年轻代中Eden(伊甸园)已使用的占当前容量百分比
O:old代已使用的占当前容量百分比
P:perm代已使用的占当前容量百分比
YGC:从应用程序启动到采样时年轻代中gc次数
YGCT:从应用程序启动到采样时年轻代中gc所用时间(s)
FGC:从应用程序启动到采样时old代(全gc)gc次数
FGCT:从应用程序启动到采样时old代(全gc)gc所用时间(s)
GCT:从应用程序启动到采样时gc用的总时间(s)
如果FGC 过多,有必要调整下jvm参数。
F5负载均衡器简单的理解就是咱们通常称之四层交换机或七层交换机。同时也叫IP应用交换机
下载文件的按钮连点两次,页面上只会提示一个文件下载框,是第二次点击生成的文件
下载文件的文件保存框是resposne全部write完,还是开始写的时候就弹出来? 开始写
weblogic支持的最大http请求设置?
无法修改,可以通过在启动脚本增加如下参数,可以指定默认线程池的最小值、最大值:(http连接数)
-Dweblogic.threadpool.MinPoolSize=100 -Dweblogic.threadpool.MaxPoolSize=500
weblogic的http连接超时时间?
ueue: ‘billproxyqueue’ has been busy for “727″ seconds working on the request “Http Request: /bill/y
nQueryPublic.go”, which is more than the configured time (StuckThreadMaxTime) of “600″ seconds.>
一看明显是连接超时, 导致的错误.
1、程序问题,是不是程序中没有关闭连接
2、Configuration -》 Tuning -》 Stuck Thread Max Time: 600
如果程序没问题,则是weblogic的StuckThreadMaxTime设置过小而引起的,
一般weblogic server 的StuckThreadMaxTime默认参数是600s,即10分钟,如果并发量过大,
而导致等待处理过多,导致系统不停的增加线程,造成线程阻塞,
你可以把该参数设置大点这个是稍微调大StuckThreadMaxTime的参数即可.
3、看线程数设置,可适当增加线程数,这个在WLS控制台中可以调整
java程序模拟发起http请求到多渠道时,需要设置cookie值:
bke_isvr=dLpbR0XCzYryDZtPBhBLZwpQLn51sQ234hC1rlpqv6ThVJMJTK8W!1476132340
否则管理会将链接到sso时返回一个登陆页面给java模拟程序。
jsp文件,weblogic编译的servlet结果。
路径:项目/com/maps/index.jsp
编译好的路径:isvrDomain/servers/IsvrServer/tmp/_WL_user/isvr_mngApp/dioh2x/jsp_servlet/_com/_map
该servlet class的类名:out.println("========"+this.getClass().getName());
结果:========jsp_servlet._com._maps.__index
javac -verbose
java -verbose
DBPM服务端部在172.17.248.74 $HOME/shenlei/dbpm_j下
360在提交时会访问servlet两次:
https://172.17.248.181:7002/isvr/FileDownLoad?subjectId=080701&STAT_DT_STAT=20130617&STAT_DT_END=20130617
设置下载文件的大小:
response.setHeader("content-length", String.valueOf(filelen));
HTTP头的一些信息:
System.out.println("*******************************begin****************************************");
System.out.println("Protocol: " + request.getProtocol() );
System.out.println("Scheme: " + request.getScheme() );
System.out.println("Server Name: " + request.getServerName() );
System.out.println("Server Port: " + request.getServerPort() );
System.out.println("Protocol: " + request.getProtocol() );
System.out.println("Server Info: " + getServletConfig().getServletContext().getServerInfo());
System.out.println("Remote Addr: " + request.getRemoteAddr() );
System.out.println("Remote Host: " + request.getRemoteHost() );
System.out.println("Character Encoding: " + request.getCharacterEncoding() );
System.out.println("Content Length: " + request.getContentLength() );
System.out.println("Content Type: "+ request.getContentType() );
System.out.println("Auth Type: " + request.getAuthType() );
System.out.println("HTTP Method: " + request.getMethod() );
System.out.println("Path Info: " + request.getPathInfo() );
System.out.println("Path Trans: " + request.getPathTranslated() );
System.out.println("Query String: " + request.getQueryString() );
System.out.println("Remote User: " + request.getRemoteUser() );
System.out.println("Session Id: " + request.getRequestedSessionId() );
System.out.println("Request URI: " + request.getRequestURI() );
System.out.println("Servlet Path: " + request.getServletPath() );
System.out.println("Accept: " + request.getHeader("Accept"));
System.out.println("Host: " + request.getHeader("Host") );
System.out.println("Referer : " + request.getHeader("Referer") );
System.out.println("Accept-Language : " + request.getHeader("Accept-Language"));
System.out.println("Accept-Encoding : " + request.getHeader("Accept-Encoding") );
System.out.println("User-Agent : " + request.getHeader("User-Agent") );
System.out.println("Connection : " + request.getHeader("Connection") );
System.out.println("Cookie : " + request.getHeader("Cookie") );
System.out.println("Created : " + request.getSession().getCreationTime() );
System.out.println("LastAccessed : " + request.getSession().getLastAccessedTime() );
System.out.println("*******************************end****************************************");
jsp中文乱码三句话:
<%@ page language="java" import="java.util.*" pageEncoding="gb2312"%>
<%@page contentType="text/html;charset=gb2312"%>
<%request.setCharacterEncoding("gb2312");%>
在filter中设置request.setCharacterEncoding("gb2312");只支持post提交的信息,对于GET方式的提交在jsp中显示的方法是:
1、new String(request.getParameter("titleNm").getBytes("ISO8859-1"),"UTF-8"));
2、或者在/upjas/upjas-minimal/server/default/deploy/jbossweb.sar/server.xml中设置:
< Connector port="8080" protocol="HTTP/1.1" connectionTimeout="20000" redirectPort="8443" URIEncoding="GBK" />
upjas页面乱码修改了:
SetCharacterEncoding
web.xml
public void doFilter(ServletRequest request, ServletResponse response,
FilterChain chain) throws IOException, ServletException {
if (ignore || request.getCharacterEncoding() == null) {
String encoding = selectEncoding(request);
if (encoding != null) {
request.setCharacterEncoding(encoding);
}
}
HttpServletRequest req = (HttpServletRequest) request;
HttpServletResponse resp = (HttpServletResponse) response;
String tmpUrl = req.getRequestURI();
String queryString = req.getQueryString();
if (!StringUtil.isEmpty(queryString)&&queryString.contains("titleNm")) {
queryString = new String(queryString.getBytes("ISO8859-1"), "UTF-8");
tmpUrl = tmpUrl.substring(5)+"?"+queryString;
req.getRequestDispatcher(tmpUrl).forward(req, resp);
return;
}
chain.doFilter(request, response);
}
jboss上查看ejb和数据源是否部署成功:
http://localhost:端口/jmx-console/
左边菜单的jboss链接,然后选 service=JNDIView, 点击 list 下面的 invoke 看一看现在 jboss 的 jndi 里面都有哪些对象
直接看最下面的 global 部分就可以了,看看有没 有定义的Namespace
如果有,那就说明部署成功了,调用应该就没有问题了
http头增加了Content-Type:application/x-www-form-urlencoded;charset=UTF-8,而不是Content-Typeapplication/x-www-form-urlencoded时,
jboss能自动转换字符,而在filter中设置request.setCharacterEncoding(encoding);不起作用。
spring加载配置文件
1、把applicationContext.xml直接放在WEB-INF/classes下,spring会采用默认的加载方式
2、采用在web.xml中配置ContextLoaderListenera或ContextLoaderServlet指定加载路径方式。
3 通过ClassPathXmlApplicationContext或XmlWebApplicationContext代码动态加载!
对 HTTP 304 的理解:
304 的标准解释是:Not Modified 客户端有缓冲的文档并发出了一个条件性的请求(一般是提供If-Modified-Since头表示客户只想比指定日期更新的文档)。
服务器告诉客户,原来缓冲的文档还可以继续使用。看下面的http请求,里面的If-Modified-Since
GET /test/bar.emf HTTP/1.1
Accept: image/gif, image/jpeg, image/pjpeg, image/pjpeg, application/x-ms-application, application/x-ms-xbap, application/vnd.ms-xpsdocument, application/xaml+xml, application/vnd.ms-excel, application/vnd.ms-powerpoint, application/msword, */*
Accept-Language: zh-cn
User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET CLR 2.0.50727; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)
Accept-Encoding: gzip, deflate
If-Modified-Since: Fri, 28 Jun 2013 08:24:04 GMT
If-None-Match: W/"3952-1372407844254"
Connection: Keep-Alive
Host: 172.17.236.121:8080
apache反向代理:
修改Apache2.2\conf\httpd.conf配置
1.先去掉下面两行的注释
LoadModule proxy_module modules/mod_proxy.so
LoadModule proxy_http_module modules/mod_proxy_http.so
2.然后在最后增加
<VirtualHost localhost:80>#此处localhost:80为当前apache服务的 ip:port
ProxyPass / http://www.baidu.com
ProxyPassReverse / http://www.baidu.com
</VirtualHost>
那么浏览器访问http://localhost/img/bdlogo.gif , apache会将请求转发到:http://www.baidu.com/img/bdlogo.gif
例如使用apache作为域名www.test.com代理服务器,让其暴露在公网上,即DNS解析到本机器上,真正提供web服务器的是另一台位于同一内网的机器上,假设起IP是192.168.100.22,那么只需要如下配置就可以了。
ProxyPass / http://192.168.100.22/
ProxyPassReverse / http://192.168.100.22/
ProxyPass 很好理解,就是把所有来自客户端对http://www.test.com的请求转发给http://192.168.100.22上进行处 理,ProxyPassReverse 的配置总是和ProxyPass 一致,但用途很让人费解。似乎去掉它很能很好的工作,事实真的是这样么,其实不然,如果响应中有302重定向,ProxyPassReverse就派上用 场。举例说明,假设用户访问http://www.test.com/exam.php,通过转发交给http://192.168.100.22 /exam.php处理,假定exam.php处理的结果是实现redirect到login.php(使用相对路径,即省略了域名信息),如果没有配置 反向代理,客户端收到的请求响应是重定向操作,并且重定向目的url为http://192.168.100.22/login.php ,而这个地址只是代理服务器能访问到的,可想而知,客户端肯定是打不开的,反之如果配置了反向代理,则会在转交HTTP重定向应答到客户端之前调整它为 http://www.test.com/login.php,即是在原请求之后追加上了redirect的路径。当客户端再次请求http: //www.test.com/login.php,代理服务器再次工作把其转发到http://192.168.100.22/login.php。
客户端到服务器称之为正向代理,那服务器到客户端就叫反向代理。
apache利用mod_cache缓存图片:
在httpd.conf中打开mod_cache,然后:
1、内存:
<IfModule mod_cache.c>
LoadModule mem_cache_module modules/mod_mem_cache.so
<IfModule mod_mem_cache.c>
CacheEnable mem /images
MCacheSize 4096
MCacheRemovalAlgorithm LRU
MCacheMaxObjectCount 100
MCacheMinObjectSize 1
MCacheMaxObjectSize 2048
CacheMaxExpire 864000
CacheDefaultExpire 86400
CacheDisable /php
</IfModule>
</IfModule>
2、硬盘:
<IfModule mod_cache.c>
LoadModule disk_cache_module modules/mod_disk_cache.so
CacheDefaultExpire: 3600 #指定快取的预设过期秒数;默认值是一小时 (3600)。
CacheMaxExpire: 86400 #指定快取最大的过期秒数;默认值是一天 (86400)。
<IfModule mod_disk_cache.c>
CacheRoot d:/cachetest
#CacheSize 256
CacheEnable disk /
CacheDirLevels 4
#CacheMaxFileSize 64000
#CacheMinFileSize 1
#CacheGcDaily 23:59
CacheDirLength 3
</IfModule>
如何知道已经安装上的unix系统是否有cc编译器?
cc -v
cc 1.c
没有指定可执行文件的名字,系统会自动生成可执行文件a.out。这个可执行文件的名字是系统自动生成的。默认情况下就是a.out
可执行文件的名字管理?
cc -o 1 1.c
编译多个c语言源程序文件
cc -o 2 1.c 2.c
cc -o 2 1.o 2.c
系统会编译源程序代码文件,并生成对应的目标文件.o。但是不会把目标文件链接成可执行文件,即使存在main函数的情况下
cc -c 1.c
会生成1.o
SERVER系统(例如WINDOWS 2003或者2008)安装邮件服务器
XP系统不支持安装微软的Exchange邮件服务器(Exchange要求开启IIS+ASP+SMTP+NNTP服务,关键是还要求局域网内有电脑安装域控,XP只能装IIS服务),
某些第三方邮件服务器软件(Web方式的)可以支持
在向eclipse的jar包中导入了javadoc后,编写程序的过程中使用jar包中的方法时Eclipse会自动显示其注释说明,可以大大提高开发人员的效率。
在向eclipse的jar包中导入了source后,Eclipse将可以显示类的源代码,并且同时具有了导入javadoc的显示功能。
使用eclipse的时候,突然发现eclipse中按Alt+/ 后,代码智能感应不能出现?
解决:
从eclipse进入Window-Preferences-General-Keys。找到Content Assist,会发现快捷键是“ctrl+space”,这与windows系统的默认中英输入法切换快捷键冲突了,
需要修改,先Remove Binding,然后改为“alt+.”就可以了。它可以帮你联想到所有的类供你选择。
另:“word completion”的快捷键使用“alt+/”,它可以自动帮你补全类名。
在eclipse中打开jsp文件时出现An error has occurred.see error log for more details错误?
解决:进入打开cmd(命令提示符)Eclipes目录下,输入eclipse.exe -clean 待Eclipse启动后,即可打开编辑jsp页面
ejb以jar形式在jboss中发布后,jar包中的类可以直接被同时发布的war包中new出。
JBOSS5中ejb Stateless bean的开发:
Stateless的属性:mappedName不能与实现的类名相同,否则会报下面的错。name属性随便。
Caused by: org.jboss.aop.DispatcherConnectException: EJB container is not completely started, or is stopped.
如果不设置mappedName的话,客户端调用使用lookup("CompanySessionBean/remote"),
本地(ejb中调用ejb)使用remote和local都可以,不过使用remote费时:
lookup("CompanySessionBean/local")或者lookup("CompanySessionBean/remote")
在客户端中访问stateless bean时需要Properties,且使用Company/remote标志,如:
Properties prop = new Properties();
prop.setProperty(Context.INITIAL_CONTEXT_FACTORY,
"org.jnp.interfaces.NamingContextFactory");
prop.setProperty(Context.PROVIDER_URL, url);
prop.setProperty(Context.URL_PKG_PREFIXES,
"org.jboss.naming:org.jnp.interfaces");
InitialContext ctx = new InitialContext(prop);
DepartmentRemote dr = (DepartmentRemote)ctx.lookup("DepartmentRemote");
System.out.println(dr.getDepName("Company"));
在ejb中访问ejb不需要如此麻烦,不需要Properties和/remote:
InitialContext ctx = new InitialContext();
CompanyRemote companyRemote = (CompanyRemote) ctx.lookup("CompanyRemote");
System.out.println(companyRemote.getName());
--原子服务(函数),用于组装用于组装原子交易的基本单位,本表定义了原子服务的函数名、所属动态链接库等参数供联机处理时定位实际的业务处理函数
select * from TBL_MAPS_GFS_ATOM_SVR_INF;
select * from TBL_MAPS_GFS_ATOM_TRANS_SVC_RELATED;--配置每个流程服务处理的原子交易列表
select * from TBL_MAPS_GFS_FLOW_SVC_ATOM_TRANS_RELATED;--记录需要属于指定的原子交易
select * from TBL_MAPS_GFS_FLOW_SVC_INF;--邮箱号
--多渠道平台向外部系统的原发请求交易,根据交易信息源代码、采用的报文规范类型、商户代码等参数查找外部交易码及其对应的报文格式转换相关信息
select * from TBL_MAMGM_MSG_FMT_CONV_MTO;
select * from TBL_MAPS_GFS_FMT_GRP;--平台打解包格式转换组编号
jboss热部署,在deploy中web部署的context.xml中修改如下:
<Context cookies="true" crossContext="true" antiResourceLocking="false " antiJARLocking="false ">
操作系统通过文件系统管理文件及数据,磁盘或分区需要创建文件系统后才能为操作系统使用,创建文件系统的过程又称为格式化。
cpu 4.2g的意思是:每秒能处理4.2*1000*1000*1000次指令。
DDRIII1333的速度读取大概在8到9G左右,写的速度大概在7到8G左右。
普通硬盘的读取速度大概是100M/S左右,而固态硬盘的读取速度则是250M/S
关闭employee表的约束性检查
db2 set integrity for employee off
oracle中建立延迟约束,提交时才做约束检查
ALTER TABLE MV_T ADD CONSTRAINT UN_MV_T_NAME UNIQUE (NAME) DEFERRABLE;
db2 import数据时出错:
SQL3120W The field value in row "22370" and column "1" cannot be converted to
an INTEGER value, but the target column is not nullable. The row was not
loaded.
解决:如果字段值里面含回车换行的,如果以del形式export之后,import导入时都会出现这个问题。换成ixf二进制格式就没有问题了。导入速度还快。
有没有在vi 编辑文件过程中刷新命令(请高手赐教)?
解决:使用“:e”可以刷新
函数原型
void *memcpy(void *dest, const void *src, size_t n);
pcap抓包文件使用Wireshark打开
SimpleDateFormat的毫秒级表示S:yyyy-MM-dd hh:mm:ss SSS
jdk自带工具jvisualvm来查看线程
new ExecutorFilter()中调用了init(executor, MANAGEABLE_EXECUTOR),然后调用initEventTypes(IoEventType... eventTypes),由于eventTypes为null,因此eventTypes = DEFAULT_EVENT_SET默认所有的IoEventType。
list.remove()会影响list中后面的取值。
jboss服务器上临时tmp目录:
/maps/usr/ma_mgm/shenlei/upjas/upjas-minimal/server/default/tmp/4sh702j-fmwloa-hkaiefdh-1-hkaigw6d-al/maps.war/com/cup/maps/portal/jpf/flex
aix上解压zip文件
/usr/java6_64/bin/jar -xvf upjas.zip
export CVSROOT=:pserver:leishen@172.17.249.63/cvsnew2
cvs login
cvs update -r V[1][0][1] UPJAS
F5负载均衡获取客户端真实ip?
首先需要在F5上配置X-Forwarded-For,然后可以通过获取"x-forwarded-for";来获取客户端的IP地址。
具体步骤:
1:Local Traffic-Profiles-Http-改“Insert XForwarded For”为Enable
2:Local Traffic-Virtual servers-点击需要改动的VS-将Type选项更改为Standard-将HTTP Profile 选项更改为Http
final_str = new String(final_str.getBytes("iso8859-1"), "gbk");
getbytes:表示编码,是指将内存中utf-16(unicode)编码的char,通过计算得到以iso8859-1表示的字节数组,
就是把一个字符char(2位)转换成若干位的过程(比如utf-8,有可能是1或者2或者3位)
newString中的gbk表示解码,是指将字节数组按照gbk的编码方式,如2个字节为一位,按照固定算法,转换成utf-16表示的char
e.printStace()没有打到server.log中的原因是不能存在两个log4j.properties。
[org.xml.sax.SAXParseException: cvc-elt.1: Cannot find the declaration of element 'Msg'.]
at javax.xml.bind.helpers.AbstractUnmarshallerImpl.createUnmarshalException(AbstractUnmarshallerImpl.java:315)
at com.sun.xml.internal.bind.v2.runtime.unmarshaller.UnmarshallerImpl.createUnmarshalException(UnmarshallerImpl.java:505)
at com.sun.xml.internal.bind.v2.runtime.unmarshaller.UnmarshallerImpl.unmarshal0(UnmarshallerImpl.java:206)
at com.sun.xml.internal.bind.v2.runtime.unmarshaller.UnmarshallerImpl.unmarshal(UnmarshallerImpl.java:173)
at javax.xml.bind.helpers.AbstractUnmarshallerImpl.unmarshal(AbstractUnmarshallerImpl.java:137)
at javax.xml.bind.helpers.AbstractUnmarshallerImpl.unmarshal(AbstractUnmarshallerImpl.java:184)
at jaxb.Testunmarshallerxml.unmarshallerXml(Testunmarshallerxml.java:82)
at jaxb.Testunmarshallerxml.main(Testunmarshallerxml.java:45)
解决:
[org.xml.sax.SAXParseException: Premature end of file.]
at javax.xml.bind.helpers.AbstractUnmarshallerImpl.createUnmarshalException(AbstractUnmarshallerImpl.java:315)
at com.sun.xml.internal.bind.v2.runtime.unmarshaller.UnmarshallerImpl.createUnmarshalException(UnmarshallerImpl.java:505)
at com.sun.xml.internal.bind.v2.runtime.unmarshaller.UnmarshallerImpl.unmarshal0(UnmarshallerImpl.java:206)
at com.sun.xml.internal.bind.v2.runtime.unmarshaller.UnmarshallerImpl.unmarshal(UnmarshallerImpl.java:173)
at javax.xml.bind.helpers.AbstractUnmarshallerImpl.unmarshal(AbstractUnmarshallerImpl.java:137)
at javax.xml.bind.helpers.AbstractUnmarshallerImpl.unmarshal(AbstractUnmarshallerImpl.java:184)
at jaxb.Testunmarshallerxml.unmarshallerXml(Testunmarshallerxml.java:82)
at jaxb.Testunmarshallerxml.main(Testunmarshallerxml.java:45)
解决:u.unmarshal(fisNetwork);传入的输入流InputStream已至流的末尾。
在dbvisualize里面直接修改db2的某个字段,如果字符串中含有||那么dbvisualize在保存时会自动计算值,但是写sql执行则不会。
用32位还是64位JDK编译出来的Class文件没区别
linux上中文显示乱码?
执行 locale -a 查看系统是否已安装utf-8字符集
执行 export LANG=zh_CNexport LC_ALL=zh_CN.utf8设置本地语言环境为utf-8
如果终端(如SecureCRT)编辑脚本时出现乱码,请设置 Menu | Options | Session Options... | Appearence | Character 为utf-8
2、LC_CTYPE
用于字符分类和字符串处理,控制所有字符的处理方式,包括字符编码,字符是单字节还是多字节,如何打印等。是最重要的一个环境变量。
项目中log4j在英文版linux下输出中文日志为乱码?
由于log4j配置文件中没有设置编码格式(encoding),所以log4j就使用系统默认编码。导致乱码。
解决方法是设置编码格式UTF-8,方法为:
log4j.appender.syslog.encoding=UTF-8
(syslog为你的logger名称)这样就可以了
没有泛型数组一说
Pair<String>[] stringPairs=new Pair<String>[10];
这种写法编译器会指定一个Cannot create a generic array of Pair<String>的错误
org.apache.commons.codec.binary.Hex
.encodeHexString()
.decodeHex()
使用AES加密时,当密钥大于128时,代码会抛出java.security.InvalidKeyException: Illegal key size or default parameters
Illegal key size or default parameters是指密钥长度是受限制的,java运行时环境读到的是受限的policy文件。文件位于${java_home}/jre/lib/security
这种限制是因为美国对软件出口的控制。
解决办法:
去掉这种限制需要下载Java Cryptography Extension (JCE) Unlimited Strength Jurisdiction Policy Files.网址如下。
下载包的readme.txt 有安装说明。就是替换${java_home}/jre/lib/security/ 下面的local_policy.jar和US_export_policy.jar
jdk 5: http://www.oracle.com/technetwork/java/javasebusiness/downloads/java-archive-downloads-java-plat-419418.html#jce_policy-1.5.0-oth-JPR
jdk6: http://www.oracle.com/technetwork/java/javase/downloads/jce-6-download-429243.html
数字签名算法是非对称加密算法和消息摘要算法的结合体。要求能够验证数据完整性、认证数据来源、抗否认。
S6209: [函数/调用]EventGetIntTransIdInf获取内部交易码信息失败,ilRc = [100]!
TBL_MAMGM_EVENT_SVC_CFG少参数
252.86有的浏览器无法访问,原因是86上不支持TLS1.0协议,把server.xml改掉之后就正常了
<Connector protocol="HTTP/1.1" SSLEnabled="true" ^M
port="11009" address="${jboss.bind.address}"^M
scheme="https" secure="true" clientAuth="false" ^M
keystoreFile="${jboss.server.home.dir}/conf/server.keystore" keystorePass="123456" keystoreType="jks" ^M
sslProtocol = "SSL" />
upjas,jms的MDB默认有15个线程在处理,该池不会增大
解决:在default\deploy\hornetq\jms-ds.xml文件中<max-pool-size>20</max-pool-size>
指定了jms的线程池大小
代码表两个:
TBL_MAMGM_FILTER_APP_CATA
TBL_MAMGM_FILTER_RULE_GRP_CATA
TBL_MAMGM_FILTER_APP_INF 过滤应用信息表
TBL_MAMGM_FILTER_APP_DET 过滤应用确定表,定义了包含多个过滤条件组
TBL_MAMGM_FILTER_RULE_GRP_INF RULE_TP 'S'-唯一过滤条件 'R'-范围过滤条件; BLKBILL_IN ‘W’-白名单 'B'-黑名单
TBL_MAMGM_FILTER_RULE_DET 定义了每个过滤条件组的具体取值
根据内部交易类型获取控制规则 控制规则检查
银行卡共有三个磁道:
一磁道 只读 信息量79位
二磁道 只读 信息量40位
三磁道 读写 信息量107位
国内银联卡的磁道格式说明:
磁道1. “%” + “99(2N)” + “16位卡号(19A)” + “^” + “凸字姓名(26A)” + “^” + “expiry_date YYMM(4N)” + “101或者501(PRMCD.SERV-CODE)” + “CARD.PVV
(5N)” + “0000000000(10N)” + “CVV(3A)” + “00(2N)”+”?”共78位数
磁道2. “;” + “16位卡号(19A)” + “=” + “expiry_date YYMM(4N)” + “106(3N,服务代码)” + “PVV(5N)” + “00(2N)” + “CVV(3A)” + “?”共39位数
磁道3. “;” + “99(2N)” + “16位卡号(19A)” + “=” + “156(国家代码3N) ”
+ “156(货币代码3N) ” + “000000000(金额指数1N&周期授权量4N&本周期余额4N) ”
+ “000000(周期开始日期4N&周期长度2N) ” + “30000000(密码重输次数1N&个人授权控
制参数6N&交换控制符1N) ” + “000000(PAN的TA和SR& SAN-1的TA和SR& SAN-2的TA和SR
,各2N) ” + “expiry_date YYMM(4N) ” + “0(卡序列号1N) ” + “=” + “0000000
00000(SAN-1,12A) ” + “=” + “000000000000(SAN-2,12A) ” + “=” + “1(传递标
志1N) ” + “000000(加密校验数6N) ” + “00000000(附加数据8N) ” + “?”共106位数
委托关系-》
TBL_MAONL_PMT_ENTRUST_INFXX表,共10张
USR_NO
USR_NO_TP
USR_NO_REGION_CD
USR_NO_REGION_ADDN_CD
上面四个字段去找TBL_MAMGM_USR_NO_BIN表,找到后端商户PARENT_MCHNT_CD,然后去商户表找到行业机构代码INDUSTRY_INS_ID_CD,再去找TBL_MAMGM_COMM_LINE_CFG获得链路,发送出去
PMT_NOTV30100101
PMT_NO_TPGD
PMT_ACCT_NO955800000000000001
PMT_ACCT_TPCD-银行卡
支付号码、支付号码类型、账户号码、账户类型
ENTRUST_ACQ_INS_ID_CD00280000
ENTRUST_TERM_IDTERN0LYC
ENTRUST_MCHNT_CD898320154110210
ENTRUST_ACPT_INS_CD_ID00280000
委托的渠道接入机构、终端、商户、受理机构代码
配置完成后读者可以通过访问: http://localhost:8088/jmx-console/ ,
输入jmx-console-roles.properties文件中定义的用户名和密码,访问jmx-console的页面。
response.sendRedirect向浏览器发送一个特殊的Header,然后由浏览器来做转向,转到指定的页面,所以用sendRedirect时,浏览器的地址栏上可以看到地址的变化
1、response.sendRedirect之后,应该紧跟一句return;
2、在使用response.sendRedirect时,前面不能有HTML输出
用<jsp:forward page=""/>则不同,它是直接在server做的,浏览器并不知道,也不和浏览器打交道,这从浏览器的地址并不变化可以看
会计里面借记什么贷记什么?
这个要根据科目的性质来判断:资产类借方记增加贷方记减少,负债类借方记减少贷方记增加,权益类借方记减少贷方记增加,收入和费用类借减贷加
JSP中包含swf文件,给swf传的参数中不能包括下划线 _
<param name="FlashVars" value="titleNm=<%=request.getParameter("titleNm")%>&syncBatNo=<%=request.getParameter("sync_bat_no")%>¶Tp=<%=request.getParameter("para_tp")%>" />
比如syncBatNo不能写成sync_Bat_No
这样在swf中就可以用如下方法取得值:
private var paratype : String;
paratype = Application.application.parameters["paraTp"];
Flex代码:在Flex中这样取其中obj 即是Java返回的Map
//输出格式为key:value
for (var itemName:Object in obj){
trace(itemName+":"+obj[itemName])
}
//输出的只是value
for each(var itemValue:Object in obj){
trace(itemValue.toString())
}
打印cookie的值:
Cookie[] cs = request.getCookies();
if(cs!=null)
for(Cookie c: cs){
logger.info("c.getComment()="+c.getComment());
logger.info("c.getDomain()="+c.getDomain());
logger.info("c.getMaxAge()="+c.getMaxAge());
logger.info("c.getName()="+c.getName());
logger.info("c.getPath()="+c.getPath());
logger.info("c.getSecure()="+c.getSecure());
logger.info("c.getValue()="+c.getValue());
logger.info("c.getVersion()="+c.getVersion());
logger.info("########################################");
}
新增cookie
Cookie newCook = new Cookie("HOMEPAGESTYLE","1");
newCook.setPath("/isvr");
newCook.setMaxAge(3600*24*365);
response.addCookie(newCook);
没有修改cookie的方法,只可以再addCookie一次
删除cookie就是:newCook.setMaxAge(0);
weblogic10默认连接池个数是在config/jdbc/中配置的,最小1,最大100
<initial-capacity>1</initial-capacity>
<max-capacity>100</max-capacity>
upjas的数据库连接池个数是在vi upjas_tunning_setEnv.sh中配置
MIN_POOL_SIZE=100 # initial count of db connections
MAX_POOL_SIZE=100 # max count of db connections
db2数据的最大连接个数如下查看
1、db2实例
db2 get dbm cfg
--MAX_CONNECTIONS=AUTOMATIC(MAX_COORDAGENTS)
--MAX_COORDAGENTS=AUTOMATIC(200)
两值被设置成 AUTOMATIC,认为db2系统可以承受所有的连接:
db2 update dbm cfg using MAX_COORDAGENTS AUTOMATIC;
db2 update dbm cfg using MAX_CONNECTIONS AUTOMATIC;
2、db2数据库
db2 connect to dbname user username using passwd
db2 get db cfg
--Max number of active applications (MAXAPPLS) = AUTOMATIC(323)
通过如下命令修改:
db2 update db cfg using MAXAPPLS number
通过这个命令db2 get snapshot for dbm可以看到目前db2连接池的最高个数
High water mark for agents registered = 12
Agents registered = 5
Idle agents = 4
db2 "export to ETL_MAMGM_POS_PARA_INF.ixf of ixf select * from MA_MGMDB.ETL_MAMGM_POS_PARA_INF"
db2 "import from ETL_MAMGM_POS_PARA_INF.ixf of ixf REPLACE into MA_MGMDB.ETL_MAMGM_POS_PARA_INF"
INSERT | INSERT_UPDATE | REPLACE | REPLACE_CREATE
db2 connect to mamgmdb user maps_db using glbpoc0
248.188 回导多渠道商户终端参数ismgmdb
db2 connect to ISMGMDB user isvrdb3 using isvrdb3
db2 list tablespaces show detail
db2 import from MA_ONLDB.TBL_MAONL_TERM_STATIC_INF.ixf of ixf replace into IS_MGMDB.TBL_MAONL_TERM_STATIC_INF
db2 import from MA_ONLDB.TBL_MAONL_MCHNT_STATIC_INF.ixf of ixf replace into IS_MGMDB.TBL_MAONL_MCHNT_STATIC_INF
db2 runstats on table IS_MGMDB.TBL_MAONL_MCHNT_STATIC_INF
db2 runstats on table IS_MGMDB.TBL_MAONL_TERM_STATIC_INF
db2 import from MA_MGMDB.TBL_MAMGM_MCHNT_STATIC_INF.ixf of ixf commitcount 10000 replace into IS_MGMDB.TBL_MAMGM_MCHNT_STATIC_INF
db2 import from MA_MGMDB.TBL_MAMGM_TERM_STATIC_INF.ixf of ixf commitcount 10000 replace into IS_MGMDB.TBL_MAMGM_TERM_STATIC_INF
db2 runstats on table IS_MGMDB.TBL_MAMGM_MCHNT_STATIC_INF
db2 runstats on table IS_MGMDB.TBL_MAMGM_TERM_STATIC_INF
让datagrid可以文本选择:
http://stackoverflow.com/questions/1431574/flex-selectable-text-in-datagridcolumn
文件SelectableDataGridItemRenderer.as
package com.cup.isvr.view.grid
{
import mx.controls.dataGridClasses.DataGridItemRenderer;
public class SelectableDataGridItemRenderer extends DataGridItemRenderer
{
public function SelectableDataGridItemRenderer()
{
super();
this.selectable = true;
}
}
}
用法:
<chkGrid:CheckboxDataGrid itemRenderer="com.cup.isvr.view.grid.SelectableDataGridItemRenderer" id = "dataGrid" width = "100%" height = "100%" itemClick="ControlUtil.toggleSelected(event)" doubleClickEnabled="true" itemDoubleClick="dbClicked(event)"/>
Eclipse 3.1 版本代号 IO 【木卫1,伊奥】
Eclipse 3.2 版本代号 Callisto 【木卫四,卡里斯托】
Eclipse 3.3 版本代号 Eruopa 【木卫二,欧罗巴】 2007
Eclipse 3.4 版本代号 Ganymede 【木卫三,盖尼米德】 2008
Eclipse 3.5 版本代号 Galileo 【伽利略】 2009
Eclipse 3.6 版本代号 Helios 【太阳神】(太阳之神and泰坦海泼里恩之子;阿波罗的后任.) 2010
Eclipse 3.7 版本代号 Indigo 【靛青】 2011
Eclipse 4.2 版本代号 Juno (朱诺(主神朱庇特的妻子), 鸿运当头) 2012
Eclipse 4.3 版本代号 Kepler 2013.6
如何使用JBPM5.4
1、下载Eclipse3.6 Helios,注意启动前修改eclipse.ini最后一行-Xmx256m改成-Xmx128m。
2、下载jbpm-5.4.0.Final-installer-full.zip(http://sourceforge.net/projects/jbpm/files/jBPM%205/jbpm-5.4.0.Final/)
3、解压jbpm-5.4.0.Final-installer-full\jbpm-installer\lib\org.drools.updatesite-5.5.0.Final-assembly.zip,将org.drools.updatesite-5.5.0.Final-assembly目录
拷贝到D:\eclipse3.6\dropins下
4、解压jbpm-5.4.0.Final-installer-full\jbpm-installer\lib\jbpm-5.4.0.Final-bin.zip放入某一目录,
重启eclipse后,在windows-preferences-jbpm-installed jbpm runtime中设置运行环境。
5、新建JBPM工程
命令行处理器选项设置查询
db2 list command options
设置自动提交为off
db2 update command options using c off
2014-01-24 09:35:39,306 [Thread-102852] ERROR com.cup.mtq.comm.mina.entity.tcp.MinaClient -
java.lang.NoClassDefFoundError: org/apache/mina/core/future/DefaultConnectFuture
at org.apache.mina.core.polling.AbstractPollingIoConnector.connect0(AbstractPollingIoCon
nector.java:323)
at org.apache.mina.core.service.AbstractIoConnector.connect(AbstractIoConnector.java:248
)
at org.apache.mina.core.service.AbstractIoConnector.connect(AbstractIoConnector.java:186
)
at com.cup.mtq.comm.mina.entity.tcp.MinaClient.connect(MinaClient.java:72)
at com.cup.mtq.comm.mina.entity.tcp.MinaClient.connect(MinaClient.java:37)
at com.cup.mtq.comm.mina.manager.SysMinaLinkCacheManager$MinaClientLinkReconnectThread.r
un(SysMinaLinkCacheManager.java:455)
解决:重启就好了
2014-03-04 10:42:52,139 [Thread-64] ERROR com.cup.mtq.comm.mina.entity.tcp.MinaClient -
java.lang.IllegalStateException: Waiting too long to get the classloader lock: BaseClassLoader@6f876f87{vfszip:/MAMGMAPS/usr/ma_mgmas/upjas/upjas-minimal/server/default/cup-deploy/mjc.war/}
at org.jboss.classloader.spi.base.BaseClassLoader.acquireLockFairly(BaseClassLoader.java:1106)
at org.jboss.classloader.spi.base.BaseClassLoader.loadClassFromDomain(BaseClassLoader.java:838)
at org.jboss.classloader.spi.base.BaseClassLoader.doLoadClass(BaseClassLoader.java:502)
at org.jboss.classloader.spi.base.BaseClassLoader.loadClass(BaseClassLoader.java:447)
at java.lang.ClassLoader.loadClass(ClassLoader.java:619)
at org.apache.mina.core.polling.AbstractPollingIoConnector.connect0(AbstractPollingIoConnector.java:323)
at org.apache.mina.core.service.AbstractIoConnector.connect(AbstractIoConnector.java:248)
at org.apache.mina.core.service.AbstractIoConnector.connect(AbstractIoConnector.java:186)
at com.cup.mtq.comm.mina.entity.tcp.MinaClient.connect(MinaClient.java:72)
at com.cup.mtq.comm.mina.entity.tcp.MinaClient.connect(MinaClient.java:37)
at com.cup.mtq.comm.mina.manager.SysMinaLinkCacheManager$MinaClientLinkReconnectThread.run(SysMinaLinkCacheManager.java:455)
解决:jboss内存设置的比较小。或者环境中cpu或内存不够。
安装eclipse的jquery插件:
1、Help - Find and Install :从remote site中安装插件http://www.spket.com/update/
2.下载jQuery文件,(要下载开发版本).
3. 设置spket ,Window -> Preferences -> Spket -> JavaScript Profiles -> New,输入“jQuery”点击OK;
选择“jQuery” 并点击“Add Library”然后在下拉条中选取“jQuery”; 选择 “jQuery”并点击“Add File”,然后选中你下载的jQuery.js 文件;设成Default;
4.设置js打开方式 (这一步很重要,不设置的话,也不会有jQuery的智能提示),
Window -> Preferences ->General-> Editors-> File Associations-> 选择*.js,将Spket JavaScript Editor设为Default。
xp中保存操作系统的DNS缓存记录
C:\WINDOWS\system32\drivers\etc\hosts
2014-02-21 09:51:50,472 [http-172.17.248.74-11009-4] ERROR com.cup.maps.parameter.sync.ActivationRequester - Parameter change activa
tion failed: can not deliver activation request to ParameterEvent MDB
javax.jms.JMSException: Failed to create session
at org.hornetq.core.client.impl.ClientSessionFactoryImpl.createSessionInternal(ClientSessionFactoryImpl.java:864)
at org.hornetq.core.client.impl.ClientSessionFactoryImpl.createSession(ClientSessionFactoryImpl.java:279)
at org.hornetq.jms.client.HornetQConnection.createSessionInternal(HornetQConnection.java:513)
at org.hornetq.jms.client.HornetQConnection.createSession(HornetQConnection.java:161)
at com.cup.maps.parameter.sync.ActivationRequester.activateForCommonParaSync(ActivationRequester.java:172)
at com.cup.maps.parameter.command.ActivateCommand.sendQueue(ActivateCommand.java:81)
at com.cup.maps.parameter.command.ActivateCommand.forwardOthers(ActivateCommand.java:71)
at com.cup.maps.parameter.command.AbstractCommand.execute(AbstractCommand.java:70)
at com.cup.maps.parameter.ParameterServiceBean.operTask(ParameterServiceBean.java:871)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:60)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:37)
at java.lang.reflect.Method.invoke(Method.java:611)
at org.jboss.aop.joinpoint.MethodInvocation.invokeTarget(MethodInvocation.java:122)
at org.jboss.aop.joinpoint.MethodInvocation.invokeNext(MethodInvocation.java:111)
at org.jboss.ejb3.interceptors.container.ContainerMethodInvocationWrapper.invokeNext(ContainerMethodInvocationWrapper.java:7
2)
at org.jboss.ejb3.interceptors.aop.InterceptorSequencer.invoke(InterceptorSequencer.java:76)
at org.jboss.ejb3.interceptors.aop.InterceptorSequencer.aroundInvoke(InterceptorSequencer.java:62)
at sun.reflect.GeneratedMethodAccessor300.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:37)
at java.lang.reflect.Method.invoke(Method.java:611)
at org.jboss.aop.advice.PerJoinpointAdvice.invoke(PerJoinpointAdvice.java:174)
at org.jboss.aop.joinpoint.MethodInvocation.invokeNext(MethodInvocation.java:102)
at org.jboss.ejb3.interceptors.aop.InvocationContextInterceptor.fillMethod(InvocationContextInterceptor.java:72)
at org.jboss.aop.advice.org.jboss.ejb3.interceptors.aop.InvocationContextInterceptor_z_fillMethod_549265597.invoke(Invocatio
nContextInterceptor_z_fillMethod_549265597.java)
at org.jboss.aop.joinpoint.MethodInvocation.invokeNext(MethodInvocation.java:102)
at org.jboss.ejb3.interceptors.aop.InvocationContextInterceptor.setup(InvocationContextInterceptor.java:88)
at org.jboss.aop.advice.org.jboss.ejb3.interceptors.aop.InvocationContextInterceptor_z_setup_549265597.invoke(InvocationCont
extInterceptor_z_setup_549265597.java)
at org.jboss.aop.joinpoint.MethodInvocation.invokeNext(MethodInvocation.java:102)
at org.jboss.ejb3.connectionmanager.CachedConnectionInterceptor.invoke(CachedConnectionInterceptor.java:62)
at org.jboss.aop.joinpoint.MethodInvocation.invokeNext(MethodInvocation.java:102)
at org.jboss.ejb3.entity.TransactionScopedEntityManagerInterceptor.invoke(TransactionScopedEntityManagerInterceptor.java:56)
at org.jboss.aop.joinpoint.MethodInvocation.invokeNext(MethodInvocation.java:102)
at org.jboss.ejb3.AllowedOperationsInterceptor.invoke(AllowedOperationsInterceptor.java:47)
at org.jboss.aop.joinpoint.MethodInvocation.invokeNext(MethodInvocation.java:102)
at org.jboss.ejb3.tx.NullInterceptor.invoke(NullInterceptor.java:42)
at org.jboss.aop.joinpoint.MethodInvocation.invokeNext(MethodInvocation.java:102)
at org.jboss.ejb3.stateless.StatelessInstanceInterceptor.invoke(StatelessInstanceInterceptor.java:68)
at org.jboss.aop.joinpoint.MethodInvocation.invokeNext(MethodInvocation.java:102)
at org.jboss.ejb3.stateless.StatelessInstanceInterceptor.invoke(StatelessInstanceInterceptor.java:68)
at org.jboss.aop.joinpoint.MethodInvocation.invokeNext(MethodInvocation.java:102)
at org.jboss.aspects.tx.TxPolicy.invokeInOurTx(TxPolicy.java:79)
at org.jboss.aspects.tx.TxInterceptor$Required.invoke(TxInterceptor.java:190)
at org.jboss.aop.joinpoint.MethodInvocation.invokeNext(MethodInvocation.java:102)
at org.jboss.aspects.tx.TxPropagationInterceptor.invoke(TxPropagationInterceptor.java:76)
at org.jboss.aop.joinpoint.MethodInvocation.invokeNext(MethodInvocation.java:102)
at org.jboss.ejb3.tx.NullInterceptor.invoke(NullInterceptor.java:42)
at org.jboss.aop.joinpoint.MethodInvocation.invokeNext(MethodInvocation.java:102)
at org.jboss.ejb3.security.Ejb3AuthenticationInterceptorv2.invoke(Ejb3AuthenticationInterceptorv2.java:182)
at org.jboss.aop.joinpoint.MethodInvocation.invokeNext(MethodInvocation.java:102)
at org.jboss.ejb3.ENCPropagationInterceptor.invoke(ENCPropagationInterceptor.java:41)
at org.jboss.aop.joinpoint.MethodInvocation.invokeNext(MethodInvocation.java:102)
at org.jboss.ejb3.BlockContainerShutdownInterceptor.invoke(BlockContainerShutdownInterceptor.java:67)
at org.jboss.aop.joinpoint.MethodInvocation.invokeNext(MethodInvocation.java:102)
at org.jboss.ejb3.core.context.CurrentInvocationContextInterceptor.invoke(CurrentInvocationContextInterceptor.java:47)
at org.jboss.aop.joinpoint.MethodInvocation.invokeNext(MethodInvocation.java:102)
at org.jboss.aspects.currentinvocation.CurrentInvocationInterceptor.invoke(CurrentInvocationInterceptor.java:67)
at org.jboss.aop.joinpoint.MethodInvocation.invokeNext(MethodInvocation.java:102)
at org.jboss.ejb3.interceptor.EJB3TCCLInterceptor.invoke(EJB3TCCLInterceptor.java:86)
at org.jboss.aop.joinpoint.MethodInvocation.invokeNext(MethodInvocation.java:102)
at org.jboss.ejb3.stateless.StatelessContainer.dynamicInvoke(StatelessContainer.java:363)
at org.jboss.ejb3.remoting.IsLocalInterceptor.invokeLocal(IsLocalInterceptor.java:88)
at org.jboss.ejb3.remoting.IsLocalInterceptor.invoke(IsLocalInterceptor.java:75)
at org.jboss.aop.joinpoint.MethodInvocation.invokeNext(MethodInvocation.java:102)
at org.jboss.aspects.remoting.PojiProxy.invoke(PojiProxy.java:62)
at $Proxy275.invoke(Unknown Source)
at org.jboss.ejb3.proxy.impl.handler.session.SessionProxyInvocationHandlerBase.invoke(SessionProxyInvocationHandlerBase.java
:188)
at $Proxy295.operTask(Unknown Source)
at com.cup.maps.portal.flex.ParameterFlexFacade.batchOperTask(ParameterFlexFacade.java:772)
at com.cup.maps.portal.flex.ParameterFlexFacade$$FastClassByCGLIB$$2305f44f.invoke(<generated>)
at org.springframework.cglib.proxy.MethodProxy.invoke(MethodProxy.java:204)
at org.springframework.aop.framework.CglibAopProxy$CglibMethodInvocation.invokeJoinpoint(CglibAopProxy.java:698)
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:150)
at org.springframework.aop.aspectj.MethodInvocationProceedingJoinPoint.proceed(MethodInvocationProceedingJoinPoint.java:80)
at com.cup.maps.common.AuthPermission.checkAccess(AuthPermission.java:67)
at sun.reflect.GeneratedMethodAccessor449.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:37)
at java.lang.reflect.Method.invoke(Method.java:611)
at org.springframework.aop.aspectj.AbstractAspectJAdvice.invokeAdviceMethodWithGivenArgs(AbstractAspectJAdvice.java:621)
at org.springframework.aop.aspectj.AbstractAspectJAdvice.invokeAdviceMethod(AbstractAspectJAdvice.java:610)
at org.springframework.aop.aspectj.AspectJAroundAdvice.invoke(AspectJAroundAdvice.java:65)
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:172)
at org.springframework.aop.interceptor.ExposeInvocationInterceptor.invoke(ExposeInvocationInterceptor.java:91)
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:172)
at org.springframework.aop.framework.CglibAopProxy$DynamicAdvisedInterceptor.intercept(CglibAopProxy.java:631)
at com.cup.maps.portal.flex.ParameterFlexFacade$$EnhancerByCGLIB$$ee5b83a3.batchOperTask(<generated>)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:60)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:37)
at java.lang.reflect.Method.invoke(Method.java:611)
at flex.messaging.services.remoting.adapters.JavaAdapter.invoke(JavaAdapter.java:421)
at flex.messaging.services.RemotingService.serviceMessage(RemotingService.java:183)
at flex.messaging.MessageBroker.routeMessageToService(MessageBroker.java:1503)
at flex.messaging.endpoints.AbstractEndpoint.serviceMessage(AbstractEndpoint.java:884)
at flex.messaging.endpoints.amf.MessageBrokerFilter.invoke(MessageBrokerFilter.java:121)
at flex.messaging.endpoints.amf.LegacyFilter.invoke(LegacyFilter.java:158)
at flex.messaging.endpoints.amf.SessionFilter.invoke(SessionFilter.java:44)
at flex.messaging.endpoints.amf.BatchProcessFilter.invoke(BatchProcessFilter.java:67)
at flex.messaging.endpoints.amf.SerializationFilter.invoke(SerializationFilter.java:146)
at flex.messaging.endpoints.BaseHTTPEndpoint.service(BaseHTTPEndpoint.java:278)
at flex.messaging.MessageBrokerServlet.service(MessageBrokerServlet.java:322)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:717)
at flex.messaging.MessageBrokerServlet.service(MessageBrokerServlet.java:322)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:717)
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:290)
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:206)
at com.cup.maps.portal.common.filter.SessionFilter.doFilter(SessionFilter.java:94)
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:235)
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:206)
at org.springframework.web.filter.CharacterEncodingFilter.doFilterInternal(CharacterEncodingFilter.java:88)
at org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:107)
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:235)
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:206)
at edu.yale.its.tp.cas.client.filter.CASFilter.doFilter(CASFilter.java:221)
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:235)
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:206)
at org.apache.catalina.core.StandardWrapperValve.invoke(StandardWrapperValve.java:235)
at org.apache.catalina.core.StandardContextValve.invoke(StandardContextValve.java:191)
at org.jboss.web.tomcat.security.SecurityAssociationValve.invoke(SecurityAssociationValve.java:183)
at org.jboss.web.tomcat.security.JaccContextValve.invoke(JaccContextValve.java:95)
at org.jboss.web.tomcat.security.SecurityContextEstablishmentValve.process(SecurityContextEstablishmentValve.java:126)
at org.jboss.web.tomcat.security.SecurityContextEstablishmentValve.invoke(SecurityContextEstablishmentValve.java:70)
at org.apache.catalina.core.StandardHostValve.invoke(StandardHostValve.java:127)
at org.apache.catalina.valves.ErrorReportValve.invoke(ErrorReportValve.java:102)
at org.jboss.web.tomcat.service.jca.CachedConnectionValve.invoke(CachedConnectionValve.java:158)
at org.apache.catalina.core.StandardEngineValve.invoke(StandardEngineValve.java:109)
at org.jboss.web.tomcat.service.request.ActiveRequestResponseCacheValve.internalProcess(ActiveRequestResponseCacheValve.java
:74)
at org.jboss.web.tomcat.service.request.ActiveRequestResponseCacheValve.invoke(ActiveRequestResponseCacheValve.java:47)
at org.apache.catalina.connector.CoyoteAdapter.service(CoyoteAdapter.java:330)
at org.apache.coyote.http11.Http11Processor.process(Http11Processor.java:829)
at org.apache.coyote.http11.Http11Protocol$Http11ConnectionHandler.process(Http11Protocol.java:599)
at org.apache.tomcat.util.net.JIoEndpoint$Worker.run(JIoEndpoint.java:451)
at java.lang.Thread.run(Thread.java:736)
Caused by:
HornetQException[errorCode=0 message=Failed to create session]
... 129 more
Caused by:
java.lang.IllegalStateException: Connection is null
at org.hornetq.core.client.impl.ClientSessionFactoryImpl.createSessionInternal(ClientSessionFactoryImpl.java:745)
... 128 more
原因是jms的connection的session失效了
server.log里面报错:
21 Feb 2014 16:53:21,965 TRACE [org.jboss.management.j2ee.MBean] Failed to initialize state from: 'jboss.jmx:type=adaptor,name=Invok
er,protocol=jrmp,service=proxyFactory' : javax.management.InstanceNotFoundException : jboss.jmx:type=adaptor,name=Invoker,protocol=j
rmp,service=proxyFactory is not registered.
21 Feb 2014 16:53:21,965 DEBUG [org.jboss.management.j2ee.deployers.ServiceModuleJSR77Deployer] Create MBean, name: jboss.jmx:type=a
daptor,name=Invoker,protocol=jrmp,service=proxyFactory, SAR Module: jboss.management.local:J2EEServer=Local,j2eeType=ServiceModule,n
ame=jmx-invoker-service.xml
21 Feb 2014 16:53:21,967 DEBUG [org.jboss.management.j2ee.MBean] postRegister(), parent: jboss.management.local:J2EEServer=Local,j2e
eType=ServiceModule,name=jmx-invoker-service.xml
21 Feb 2014 16:53:21,968 DEBUG [org.jboss.management.j2ee.MBean] Failed to register as listener of: jboss.jmx:type=adaptor,name=MBea
nProxyRemote,protocol=jrmp
解决是:maven打包前clean一下就解决了,原因不明。
英特尔至强E5,服务器CPU(Xeon E5 系列CPU)
SCSI即小型计算机系统接口。
小型计算机系统接口(英语:Small Computer System Interface; 简写:SCSI),
一种用于计算机和智能设备之间(硬盘、软驱、光驱、打印机、扫描仪等)系统级接口的独立处理器标准。
SCSI是一种智能的通用接口标准。它是各种计算机与外部设备之间的接口标准。
除了SCSI,IDE也是一种极为常用的接口。
MTQJ报错?
java.lang.ArrayIndexOutOfBoundsException: Array index out of range: 512
at java.lang.System.arraycopy(Native Method)
at java.io.OutputStreamWriter.write(OutputStreamWriter.java:261)
at java.io.Writer.write(Writer.java:151)
at org.apache.log4j.helpers.CountingQuietWriter.write(CountingQuietWriter.java:44)
at org.apache.log4j.WriterAppender.subAppend(WriterAppender.java:301)
at org.apache.log4j.RollingFileAppender.subAppend(RollingFileAppender.java:236)
at org.apache.log4j.WriterAppender.append(WriterAppender.java:159)
at org.apache.log4j.AppenderSkeleton.doAppend(AppenderSkeleton.java:230)
at org.apache.log4j.helpers.AppenderAttachableImpl.appendLoopOnAppenders(AppenderAttachableImpl.java:65)
at org.apache.log4j.Category.callAppenders(Category.java:203)
at org.apache.log4j.Category.forcedLog(Category.java:388)
at org.apache.log4j.Category.info(Category.java:680)
at com.cup.mtq.log.LogManager$LogOutputThread.run(LogManager.java:129)
java.lang.ArrayIndexOutOfBoundsException: Array index out of range: 512
at java.lang.System.arraycopy(Native Method)
at java.io.OutputStreamWriter.write(OutputStreamWriter.java:261)
at java.io.Writer.write(Writer.java:151)
at org.apache.log4j.helpers.CountingQuietWriter.write(CountingQuietWriter.java:44)
at org.apache.log4j.WriterAppender.subAppend(
解决:磁盘满了,清了就好
myeclipse中spket安装jquery后没有编辑提示的原因是:
1、myeclipse要重启
2、jquery要下载开发版的
3、spket->javascript Profile中要把jquery设置成default
jsp访问时报错:编译jsp失败
org.apache.jasper.JasperException: The absolute uri: http://java.sun.com/jsp/jstl/core cannot be resolved in either web.xml or the jar files deployed with this application
org.apache.jasper.compiler.DefaultErrorHandler.jspError(DefaultErrorHandler.java:51)
org.apache.jasper.compiler.ErrorDispatcher.dispatch(ErrorDispatcher.java:409)
org.apache.jasper.compiler.ErrorDispatcher.jspError(ErrorDispatcher.java:116)
org.apache.jasper.compiler.TagLibraryInfoImpl.generateTLDLocation(TagLibraryInfoImpl.java:316)
org.apache.jasper.compiler.TagLibraryInfoImpl.<init>(TagLibraryInfoImpl.java:149)
org.apache.jasper.compiler.Parser.parseTaglibDirective(Parser.java:386)
org.apache.jasper.compiler.Parser.parseDirective(Parser.java:450)
org.apache.jasper.compiler.Parser.parseElements(Parser.java:1399)
org.apache.jasper.compiler.Parser.parse(Parser.java:130)
org.apache.jasper.compiler.ParserController.doParse(ParserController.java:255)
org.apache.jasper.compiler.ParserController.parse(ParserController.java:103)
org.apache.jasper.compiler.Compiler.generateJava(Compiler.java:185)
org.apache.jasper.compiler.Compiler.compile(Compiler.java:354)
org.apache.jasper.compiler.Compiler.compile(Compiler.java:334)
org.apache.jasper.compiler.Compiler.compile(Compiler.java:321)
org.apache.jasper.JspCompilationContext.compile(JspCompilationContext.java:592)
org.apache.jasper.servlet.JspServletWrapper.service(JspServletWrapper.java:328)
org.apache.jasper.servlet.JspServlet.serviceJspFile(JspServlet.java:313)
org.apache.jasper.servlet.JspServlet.service(JspServlet.java:260)
javax.servlet.http.HttpServlet.service(HttpServlet.java:723)
解决:换个jstl.jar包的1.2版本就好了。原因是servelt2.5版需要1.2的jstl包
CSS中点和井号:
#对应id
点对应class
jquery设置样式
$("#tt").attr("class","linkvisited");
jQuery中$("#id")只能选择第一个对象,不能选择所有相同id的元素。
通过 $("input[id='xxxx']"); 可以选择多个相同id的元素。
jQuery(elements);
我们传递一个element,然后产生一个jquery对象,这个是对象,一定要记住。我们可以把$("")看成是一个构造函数。
这就犹如java中的new 差不多.每调用一次构造函数 都是生成一个新的对象,用==比较 他们自然不会相等。
datatables 列宽 可拖动?
不支持
datatables从服务端取报错?
DataTables warning (table id = 'table1'): Requested unknown parameter '0' from the data source for row 0
解决:datatables 接收两种格式的数据,一种json格式的二维数组,另一种是json格式的数组对象,
如果是服务器端返回的json格式的数组对象,在js中需要设置mDataProp这个属性。
json数组:
var ourcountry=[["北京市"],["上海市"],["合肥市","芜湖市","蚌埠市"]];
json对象:
var zhongguo={provinces:[{name:"北京",cities:[{name:"北京市",quxian:["海淀区","朝阳区","东城区","西城区"]}]},
{name:"安徽省",cities:[{name:"芜湖市",quxian:["繁昌县","芜湖县","南陵县","三山区"]},{name:"合肥市",quxian:["肥西县","蜀山区","庐阳区"]}]},
"湖北省"
]};
jquery ui 在$("#tabs").tabs时调用了/context?
解决:删除页面中的<base href="<%=basePath%>">语句即可。原因不明
upjas调试模式(监控模式)
打开upjas调试模式:
1. 把run.conf文件中的#JAVA_OPTS="$JAVA_OPTS -Xrunjdwp:transport=dt_socket,address=8787,server=y,suspend=n" 注释去掉
2. 把jon_upjas_start文件中的
# uncomment to enable jmx remote management
#JAVA_OPTS="$JAVA_OPTS \
#-Dcom.sun.management.jmxremote.port=12345 \
#-Dcom.sun.management.jmxremote.authenticate=false \
#-Dcom.sun.management.jmxremote.ssl=false \
#-Djboss.platform.mbeanserver \
#-Djavax.management.builder.initial=org.jboss.system.server.jmx.MBeanServerBuilderImpl"
里面的注释全都去掉
3.重启upjas
aix查看网卡速率
netstat -v ent0
http keep-alive超时设置
nginx :keepalive_timeout :75s
tomcat:server.xml 中的Connector 元素中:keepAliveTimeout(单位毫秒);maxKeepAliveRequests:最大长连接个数
jboss:?
mtqj模拟性能测试端:
D:\mapsworkspace\mtqjperformancetest
mtqj打成jar包启动:
/usr/java6_64/bin/java -classpath ".:mjc-1.4.jar:slf4j-log4j12-1.6.1.jar:slf4j-api-1.6.1.jar:org.dtools.javaini-v1.1.00.jar:mina-core-2.0.7.jar:log4j-1.2.15.jar:commons-lang-2.1.jar" com.cup.mtq.Start
初始化的顺序跟Listener、Filter、Servlet在web.xml中的顺序无关
而多个Filter或多个Servlet的时候,谁的mapping在前面,谁先初始化。
如果web.xml中配置了<context-param>,初始化顺序:
context-param > Listener > Filter > Servlet
mtqj以web应用方式使用时,增加是否初始化log4j:
在web.xml中指定下面即可:
<context-param>
<param-name>log4jinit</param-name>
<param-value>false</param-value>
</context-param>
修改文件:web.xml MjcLogger MtqInitListenser
MTQJ负载均衡策略,mtqNetwork.xml中设置负载均衡策略:
1、什么都没有:轮询
2、在host上设置:loadfactor="XXX"(XXX表示0-100),表示请求数负载
3、在domain上设置:lbmethod="bytraffic",在host上设置loadfactor="XXX"(XXX表示0-100),表示按流量负载
Caused by: java.net.UnknownHostException: UnknownHostException invoking http://P570_F_3:7001/csb/shcenter/BillDomain/IntegratedServicePlatformForIndustry/IsvrBatchParaSynchNotifyService/IsvrBatchParaSynchNotifyServiceProxy: P570_F_3
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:39)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:27)
at java.lang.reflect.Constructor.newInstance(Constructor.java:513)
org.apache.cxf.interceptor.Fault: Could not send Message.
at org.apache.cxf.interceptor.MessageSenderInterceptor.handleMessage(MessageSenderInterceptor.java:48)
at org.apache.cxf.phase.PhaseInterceptorChain.doIntercept(PhaseInterceptorChain.java:271)
at org.apache.cxf.endpoint.ClientImpl.doInvoke(ClientImpl.java:531)
PreparedStatement是如何大幅度提高性能的
当一个数据库收到一个statement后,数据库引擎会先解析statement,然后检查其是否有语法错误。一旦statement被正确的解析,
数据库会选出执行statement的最优途径。遗憾的是这个计算开销非常昂贵。数据库会首先检查是否有相关的索引可以对此提供帮助,
不管是否会将一个表中的全部行都读出来。数据库对数据进行统计,然后选出最优途径。当决创建查询方案后,数据库引擎会将它执行。
存取方案(Access Plan)的生成会占用相当多的CPU。
一个perpared statement会同一个单独的数据库连接相关联。当数据库连接被关闭时prepared statement也会被丢弃
linux:
top
mysql
登陆
mysql客户端连接失败次数超过max_connect_errors次后, 会被自动锁住
查看状态变量
show global status;
查看二进制文件
show binary logs;
查看二进制日志内容
mysqlbinlog XXX
查看linux版本
lsb_release -a
lbpool是根据MySQL的复制机制设计的支持负 载均衡的JDBC连接缓冲池
d:\Program Files\MySQL\
d:\Documents and Settings\All Users\Application Data\MySQL\MySQL Server 5.5\
解决MySQL无法远程访问的3方案
1、改表法
mysql mysql -hlocalhost -uroot -p
update user set host='%' where user='root';
flush privileges;
判断mysql是主库还是从库
使用普通的driver也可以的:String driver = "com.mysql.jdbc.Driver";
使用这个url:String url = "jdbc:mysql:replication://localhost:3306,172.17.236.121:3306/test";
或者这个:String url = "jdbc:mysql://172.17.236.121:3306/test";
show global status like 'Slave_running';
System.out.println(rs.getString(1)+"="+rs.getString(2));//Slave_running=OFF off是主库、on是从库
postgre是个数据库?
采用RESOURCE_LOCAL管理事务时,要保证数据库支持事务。例如使用MySQL时,需要设置数据库的引擎类型为“InnoDB”,而“MyISAM”类型是不支持事务的。
系统异常包括RuntimeException及其子类,这些异常会导致JTA事务回滚。应用异常即CheckedException子类,不会导致回滚;但是如果应用异常标注了:
@ApplicationException(rollback=true),则JTA容器就会回滚
MapsDaoServiceBean在初始化时注入unitName = "mapsdb"的EntityManager,代码上将MapsDaoServiceBean对象保存在MAP中,导致了即使EntityManager替换了也没用
<input type="hidden" id="submittype" />
后台使用request.getParameter("submittype")取值为null,只能在jsp上使用name="submittype"属性后台才能取
.是类 #是id
id是唯一的,类是可以重用的.
比如你有多个地方样式要求一样的话,就用类.这样就不用些多个#了.
.name{.....}
<div class="name"></div>
<div class="name"></div> /*就像这样.你多个地方都想要同一个样式就这样写.
#Idname{.......}
<div id="Idname"></div> /*id只有一个.
div4=document.getElementById("fourth");
div4.className="yellow";
div没有disabled属性,因此不能简单的通过设置disabled属性达到效果。
任何对象的void finalize()方法只会被系统自动调用一次。
java的Calendar类add函数增加年时可以无限,但是数据库的time stamp类型的字段,最大值只能是9999-12-31 23:59:59.999999
前提:java用map缓存了数据库连接池返回的datasource后:
1、若数据库重启了,程序使用这个datasource时,它不为null,对程序透明,程序照常使用。
2、若数据库停了,程序使用这个datasource时,它不为null,但是在DataSource.getConnection()时报错如下:
org.jboss.util.NestedSQLException: Unable to get managed connection for jdbc/batdb; - nested throwable: (javax.resource.ResourceException: Unable to get managed connection for jdbc/batdb)
然后数据库再次启动后,缓存的datasource还是不为null,程序照常正常使用,对程序透明。
java.sql.sqlexception can not issue executeUpdate() from selects
jdbc执行语句select * from tbl_mimgm_ma_resp_cd into outfile 'd:/mysql/11.backup'报如下错误:
java.sql.SQLException:Can't create/write to file 'd:\11.backup'(Errcode:13)
解决:
1、在my.ini中[mysqld]里面添加一行:tmpdir="d:\mysql\"
2、重启mysql server后再次执行
my.ini在xp中位置如下:D:\Documents and Settings\All Users\Application Data\MySQL\MySQL Server 5.5
导出的文件若不指定绝对路径,位置是:
D:\Documents and Settings\All Users\Application Data\MySQL\MySQL Server 5.5\data\mimgmdb
其中mimgmdb是数据库名
jdbc执行语句select * from tbl_mimgm_ma_resp_cd into outfile 'd:/mysql/11.backup'报如下错误:
java.sql.SQLException:File 'd:/mysql/11.backup' already exists
解决:目前无法解决。只能先删除,再导出
jdbc执行语句select * from tbl_mimgm_ma_resp_cd into outfile d:/mysql/222.backup报如下错误:
com.mysql.jdbc.exception.jdbc4,MySQLSyntaxErrorException:You have an error in your SQL syntax;
check the manual that corresponds to your MySQL server version for the right syntax to use near
'd:/mysql/222.backup' at line 1
解决:outfile后面的文件名需要打上单引号
java.sql.SQLException: Can't get stat of '/home/mi_mgmap/upjas/upjas-minimal/bin/dbpatch/20140520115311.replace.TBL_MIMGM_TRANS_ID_INF' (Errcode: 2)
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:1078)
解决:
com.mysql.jdbc.MysqlDataTruncation: Data truncation: Incorrect datetime value: 'null' for column 'REC_UPD_TS' at row 2
at com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:4235)
解决:数据库data文件中REC_UPD_TS字段处为null值,在load时报错。
-Xss128k: 设置每个线程的堆栈大小。JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K。根据应用的线程所需内存大小进行调整。
在相同物理内 存下,减小这个值能生成更多的线程。但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右。
线程栈的大小是个双刃剑,如果设置过小,可能会出现栈溢出,特别是在该线程内有递归、大的循环时
时出现溢出的可能性更大,如果该值设置过大,就有影响到创建栈的数量,如果是多线程的应用,就会
出现内存溢出的错误
新生代 = Eden区+Survivor区(这两个比值由-XX:SurvivorRatio=8决定)
-Xmn2g:设置年轻代大小为2G
新生代GC(Minor GC),当Eden区不足以分配对象时触发
老年代GC(Major GC/Full GC),比MinorGC慢10倍以上
大对象直接进入老年代,避免大对象在Eden区和Survivor区之间复制拷贝(由-XX:PretenureSizeThreshlod=3145728B)
如果对象在Eden出生并经过第一次MinorGC后仍然存活,并且能被Survivor容纳,将被移动到Survivor空间中,并将对象年龄设为1。
对象在Survivor区中每熬过一次MinorGC,年龄就增加1岁,当它的年龄增加到一定程度(默认为15岁)时,就会被晋升到老年代。
这个年龄值可以通过参数-XX:MaxTenuringThreshold来设置。
jvm启动时的数据区域:
1、程序计数器:线程私有,较小内存,当前线程所执行的字节码的行号指示器,无OutOfMemoryError情况。
2、java虚拟机栈:线程私有,生命周期与线程相同,每个方法执行时会创建一个栈帧(Stack Frame)用于存储局部变量表、操作栈、动态链接、方法出口等。抛出StackOverflowError、OutOfMemoryError异常。
3、本地方法栈:虚拟机使用Native方法服务。
4、java堆:各线程共享区域。新生代(Eden + From Survivor + To Survivor)+老年代。抛出OutOfMemoryError。
5、方法区:各线程共享区域。又叫永久代。存储被虚拟机加载的类信息、常量、静态变量、即时编译器JIT编译后的代码。抛出OutOfMemoryError。-XX:MaxPermSize。只有sun的虚拟机需要设置,jrockit和ibm虚拟机无需设置。
6、运行时常量池:方法区的一部分;class文件中除包含类版本、字段、方法、接口等外,还有编译期生成的各种字面常量和符号引用。抛出OutOfMemoryError。
7、直接内存Direct Memory:不是虚拟机运行时数据区的一部分。java NIO引入的使用native函数库直接分配的堆外内存,
java堆里面的DirectByteBuffer对象是这块堆外内存的引用,避免了在java堆和native堆来回复制数据。
抛出OutOfMemoryError。-XX:MaxDirectMemorySize。垃圾回收器不会主动回收,只在full gc时顺便清理direct memory
实践经验:
除java堆和永久代外,下面也会占用内存,这里所有内存的总和受到操作系统进程最大内存的限制。
1、Direct Memory:OutOfMemoryError:Direct buffer memory。
2、线程堆栈:-Xss。 StackOverflowError无法分配新的栈帧;OutOfMemoryError无法建立新的线程。
3、socket缓存区。每个socket连接都有Receive和Send两个缓存区;分别占37KB和25KB内存。
4、JNI代码:使用JNI调用本地库,使用内存不在堆里面。
5、虚拟机和GC:虚拟机和GC的代码执行也消耗一定内存。
导致Gc的情况:
1、老年代(tenured)被写满
2、perm被写满
3、System.gc()的显式调用。
4、上一次GC之后heap的各域分配策略动态变化。
F5对后台应用做健康检查
1、Layer2层,F5会发送给服务器IP地址的ARP请求,服务器会响应这个ARP请求。
2、Layer3层,F5会发送给服务器ping命令,用来确认IP地址是否在网络中存在或者主机是否正常工作。
3、Layer4层,F5的负载均衡器会试图建立一个连接到服务器TCP或者UDP的某个端口,发送一个TCP SYN
请求包,并检查回应的TCP SYN ACK数据包是否收到。
upjas停止时打出
Heap
PSYoungGen total 458752K, used 62915K [0x00000000e0000000, 0x0000000100000000, 0x0000000100000000)
eden space 393216K, 16% used [0x00000000e0000000,0x00000000e3d70c08,0x00000000f8000000)
from space 65536K, 0% used [0x00000000f8000000,0x00000000f8000000,0x00000000fc000000)
to space 65536K, 0% used [0x00000000fc000000,0x00000000fc000000,0x0000000100000000)
ParOldGen total 1048576K, used 1339K [0x00000000a0000000, 0x00000000e0000000, 0x00000000e0000000)
object space 1048576K, 0% used [0x00000000a0000000,0x00000000a014ece0,0x00000000e0000000)
PSPermGen total 131072K, used 8292K [0x0000000090000000, 0x0000000098000000, 0x00000000a0000000)
object space 131072K, 6% used [0x0000000090000000,0x0000000090819370,0x0000000098000000)
管理upjas启动vm参数
14:38:19,727 INFO [ServerInfo] VM arguments:
-Dprogram.name=run.sh -XX:+UseParallelOldGC -XX:ParallelGCThreads=2
-XX:PermSize=128m -XX:MaxPermSize=256m
-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps
-Dorg.jboss.resolver.warning=true
-Dsun.rmi.dgc.client.gcInterval=3600000
-Dsun.rmi.dgc.server.gcInterval=3600000
-Dsun.lang.ClassLoader.allowArraySyntax=true
-Dorg.jboss.ejb3.remoting.IsLocalInterceptor.passByRef=true
-Ddb2.jcc.charsetDecoderEncoder=3
-Dorg.jboss.net.protocol.file.useURI=false
-DpwdServerIp=172.17.248.74
-DpwdServerPort=7000
-DpwdServerIp_bak=172.17.252.63
-DpwdServerPort_bak=11140
-Xms1536m -Xmx1536m
-Djava.net.preferIPv4Stack=true
-Djava.endorsed.dirs=/home/mi_mgmap/upjas/upjas-minimal/lib/endorsed
管理upjas启动时gc日志
2014-05-06T14:38:29.602+0800: [GC [PSYoungGen: 393216K->46465K(458752K)] 393216K->46465K(1507328K), 0.2396330 secs] [Times: user=0.39 sys=0.07, real=0.24 secs]
2014-05-06T14:38:31.725+0800: [GC [PSYoungGen: 147560K->61885K(458752K)] 147560K->61885K(1507328K), 0.2032700 secs] [Times: user=0.34 sys=0.06, real=0.20 secs]
2014-05-06T14:38:31.929+0800: [Full GC (System) [PSYoungGen: 61885K->0K(458752K)] [ParOldGen: 0K->61565K(1048576K)] 61885K->61565K(1507328K) [PSPermGen: 29108K->29067K(131072K)], 1.1917110 secs] [Times: user=2.09 sys=0.07, real=1.19 secs]
2014-05-06T14:38:39.731+0800: [GC [PSYoungGen: 393216K->35370K(458752K)] 454781K->96935K(1507328K), 0.0990800 secs] [Times: user=0.26 sys=0.01, real=0.10 secs]
2014-05-06T14:38:46.592+0800: [GC [PSYoungGen: 428586K->59203K(458752K)] 490151K->120768K(1507328K), 0.2902710 secs] [Times: user=0.54 sys=0.00, real=0.28 secs]
2014-05-06T14:38:53.579+0800: [GC [PSYoungGen: 452419K->65514K(458752K)] 513984K->150727K(1507328K), 0.3100880 secs] [Times: user=0.59 sys=0.02, real=0.31 secs]
2014-05-06T14:39:02.693+0800: [GC [PSYoungGen: 458730K->65533K(371712K)] 543943K->180368K(1420288K), 0.2337030 secs] [Times: user=0.47 sys=0.02, real=0.23 secs]
2014-05-06T14:39:05.698+0800: [GC [PSYoungGen: 371709K->75946K(415232K)] 486544K->190782K(1463808K), 0.2553100 secs] [Times: user=0.70 sys=0.00, real=0.26 secs]
jlog.properties properties file found and used:URL=file:/home/mi_mgmap/upjas/upjas-minimal/server/default/cup-deploy/appCfg/jlog.properties
log4j.properties properties file found and used:URL=file:/home/mi_mgmap/upjas/upjas-minimal/server/default/cup-deploy/appCfg/log4j.properties
2014-05-06T14:39:14.944+0800: [GC [PSYoungGen: 382122K->85144K(409152K)] 496958K->219570K(1457728K), 0.4262070 secs] [Times: user=0.70 sys=0.05, real=0.42 secs]
2014-05-06T14:39:21.885+0800: [GC [PSYoungGen: 385688K->66670K(412416K)] 520114K->231316K(1460992K), 0.5258480 secs] [Times: user=0.85 sys=0.07, real=0.52 secs]
2014-05-06T14:39:32.110+0800: [GC [PSYoungGen: 367214K->60090K(419456K)] 531860K->247241K(1468032K), 0.3460030 secs] [Times: user=0.60 sys=0.02, real=0.35 secs]
2014-05-06T14:39:41.029+0800: [GC [PSYoungGen: 372154K->54631K(416896K)] 559305K->260258K(1465472K), 0.3492870 secs] [Times: user=0.52 sys=0.03, real=0.35 secs]
defaultCasLogin:http://172.17.248.56:6008/sso/login
2014-05-06T14:39:54.952+0800: [GC [PSYoungGen: 366695K->45038K(421184K)] 572322K->269223K(1469760K), 0.3133260 secs] [Times: user=0.50 sys=0.02, real=0.31 secs]
启动时,YoungGen的大小是448M(1536*7/24);当使用到384M(即6/7的总内存时)时触发一次MinorGC
ParOldGen大小是1024M
PSPermGen大小是128M
并行(Parallel):垃圾收集线程并行工作,用户线程处理等待状态。
并发(Concurrent):用户线程与垃圾收集线程同时执行。
Parallel Scavenge收集器也被称作“吞吐量优先”收集器,新生代垃圾收集器,使用复制算法,并行处理,目标是达到一个可控的吞吐量,它的参数包括:
-XX:MaxGCPauseMillis 大于0的毫秒数,收集器尽量保证内存回收话费时间不超过该值。
-XX:GCTimeRatio 大于0小与100的整数,垃圾收集时间占总时间的比率,相当于吞吐量的倒数,默认99,就是容许最大1%(1/(99+1))的垃圾收集时间
-XX:UseAdaptiveSizePolicy 这个开关打开之后,就不需要手工指定新生代大小(-Xmn)、Eden与Survivor比例(-XX:SurvivorRatio),虚拟机动态调整。
-XX:+UseConcMarkSweepGC -XX:+UseParNewGC 使用CMS收集器,(CMS收集时的停顿时间只是收集过程中的一小部分)
Serial Old收集器,是Serial收集器的老年版本,单线程收集器,使用标记-整理算法。
Parallel Old:Parallel Scavenge的老年代版本,使用多线程和“标记-整理”算法。
CMS(Concurrent Mark Sweep)收集器是以获取最短回收停顿时间为目标的收集器,使用标记-清除算法,几种运用在互联网站或B/S系统的服务端上,重视响应速度。
优点是:并发收集(不会导致用户线程停顿)、低停顿。缺点是:对cpu资源较敏感;无法处理浮动垃圾;产生大量空间碎片。
G1收集器,基于标记-整理算法,
UseParallelOldGC = Parallel Scavenge + Parallel Old
运行日志
异常堆栈
GC日志 ibm jdk gc(xml格式) 查看工具ga441.zip
线程快照(threaddump/javacore) kill -3
堆转储快照(heapdump/dump/hprof)-XX:+HeapDumpOnOutOfMemoryError or kill -3 or jmap工具
jps:列出正在运行的虚拟机进程。 -q -m -l -v
jstat:监视虚拟机各种运行状态信息,可以显示本地或者远程虚拟机进程中的类装载、内存、垃圾收集、JIT编译等运行数据。如:jstat -gcutil pid
jinfo:实时查看或者调整各项虚拟机参数。
jmap:生成堆转储快照heapdump文件。如:jmap -dump:format=b,file=d:/eclipse.bin pid
jhat:与jmap搭配,分析heapdump文件,之后生成html文件,浏览器中键入http://localhost:7000/就可以看到分析结果。
jstack:生成虚拟机当前时刻的线程快照,是当前虚拟机内每一个线程正在执行的方法堆栈的集合。主要目的是定位线程长时间停顿的原因。如:jstack -l pid
jconsole:运行监视、故障处理
jvisualvm:除运行监视、故障处理外,还提供性能分析(双击应用程序-右边Profiler-性能分析CPU、内存)。工具-插件-可用插件,里面列出所有可用插件。BTrace动态日志。
apache在做负载均衡时要对同一sessionid分配到同一个服务器上?
系统总内存 = RAM + SWAP分区(linux)或者分页文件(aix)
java代码编译出来后形成的class文件中存储的是字节码,虚拟机通过解释方式执行字节码命令,比起C编译成本地二进制代码来说速度慢不少。
为解决慢的问题,jdk1.2以后,虚拟机内置了两个运行时编译器,如果一段java方法被调用的次数到达一定程度,就会被判定为热代码(hot spot code),从而交给
JIT(just in Time Compiler)编译器即时编译为本地代码,以提高运行速度。
虚拟机运行在-client模式时,使用代号为C1的轻量编译器,运行在-server模式下,使用代号为C2的重量级编译器,
-client,-server
这两个参数用于设置虚拟机使用何种运行模式,client模式启动比较快,但运行时性能和内存管理效率不如server模式,通常用于客户端应用程序。相反,server模式启动比client慢,但可获得更高的运行性能。
在windows上,缺省的虚拟机类型为client模式,如果要使用server模式,就需要在启动虚拟机时加-server参数,以获得更高性能,对服务器端应用,推荐采用server模式,尤其是多个CPU的系统。在Linux,Solaris上缺省采用server模式。
使用-classpath后虚拟机将不再使用CLASSPATH中的类搜索路径,如果-classpath和CLASSPATH都没有设置,则虚拟机使用当前路径(.)作为类搜索路径。
使用-XX:+DisableExplicitGC屏蔽程序主动触发的System.gc()
表 1. IBM SDK 5.0 中的 GC 策略
策略选项描述
针对吞吐量进行优化-Xgcpolicy:optthruput(可选)默认策略。对于吞吐量比短暂的 GC 停顿更重要的应用程序,通常使用这种策略。每当进行垃圾收集时,应用程序都会停顿。
针对停顿时间进行优化-Xgcpolicy:optavgpause通过并发地执行一部分垃圾收集,在高吞吐量和短 GC 停顿之间进行折中。应用程序停顿的时间更短。
分代并发-Xgcpolicy:gencon以不同方式处理短期存活的对象和长期存活的对象。采用这种策略时,具有许多短期存活对象的应用程序会表现出更短的停顿时间,同时仍然产生很好的吞吐量。
子池-Xgcpolicy:subpool采 用与默认策略相似的算法,但是采用一种比较适合多处理器计算机的分配策略。建议对于有 16 个或更多处理器的 SMP 计算机使用这种策略。这种策略只能在 IBM pSeries? 和 zSeries? 平台上使用。需要扩展到大型计算机上的应用程序可以从这种策略中受益。
ibm的分代并发:nursery(年轻代)占总javaheap的22.5%,tenured(老年代)占总javaheap的75%,还少2.5%不知道去哪里???
ibm jdk关于gc的几个配置项(upjas在这个文件里面vi upjas_all_setEnv.sh):
-verbose:gc 打开gc日志项
-verbose:gc -Xverbosegclog:gc.log 打开gc日志,并记录到bin下的gc.log文件中去
-XX:+PrintGCDetails -XX:+PrintGCDateStamps gc日志记录gc的详细信息以及时间
-Xgcpolicy:optavgpause gc策略(有几项:optthruput、optavgpause、gencon、subpool)
倒数第一行前加入:
JAVA_OPTS="$JAVA_OPTS -verbose:gc -Xverbosegclog:gc.log -XX:+PrintGCDetails -XX:+PrintGCDateStamps"
再加两个参数 -XX:+PrintGCApplicationConcurrentTime -XX:+PrintGCApplicationStoppedTime对暂停时间看得更清晰。
upjas的run.conf设置了
-Dsun.rmi.dgc.client.gcInterval=3600000 -Dsun.rmi.dgc.server.gcInterval=3600000
JConsole连接监控:此进程中未启动代理管理java进程不了什么原因?
解决:在vm arguments中添加“-Dcom.sun.management.jmxremote”
class文件结构:
1、魔数
2、class文件版本
3、常量池
4、访问标志
5、类索引、父类索引与接口索引集合
6、字段表集合
7、方法表集合
8、属性表集合
方法的描述与字段的描述几乎一致,依次包括了访问标志(acess_flags)、名称索引(name_index)、描述符索引(descriptor_index)、属性表集合(attributes)
打印class文件结构工具:
javap -verbose Testjavap
结果:
Compiled from "Testjavap.java"
public class Testjavap extends java.lang.Object
SourceFile: "Testjavap.java"
minor version: 0
major version: 50
Constant pool:
const #1 = class #2; // Testjavap
const #2 = Asciz Testjavap;
const #3 = class #4; // java/lang/Object
const #4 = Asciz java/lang/Object;
const #5 = Asciz i;
const #6 = Asciz I;
const #7 = Asciz <init>;
const #8 = Asciz ()V;
const #9 = Asciz Code;
const #10 = Method #3.#11; // java/lang/Object."<init>":()V
const #11 = NameAndType #7:#8;// "<init>":()V
const #12 = Field #1.#13; // Testjavap.i:I
const #13 = NameAndType #5:#6;// i:I
const #14 = Asciz LineNumberTable;
const #15 = Asciz LocalVariableTable;
const #16 = Asciz this;
const #17 = Asciz LTestjavap;;
const #18 = Asciz main;
const #19 = Asciz ([Ljava/lang/String;)V;
const #20 = Asciz args;
const #21 = Asciz [Ljava/lang/String;;
const #22 = Asciz SourceFile;
const #23 = Asciz Testjavap.java;
{
public int i;
public Testjavap();
Code:
Stack=2, Locals=1, Args_size=1
0: aload_0
1: invokespecial #10; //Method java/lang/Object."<init>":()V
4: aload_0
5: iconst_0
6: putfield #12; //Field i:I
9: return
LineNumberTable:
line 2: 0
line 4: 4
line 2: 9
LocalVariableTable:
Start Length Slot Name Signature
0 10 0 this LTestjavap;
public static void main(java.lang.String[]);
Code:
Stack=0, Locals=1, Args_size=1
0: return
LineNumberTable:
line 11: 0
LocalVariableTable:
Start Length Slot Name Signature
0 1 0 args [Ljava/lang/String;
}
eclipse中编译class的major_version属性设置在:
window-Preferences-java-Compiler-Configure Project Specific Settings-选择某一项目
- ok - “Compiler compliance level”选择6.0 - ok即可。
DK 编译器版本target 参数十六进制 minor.major十进制 minor.major
jdk1.1.8不能带 target 参数00 03 00 2D45.3
jdk1.2.2不带(默认为 -target 1.1)00 03 00 2D45.3
jdk1.2.2-target 1.200 00 00 2E46.0
jdk1.3.1_19不带(默认为 -target 1.1)00 03 00 2D45.3
jdk1.3.1_19-target 1.300 00 00 2F47.0
j2sdk1.4.2_10不带(默认为 -target 1.2)00 00 00 2E46.0
j2sdk1.4.2_10-target 1.400 00 00 3048.0
jdk1.5.0_11不带(默认为 -target 1.5)00 00 00 3149.0
jdk1.5.0_11-target 1.4 -source 1.400 00 00 3048.0
jdk1.6.0_01不带(默认为 -target 1.6)00 00 00 3250.0
jdk1.6.0_01-target 1.500 00 00 3149.0
jdk1.6.0_01-target 1.4 -source 1.400 00 00 3048.0
jdk1.7.0不带(默认为 -target 1.6)00 00 00 3250.0
jdk1.7.0-target 1.700 00 00 3351.0
jdk1.7.0-target 1.4 -source 1.400 00 00 3048.0
Apache Harmony 5.0M3不带(默认为 -target 1.2)00 00 00 2E46.0
Apache Harmony 5.0M3-target 1.400 00 00 3048.0
class文件类加载的生命周期:
1、加载
2、连接:验证、准备、解析
3、初始化
4、使用
5、卸载
只有遇到以下四种情况jvm才会立即对类进行初始化:
1、遇到new、getstatic、putstatic、invokestatic这四条字节码指令。
2、使用java.lang.reflect包的方法对类进行反射调用
3、当初始化一个类时,如果发现其父类没有进行初始化,需要先初始化其父类
4、当虚拟机启动时,用户需要指定一个要执行的类(包含main方法的那个类),虚拟机会先初始化这个主类。
除此之外,引用类的方式是被动引用,不会触发初始化:
1、通过子类引用父类的静态字段,不会导致子类初始化
2、通过数组定义来引用类,不会触发此类的初始化
3、调用别的类的常量,在编译时直接进入类的常量池,因此不会触发类的初始化。
<clinit>()方法是由编译器自动收集类中的所有类变量的赋值动作和静态语块(static{})中的语句合并而成,与类的构造函数(init())不同,
父类的<clinit>()方法先执行。
执行接口的<clinit>()方法不需要先执行父接口的<clinit>()方法。
虚拟机会保证一个类的<clinit>()方法在多线程环境中被正确的加锁和同步。
类加载器:
1、启动类加载器(Bottstrap ClassLoader)负责将存放在<JAVA_HOME>\lib目录中的,或者被-Xbootclasspath参数指定的路径中的,且被虚拟机识别的(严格按照文件名,如rt.jar)
2、扩展类加载器(Extension ClassLoader)负责加载<JAVA_HOME>\lib\ext目录中的,或者被java.ext.dirs系统变量所指定的路径中的所有类库
3、应用程序类加载器(Application ClassLoader)负责加载classpath中所指定的类库。
每一个栈帧都包括了局部变量表、操作数栈、动态连接、方法返回地址和一些额外的附加信息,在编译时,栈帧需要多大的局部变量表、多深的操作数栈都已经完全确定了。
java虚拟机提供了四条方法调用字节码指令:
1、invokestatic:调用静态方法。
2、invokespecial:调用实例构造器init方法、私有方法、父类方法。
3、invokevirtual:调用所有虚方法。
4、invokeinterface:调用接口方法,在运行时确定一个实现此接口的对象。
重载参数匹配优先级
char
int
long
Character
Serializable
Object
char... arg(变长参数的优先级最低)
变量被定义成volatile后具有两种特性;
1、保证此变量对所有线程可见:当前一线程修改此变量值时,另外的线程立即得知,普通变量在线程间传递需要通过主存完成。
showdown(){}停止线程这类场景很适合volatile来控制并发,调用showdown时可以保证所有线程立即停下。
2、禁止指令重排序化:在一个线程的方法执行过程中,赋值或者声明语句可能被重新排序,加了volatile后可以避免此情况
java内存模型定义了如何在工作内存和主内存间相互操作的的八个操作,要求lock、unlock、read、load、assign、use、store、write八个操作都具有原子性。
lock:作用于主内存的变量,把一个变量标识为一条线程独占的状态。
unlock:解锁,作用于主内存的变量,把一个处于锁定状态的变量释放出来。
read:作用于主内存的变量,把一个变量的值从主内存传输到线程的工作内存中。
load:作用于工作内存的变量,把read操作从主内存中得到的变量值放入工作内存的变量副本中。
use:作用于工作内存的变量,把工作内存中一个变量的值传递给执行引擎。
assign:作用于工作内存的变量,把一个执行引擎接收到的值赋给工作内存的变量。
store:作用于工作内存的变量,把工作内存的一个变量值传送到主内存中。
write:作用于主内存的变量,把store操作从工作内存中得到的变量的值放入主内存的变量中。
把一个变量从主内存复制到工作内存,要顺序执行read和load操作。把变量从工作内存同步到主内存,要顺序执行store和write操作。
java内存模型只要求两个操作要按顺序执行,并不保证必须是连续执行的。
并发的三个特性是:原子性、可见性、有序性。
java的线程是被映射到系统的原生线程来实现的。java提供10个级别的线程优先级(10最高,1最低),windows只有7种
线程安全程度从高到低:
1、不可变:Immutable,如:java.lang.String java.lang.Integer(此类中定义了private final int value;)
2、绝对线程安全:
3、相对线程安全:Vector HashTable Collections的synchronizedCollection()方法包装的集合
4、线程兼容:ArrayList HashMap 对象本身并不是线程安全的,但是通过调用端正确的使用,保证并发环境安全的使用
5、线程对立:不管调用端采用如何措施,都无法在多线程环境中并发使用的代码。Thread的suspend和resume方法,如果suspend中断的线程就是即将要执行resume的那个线程,那就肯定要死锁。
线程安全的实现方法
1、互斥同步:synchronized使用操作系统互斥量来实现锁机制
2、非阻塞同步
3、无同步方案:可重入代码+线程本地存储
一些确保线程安全的方法 访问共享的,可变的数据,要求同步,为了保证变量元素的可见性,可以采用如下方法:
① 线程封闭 最简单的方式就是不共享数据,如果数据仅在单线程中访问,就不需要任何同步。线程封闭技术是实现线程安全的最简单的方式,当对象封闭在一个线程中,
这种做法会自动成为线程安全的,即使被封闭的对象本身并不是。比如JDBC的连接池,虽然JDBC本身规范并没有要求Connection对象是线程安全的,但是在典型的服务器
应用中,线程总是从池中获得一个Connection对象,并且用它处理一个单一的请求,最后把它归还,每个线程都会同步地处理大多数请求,而且在Connection对象在被
归还前,池不会将它再分配给其他线程。
② 栈限制 将变量限制在方法中。
③ ThreadLocal 它允许将变量和线程关联在一起,使得每个线程都有一份单独的拷贝。
④ 不可变性 不可变对象永远是线程安全的,一个对象是不可变的饿,要求它的状态创建后不会改变,所有域都是final类型,并且,它被正确创建。
StringBuffer的append方法是加上synchronized的。
JAVA编译期优化:
几乎没有
javac将java代码转变为字节码的编译器称作前端编译器。
JAVA运行期优化:
当程序需要迅速启动和执行时,解释器可以首先发挥作用,随着时间推移,编译器逐渐发挥作用,把越来越多的代码编译成本地代码,提高执行效率。
-Xint强制虚拟机运行于解释模式
-Xcomp强制虚拟机运行于编译模式
热点代码被执行client模式是1500次,server模式下是10000次,超过这个数将会触发JIT编译。这个次数是一段时间的被调用次数。使用-XX:CounterHalfLifeTime参数设置半衰期时间单位是秒。
-XX:-BackgroundCompilation来禁止后台JIT编译
-XX:+PrintCompilation要求虚拟机在即时编译时将编译成本地代码的方法名打印出来。(debug版的虚拟机支持)
-XX:+PrintInlining要求虚拟机输出内联信息。
JIT优化有很多技术,包括:
1、公共子表达式消除:b*c和c*b是一组公共表达式。
2、数组边界检查消除:访问数组元素foo[i]时系统会自动进行上下界的范围检查,否则会抛出ArrayIndexOutOfBoundsExcepiton,
如果编译器通过分析数据流判断循环变量的取值范围永远在[0,foo.length)之内,就可以把数组的上下界检查消除掉。
3、方法内联:把目标方法的代码复制到调用的方法中,避免发生真是的方法调用。只有使用了invokespecial指令调用的私有方法、实例构造器、父类方法和使用
invokestatic指令进行调用的静态方法、使用invokevirtual指令的被final修饰的方法才能内联。
java大部分方法都是虚方法。
激进优化:”类型继承关系分析CHA“技术,查询此方法是否有多个版本可供选择,如果只有一个版本,可以进行内联。如果加载了导致继承关系发生变化的新类,
需要抛弃已编译的代码,退回到解释状态执行,或者重新编译;如果有多个版本,编译器将会做最后一次努力。
4、逃逸分析:分析对象动态作用域。如果能证明一个对象不会逃逸到方法或者线程之外,那么可以在栈上分配对象;
如果能确认一个变量不会逃逸出线程,无法被其它线程访问,那么对此变量的同步措施就可消除;
把一个java对象拆散,根据访问情况,将其成员变量恢复到原始类型访问,叫标量替换,如果进一步证明对象不会逃逸,
那么虚拟机可能不会创建这个对象,使用成员变量代替,在栈上分配(栈上存储的数据很大机会会被虚拟机分配至物理机器的高速寄存器中存储)。
-XX:DoEscapeAnalysis开启逃逸分析
-XX:+PrintEscapeAnalysis查看分析结果
-XX:+EliminateAllocations开启标量替换
-XX:+EliminateLocks开启同步消除
-XX:+PrintEliminateAllocations 查看标量的替换情况
java虚拟机家族:
sun hotspot:sun jdk1.3后的默认虚拟机。
bea JRockit:bea公司专注于服务端应用,内部不含解释器的实现,全部代码都靠JIT。
ibm J9:ibm单独开发的jvm
apache harmony:间接催生了google android平台的Dalvik虚拟机(嵌入式)。
apache提供了一个工具htcacheclean来清理由mod_disk_cache模块生成的缓存。
htcacheclean -p 目录 -l 50k
linux下最大文件描述符的限制有两个方面,一个是用户级的限制,另外一个则是系统级限制。
以下是查看Linux文件描述符的三种方式:
[root@localhost ~]# sysctl -a | grep -i file-max --color
fs.file-max = 392036
[root@localhost ~]# cat /proc/sys/fs/file-max
392036
[root@localhost ~]# ulimit -n
1024
查看当前进程的文件描述符限制linux:
vi /proc/[pid]/limits
apache的错误日志由核心模块mod_core提供。
LogLevel指定记录错误级别:emerg、alert、crit、error、warn、notice、info、debug
默认错误文件放在ServerRoot的logs目录中,使用ErrorLog来重新指定新位置或文件名。关闭错误日志:ErrorLog /dev/null
AB测试服务器性能
D:\Program Files\Apache Software Foundation\Apache2.2\bin>ab -n 100 -c 10 http://172.17.254.155:11000/mjc/
ab -n 100 -c 50 http://146.240.25.40:12000/wcg/webtest/1?a=1
ab -n 100 -c 50 http://146.240.25.39:4488/
ab -n 100 -c 50 http://146.240.25.40:4488/
ab -n 10000 -c 10 http://172.17.248.74:11000/test/webtrans
ab -n 100 -c 50 http://146.240.25.39:12000/test/webtrans
报class "org.apache.log4j.PropertyConfigurator"'s signer information does not...
博客分类: tomcat
Apachelog4j
今天将tomcat5.5中的工程放在tomcat6.0里跑,报:
class "org.apache.log4j.PropertyConfigurator"'s signer information does not。。。。。
郁闷了,仔细看似乎是log4j的问题,其实不然,检查jftp.jar包,发现它里面也有log4j的包,可能是冲突了,于是干脆把jftp.jar包删了,重启,没事了!阿门!
但是不知道jftp.jar做什么用的,这样删掉会不会出问题,为了保险起见删掉jftp.jar里面包含有Apache的代码,因为我的Project也有Apache的jar,估计是冲突。将jftp.jar里面的所有org包下的class都删掉。
jftp.jar这个包初看好像是用ftp做上传功能用的,如果没用到全删。免得以后再出这样的问题。
mtqj的web.xml中配置了如下语句,即可使得mtqj不会初始化log4j:
<context-param>
<param-name>log4jinit</param-name>
<param-value>false</param-value>
</context-param>
<listener>
<!-- 指定Listener 的实现类-->
<listener-class>com.cup.mtq.MtqInitListener</listener-class>
</listener>
wcg.war应用启动,读CommPacket.ini文件时,nohup报错
java.lang.IllegalArgumentException: URI scheme is not "file"
解决:web-inf/classes里面添加了mtqCfg的目录
eclipse中报错没找到.class file等?
解决:Project-> Build Automatically
Tomcat一个小时进行一次 Full GC,正常么?3
2014-06-08T04:33:07.721+0800: [GC [PSYoungGen: 253229K->64K(509248K)] 327975K->74809K(1557824K), 0.0392510 secs] [Times: user=0.08 sys=0.00, real=0.04 secs]
2014-06-08T04:33:07.761+0800: [Full GC (System) [PSYoungGen: 64K->0K(509248K)] [ParOldGen: 74745K->74745K(1048576K)] 74809K->74745K(1557824K) [PSPermGen: 54430K->54429K(131072K)], 1.5088410 secs] [Times: user=2.82 sys=0.00, real=1.51 secs]
2014-06-08T05:33:09.273+0800: [GC [PSYoungGen: 253178K->96K(512448K)] 327924K->74841K(1561024K), 0.0258150 secs] [Times: user=0.04 sys=0.00, real=0.02 secs]
2014-06-08T05:33:09.299+0800: [Full GC (System) [PSYoungGen: 96K->0K(512448K)] [ParOldGen: 74745K->74746K(1048576K)] 74841K->74746K(1561024K) [PSPermGen: 54430K->54429K(131072K)], 1.3636130 secs] [Times: user=2.65 sys=0.00, real=1.37 secs]
解决:Full GC (System)表明是程序中显示调用的gc。
一个小时一次,是tomcat的一个bug,不是你程序的问题,通过参数-XX:+DisableExplicitGC 就能去掉这一个小时一次的FGC。当然也有其他很多方法
org.apache.cxf.binding.soap.SoapFault: Unmarshalling Error: unexpected element (uri:"", local:"others"). Expected elements are <{}baseDomainName>,<{}serviceName>,<{}timeout>,<{}baseHostName>,<{}remoteDomainName>,<{}isFile>,<{}remoteHostName>,<{}systemName>,<{}data>,<{}fileContent>
at org.apache.cxf.binding.soap.interceptor.Soap11FaultInInterceptor.unmarshalFault(Soap11FaultInInterceptor.java:75)
jaxb无法处理xml<->HashMap转换
jaxb在做xml与object互转时需要要如下事情
1、jdk1.6以上自带jaxb工具包
2、首先定义xsd文件
3、在windows的cmd里面执行命令,生成xsd文件中定义的元素对应的java类
xjc XXX.xsd -p 包名
例如:xjc mtqNetwork.xsd -p jaxb
4、此时就可以写测试程序了:请见jaxb/Test.java
cxf无法处理HashMap的入参。解决方法是给HashMap参数做个适配器,把JAXB不支持的对象类型(除了HashMap还有TimeStamp)转换方法重写下。本质上是把HashMap转成String传输。
1、新建类MapAdapter:(需要xstream-1.3.1.jar包)
package com.cup.wcg;
import java.util.HashMap;
import java.util.Map;
import javax.xml.bind.annotation.XmlAccessType;
import javax.xml.bind.annotation.XmlAccessorType;
import javax.xml.bind.annotation.XmlType;
import javax.xml.bind.annotation.adapters.XmlAdapter;
import com.thoughtworks.xstream.XStream;
import com.thoughtworks.xstream.io.xml.DomDriver;
/**
* <数据模型转换>
* <Map<String,Object> 与 String之间的转换>
*
* @author Owen
* @version [版本号, Apr 28, 2010]
* @see [相关类/方法]
* @since [产品/模块版本]
*/
@XmlType(name = "MapAdapter")
@XmlAccessorType(XmlAccessType.FIELD)
public class MapAdapter extends XmlAdapter<String, Map<String, Object>>
{
/** *//**
* Convert a bound type to a value type.
* 转换JAXB不支持的对象类型为JAXB支持的对象类型
*
* @param map map
* The value to be convereted. Can be null.
* @return String
* @throws Exception
* if there's an error during the conversion. The caller is responsible for
* reporting the error to the user through {@link javax.xml.bind.ValidationEventHandler}.
*/
public String marshal(Map<String, Object> map)
throws Exception
{
XStream xs = new XStream(new DomDriver());
return xs.toXML(map);
}
/** *//**
* Convert a value type to a bound type.
* 转换JAXB支持的对象类型为JAXB不支持的的类型
*
* @param model
* The value to be converted. Can be null.
* @return Map<String,Object>
* @throws Exception
* if there's an error during the conversion. The caller is responsible for
* reporting the error to the user through {@link javax.xml.bind.ValidationEventHandler}.
*/
@SuppressWarnings("unchecked")
public Map<String, Object> unmarshal(String model)
throws Exception
{
XStream xs = new XStream(new DomDriver());
return (HashMap)xs.fromXML(model);
}
}
2、创建webservice中带HashMap的入参:
@WebMethod
public String callByMap(@XmlJavaTypeAdapter(com.cup.wcg.MapAdapter.class) HashMap<String,String> map){
if(map==null){
log.info("map is null");
return "map is null";
}
else{
log.info("map key="+map.get("key"));
return "map key="+map.get("key");
}
}
如果HashMap是对象中的一个属性,采用如下方式:
@XmlJavaTypeAdapter(MapAdapter.class)
public HashMap<String,String> getMap()
{
return map;
}
public void setMap(@XmlJavaTypeAdapter(MapAdapter.class) HashMap<String,String> map)
{
this.map = map;
}
3、调用时先转一把,从HashMap到String。
java.util.HashMap<String,String> map = new java.util.HashMap<String,String>();
map.put("key", "value");
XStream xs = new XStream(new DomDriver());
String s = xs.toXML(map);
System.out.println(s);
res2 = client.invoke("callByMap",s);
System.out.println("Echo responsse: " + res2[0]);
xstream-1.3.1.jar包的maven位置:
<dependency>
<groupId>com.thoughtworks.xstream</groupId>
<artifactId>xstream</artifactId>
<version>1.3.1</version>
</dependency>
报错
org.apache.cxf.binding.soap.SoapFault: Unmarshalling Error: java.lang.ClassCastException: org.apache.xerces.jaxp.DocumentBuilderFactoryImpl cannot be cast to javax.xml.parsers.DocumentBuilderFactory
at org.apache.cxf.binding.soap.interceptor.Soap11FaultInInterceptor.unmarshalFault(Soap11FaultInInterceptor.java:75)
解决:去除war包中的xml-apis-1.0.b2.jar
Exception in thread "MtqResponseProcessThread_5" java.lang.NoClassDefFoundError:org/apache/commons/lang/StringUtils
at com.cup.mtq.cache.XmlHandle.getServiceByName()
解决:缺少commons-lang-2.1.jar
IE访问前置管理报错:http://146.240.25.38:11000/mi
Network Error (tcp_error)
A communication error occurred: ""
The Web Server may be down, too busy, or experiencing other problems preventing it from responding to requests. You may wish to try again at a later time.
For assistance, contact your network support team.
解决:mi管理系统没有启动成功
android LogCat中不输出任何的信息 ?
简单的恢复方法:
1、clean logcat的内容
2、在Android 的 Devices视图,对自己的应用点一下debug。
一般这样以后Logcat 里就会突然出现很多消失了很久的log了。
mysql 查看编码格式
mysql> SHOW VARIABLES LIKE 'character_set_%';
mysql> SHOW VARIABLES LIKE 'collation_%';
修改编码格式
1. SET NAMES 'utf8';
它相当于下面的三句指令:
SET character_set_client = utf8;
SET character_set_results = utf8;
SET character_set_connection = utf8;
一般只有在访问之前执行这个代码就解决问题了,下面是创建数据库和数据表的,设置为我们自己的编码格式。
2. 创建数据库
mysql> create database name character set utf8;
3. 创建表
CREATE TABLE `type` (
`id` int(10) unsigned NOT NULL auto_increment,
`flag_deleted` enum('Y','N') character set utf8 NOT NULL default 'N',
`flag_type` int(5) NOT NULL default '0',
`type_name` varchar(50) character set utf8 NOT NULL default '',
PRIMARY KEY (`id`)
) DEFAULT CHARSET=utf8;
4. 修改数据库成utf8的.
mysql> alter database name character set utf8;
5. 修改表默认用utf8.
mysql> alter table type character set utf8;
6. 修改字段用utf8
mysql> alter table type modify type_name varchar(50) CHARACTER SET utf8;
JVM Crash 异常退出:SIGSEGV (0xb)问题定位分析?
# A fatal error has been detected by the Java Runtime Environment:
#
# SIGSEGV (0xb) at pc=0x00007fc4b5d82120, pid=4844, tid=140482762118912
#
# JRE version: 6.0_37-b06
# Java VM: Java HotSpot(TM) 64-Bit Server VM (20.12-b01 mixed mode linux-amd64 compressed oops)
# Problematic frame:
# V [libjvm.so+0x69e120] MarkSweep::IsAliveClosure::do_object(oopDesc*)+0x20
#
# If you would like to submit a bug report, please visit:
# http://java.sun.com/webapps/bugreport/crash.jsp
#
原因:系统上有两个jre环境。指定当前用户下JAVA_HOME即可。
# configuration of vms
export JAVA_HOME=${VMS_HOME}/jdk
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$CLASSPATH
高性能:high performance
高速缓存、并行计算、异地镜像
高可用
负载均衡、数据灾备、异地容灾
高可扩展
开发框架、多层设计、业务分割
大型网站技术架构:核心原理与案例分析
pdf书下载?
CDN对动态网站内容加速效果:
优化访问线路:使用CDN动态加速,在A和B之间增加一个节点C,节点C长期存在于互联网上,不管是A访问C,还是B访问C,速度都不慢;因此,加入C节点以后,会让A访问B的速度会更快。
降低资源请求
不少CDN平台已经转型成为云安全加速平台,不仅支持内容分发,同时支持防攻击、防黑,有效减少安全隐患
到你的http://www.dnspod.cn用户后台更改你的
A记录:地址记录,用来指定域名的IPv4地址(如:8.8.8.8),如果需要将域名指向一个IP地址,就需要添加A记录。
CNAME: 如果需要将域名指向另一个域名,再由另一个域名提供ip地址,就需要添加CNAME记录。
TXT:在这里可以填写任何东西,长度限制255。绝大多数的TXT记录是用来做SPF记录(反垃圾邮件)。
NS:域名服务器记录,如果需要把子域名交给其他DNS服务商解析,就需要添加NS记录。
AAAA:用来指定主机名(或域名)对应的IPv6地址(例如:ff06:0:0:0:0:0:0:c3)记录。
MX:如果需要设置邮箱,让邮箱能收到邮件,就需要添加MX记录。
URL:从一个地址301重定向到另一个地址的时候,就需要添加URL记录(注:DNSPod目前只支持显性301重定向)。
SRV:记录了哪台计算机提供了哪个服务。格式为:服务的名字、点、协议的类型,例如:_xmpp-server._tcp。
注意:你解析时"线路类型"要选择"默认"如果选择其它线路,那么有可能有些宽带不能访问你的网站.
查询本机到服务器中间经过的路由器ip地址
tracert 域名/IP
查询DNS服务器的域名解析记录?
nslookup
现在的Dns可以根据访问ip的不同把域名解析到不同的ip上的
services-config.xml中
<channel-definition id="my-secure-amf" class="mx.messaging.channels.SecureAMFChannel">
<endpoint url="https://{server.name}:{server.port}/{context.root}/messagebroker/amfsecure" class="flex.messaging.endpoints.SecureAMFEndpoint"/>
<properties>
<add-no-cache-headers>false</add-no-cache-headers>
</properties>
</channel-definition>
1、endpoint中class修改成flex.messaging.endpoints.SecureAMFEndpoint或者flex.messaging.endpoints.AMFEndpoint均可,但是不能没有。
如果是SecureAMFEndpoint客户端与服务端的报文处于加密状态,如果是AMFEndpoint则没加密,但是两个都是二进制的格式。
如果是HTTPChannel/HTTPEndpoint(需要用http访问),则双方使用HTTP/XML格式报文,如果是SecureHTTPChannel则是加密。
按我的理解,使用SecureAMFChannel是使得客户端与服务端之间建立HTTPS链路,然后使用AMFEndpoint是传输二进制对象,使用SecureAMFEndpoint则是对此对象再次进行了加密。
2、endpoint中url中的/messagebroker配置在web.xml中的servlet-mapping处:<url-pattern>/messagebroker/*</url-pattern>。因此后面的/amfsecure是可以随便写的。
3、remoting-config.xml中<default-channels>中可以配置多个,flex页面连不上第一个channel的endpoint,会退而连第二个。
通过抓包发现,对于https的链路,握手并建立链路后,上面走的报文就不能以http协议来解析了,只能按照TCP来解包。
linux
vmstat 报告虚拟内存的统计信息。
Linux在计算进程情况时不将正在运行的 vmstat 自己计算进去。
vmstat对系统的虚拟内存、进程、CPU活动进行监视,同时它也对磁盘和forks和vforks操作的个数进行汇总。
不足是vmstat不能对某个进程进行深入分析,它仅是一对系统的整体情况进行分析。
例如:[angel@home /angel]# vmstat
procs memory swap io system cpu
r b w swpd free buff cache si so bi bo in cs us sy id
0 0 0 7180 1852 56092 48400 0 0 6 5 24 8 0 0 18
其中:
Procs
r:等待运行的进程数
b:处在非中断睡眠状态的进程数
w:被交换出去的可运行的进程数。
Memory
swpd:虚拟内存使用情况,单位:KB
free:空闲的内存,单位KB
buff:被用来做为缓存的内存数,单位:KB
Swap
si:从磁盘交换到内存的交换页数量,单位:KB/秒
so:从内存交换到磁盘的交换页数量,单位:KB/秒
IO
bi:发送到块设备(也就是硬盘,因为硬盘是块设备)的块数,单位:块/秒
bo:从块设备接收到的块数,单位:块/秒 从块设备收到的块数,单位:块/秒
System
in:每秒的中断数,包括时钟中断
cs:每秒的环境(上下文)切换次数
CPU按CPU的总使用百分比来显示
us: CPU使用时间
sy: CPU系统使用时间
id:闲置时间
wa:cpu等待IO的时间(如果wa的值很高而且虚拟内存基本没有使用,则说明硬盘的速度是性能的一个瓶颈,此时应该更换一个速度更快的硬盘)
查看linux上某个进程的详细信息
ps aux
查看linux上某端口是哪个进程
netstat -nltp |grep 80
lsof -i:80 (还可以看到是哪个用户启的)
fuser -n tcp 80
Logging Error: Caught an IOException
java.io.IOException: 系统资源不足,无法完成请求的服务。
CET时区,GMT时区
⑴Greenwich Mean Time (GMT)格林尼治标准时间英国、爱尔兰、冰岛和葡萄牙属于该时区。这个时区与中国北京时间的时差是8个小时,也就是说比北京时间晚8个小时。
比如,如果是北京时间的下午3:00,也就是这个时区的上午7:00。
⑵Central European Time(CET)中欧时区奥地利、比利时、克罗地亚、捷克共和国、丹麦、法国、德国、荷兰、匈牙利、卢森堡、马耳他、意大利、摩纳哥、
挪威、波兰、斯洛文尼亚、斯洛伐克、西班牙、瑞士和瑞典,都属于这个时区。
该时区与北京时间的时差是7个小时。比如,北京时间的下午3:00,那么是这个时区的上午8:00。
⑶Eastern European Time(EET)东欧时区属于这个时区的欧洲国家有:保加利亚、赛浦路斯、爱脱尼亚、芬兰、希腊、拉脱维亚、立陶宛、罗马尼亚、土耳其和乌克兰。
这个时区与北京时间的时差是6个小时。比如,北京时间的下午3:00,也就是这个时区的上午9:00。大部分欧洲国家实行夏令时(Summer Time or DST)。
三月份的最后一个周未是夏令时的开始,这一天他们把时钟往后调一个小时,比如2:00am,他们调整为3:00am。十月份的最后一个周未是夏令时的结束,
这一天他们把时钟往前调一个小时,比如2:00am,他们调整为1:00am。
通过kill -3 进程号能生成javacore....txt日志,但是没法生成.phd文件。
而.phd文件是JVM内存映射文件,获取它才能分析此时JVM内存的情况,进而分析出服务器宕机的原因。
对于IBM JDK需要做以下设置:
1.设置JVM参数:
-XX:+HeapDumpOnOutOfMemoryError -XX:+HeapDumpOnCtrlBreak
2.设置操作系统环境变量:
export IBM_HEAP_DUMP=true
export IBM_HEAPDUMP=true
export IBM_HEAPDUMP_OUTOFMEMORY=true
export IBM_JAVADUMP_OUTOFMEMORY=true
export IBM_JAVACORE_OUTOFMEMORY=true
重启服务器。如果这样仍然解决不了问题,则需要在服务器启动脚本添加一行:
#!/bin/ksh
#...
set -m
HP JDK生成Heapdump文件需要在在环境变量上,加上export _JAVA_HEAPDUMP=1
Thread Dump分析
通过分析Thread Dump,可以了解JVM到底有哪些线程正在工作,有助于找出死锁,性能低下的原因。
Sun HotSpot有两种方式:
jstack pid > /tmp/my_thread_dump.log (生成的是文本文件,直接看即可。)
kill -3 pid, dump文本会生成在标准输出中,在upjas1.x中就是$UPJAS_HOME/bin/nohup.out中,需要手工截取
IBM J9:
kill -3 pid, thread dump文本会生成在类似 javacore.20131223.135411.7130.0002.txt 的文件中
Heap Dump分析
通过分析Heap Dump,可以了解JVM中到底哪些对象占用了大量内存,有助于定位内存泄漏等问题。
Sun HotSpot:
jmap -dump:format=b,file=/tmp/mydump.hprof pid
说明
其中 /tmp/mydump.hprof 是用户自己指定的文件名。
IBM J9
kill -3 pid
heap dump会生成在类似 heapdump.20131223.135411.7130.0001.phd 的文件中
说明
kill -3 pid之所以能在upjas环境下生成heapdump,是因为upjas_all_setEnv.sh中设置了ibm J9能识别的参数: -Xdump:heap
org.apache.cxf.endpoint.Client是线程安全的,测试程序在:D:\isvrupjasworkspace\Testupjascxf\src\Test里面
WeakHashMap与HashMap的用法基本相同,区别在于:后者的key保留对象的强引用,即只要HashMap对象不被销毁,其对象所有key所引用的对象不会被垃圾回收,
HashMap也不会自动删除这些key所对应的键值对对象。但WeakHashMap的key所引用的对象没有被其他强引用变量所引用,
则这些key所引用的对象可能被回收。WeakHashMap中的每个key对象保存了实际对象的弱引用,当回收了该key所对应的实际对象后,
WeakHashMap会自动删除该key所对应的键值对。
System.gc();
//告诉垃圾收集器打算进行垃圾收集,而垃圾收集器进不进行收集是不确定的
System.runFinalization();
//强制调用已经失去引用的对象的finalize方法
用Jmeter发送TCP二进制的消息
1、tcp:右键添加-》Sampler -》TCP取样器
2、要发送二进制的话可以在TCPClient classname的这个参数中填入
org.apache.jmeter.protocol.tcp.sampler.BinaryTCPClientImpl
这样在text to send的区域直接写入HEX形式的二进制
"Java请求"是指JMeter对Java Class进行性能测试
jmeter csv data set config 使用文件中配置的参数
Jmeter日志输出和日志级别设置
Jmeter日志默认存放在%JMeter_HOME%\bin目录,文件名通常是JMeter.log。日志记录与JMeter本身运行有关的日志信息。
Jmeter使用Log4j日志组件输出日志,%JMETER_HOME%\bin\jmeter.properties中的log_level.jmeter用于控制Jmeter日志记录级别。log_level.jmeter可以设置以下日志级别:FATAL_ERROR, ERROR, WARN, INFO,DEBUG,其中FATAL_ERROR打印日志最少,DEBUG级别日志最详细
DNS协议运行在UDP协议之上,使用端口号53
确定同类业务:成本、客户矩阵
关闭 Apache 的web日志?
httpd.conf文件里面有如下配置,注掉就不记日志了
ErrorLog "logs/error_log"
CustomLog "logs/access_log" common
传统上,Linux 的先辈 Unix 还有一个环境变量:LD_LIBRARY_PATH 来处理非标准路经的共享库
apache反向代理时部分图片显示不出?
解决:图片的链接一般是img src="/mjc/resources/images/filter.gif"这种,如果apache代理配置成这样
ProxyPass /mi http://146.240.25.38:11000/mjc
ProxyPassReverse /mi http://146.240.25.38:11000/mjc
当使用http://146.240.25.38:4488/mi访问网站时,图片的链接变成了http://146.240.25.38:4488/mjc/resources/images/filter.gif就无法成功代理。
只能改成如下配置:
ProxyPass /mjc http://146.240.25.38:11000/mjc
ProxyPassReverse /mjc http://146.240.25.38:11000/mjc
wget命令测试http服务
浏览器关了,但是apache上https的端口还有很多状态在CLOSE_WAIT、TIME_WAIT?
问题:使用apache做类似于F5的角色的方法?(访问通讯协议:浏览器--https-->APACHE--http-->管理mgm server)
1、apache上安装、配置ssl
略,参考:学习\apache2.2和php5的安装使用\linux上安装apache2.2\(可行)Linux上Apache服务器的搭建与配置手册(包含openssl安装及ssl代理+ssl证书).doc
2、apache/conf/extra> vi httpd-ssl.conf文件中</VirtualHost>之前配置如下:
SSLProxyEngine on
ProxyRequests off
ProxyPreserveHost on
ProxyPass /maps http://172.17.248.186:11000/maps
ProxyPassReverse /maps http://172.17.248.186:11000/maps
3、管理要做相应修改,使得登陆时sso会跳到正确地址。
172.17.248.186的maps的appCfg/securityClient.properties中配置:
146.240.25.38=https://172.17.248.33:4433
(其中146.240.25.38是代理apache的ip,172.17.248.186上安装了管理应用,其flex页面必须使用HTTPS才能打开)
4、浏览器访问:
https://146.240.25.38:4489/maps(4489是代理apache上https端口)
问题:使用apache访问外网https方法?目前只会单向的,(访问通讯协议:应用--http-->APACHE--https-->外部HTTPS SERVER)
1、apache上安装、配置ssl
同上,例外是此处可不用打开下面这个配置,也无需配置此文件:
#Include conf/extra/httpd-ssl.conf
2、apache/conf > vi httpd.conf文件配置:
SSLProxyEngine on
ProxyRequests off
ProxyPreserveHost on
ProxyPass /mjc https://172.17.248.185:11009/mjc
ProxyPassReverse /mjc https://172.17.248.185:11009/mjc
3、浏览器使用http://146.240.25.38:4488/mjc即可访问
(其中146.240.25.38是代理apache的ip,4488是其http端口,172.17.248.185表示开启了HTTPS端口的外部应用)
双向https
请求http的形式发送到apache上,通过apache服务器继续以https形式去往外部,调用其他公司为银联提供的服务,双向加密,由于本情形配置较复杂,请联系主机组协助。
ProxyRequests Off
SSLProxyEngine On
SSLProxyMachineCertificateFile /home/apache/chmoNFC/htdocs/certificate/120.204.69.183.pem
SSLProxyCACertificateFile /home/apache/chmoNFC/htdocs/certificate/120.204.69.183.crt
ProxyPass /tsm balancer://TSMProxy/tsm
ProxyPassReverse /tsm balancer://TSMProxy/tsm
<Proxy balancer://TSMProxy>
BalancerMember https://112.106.165.36:9443
SetEnv proxy-nokeepalive 1
</Proxy>
在配置中120.204.69.183.pem和120.204.69.183.crt两个证书文件会有业务室或应用科室提供。
通常来说,一个CLOSE_WAIT会维持至少2个小时的时间?(系统默认超时时间的是7200秒,也就是2小时)
一、 修改方法:(暂时生效,重新启动服务器后,会还原成默认值)
sysctl -w net.ipv4.tcp_keepalive_time=600
sysctl -w net.ipv4.tcp_keepalive_probes=2
sysctl -w net.ipv4.tcp_keepalive_intvl=2
注意:Linux的内核参数调整的是否合理要注意观察,看业务高峰时候效果如何。
二、 若做如上修改后,可起作用;则做如下修改以便永久生效。
vi /etc/sysctl.conf
若配置文件中不存在如下信息,则添加:
net.ipv4.tcp_keepalive_time = 1800
net.ipv4.tcp_keepalive_probes = 3
net.ipv4.tcp_keepalive_intvl = 15
编辑完 /etc/sysctl.conf,要重启network 才会生效
/etc/rc.d/init.d/network restart
然后,执行sysctl命令使修改生效,基本上就算完成了。
------------------------------------------------------------
修改原因:
当客户端因为某种原因先于服务端发出了FIN信号,就会导致服务端被动关闭,若服务端不主动关闭socket发FIN给Client,此时服务端Socket会处于CLOSE_WAIT状态(而不是LAST_ACK状态)。通常来说,一个CLOSE_WAIT会维持至少2个小时的时间(系统默认超时时间的是7200秒,也就是2小时)。如果服务端程序因某个原因导致系统造成一堆CLOSE_WAIT消耗资源,那么通常是等不到释放那一刻,系统就已崩溃。因此,解决这个问题的方法还可以通过修改TCP/IP的参数来缩短这个时间,于是修改tcp_keepalive_*系列参数:
tcp_keepalive_time:
/proc/sys/net/ipv4/tcp_keepalive_time
INTEGER,默认值是7200(2小时)
当keepalive打开的情况下,TCP发送keepalive消息的频率。建议修改值为1800秒。
tcp_keepalive_probes:INTEGER
/proc/sys/net/ipv4/tcp_keepalive_probes
INTEGER,默认值是9
TCP发送keepalive探测以确定该连接已经断开的次数。(注意:保持连接仅在SO_KEEPALIVE套接字选项被打开是才发送.次数默认不需要修改,当然根据情形也可以适当地缩短此值.设置为5比较合适)
tcp_keepalive_intvl:INTEGER
/proc/sys/net/ipv4/tcp_keepalive_intvl
INTEGER,默认值为75
当探测没有确认时,重新发送探测的频度。探测消息发送的频率(在认定连接失效之前,发送多少个TCP的keepalive探测包)。乘以tcp_keepalive_probes就得到对于从开始探测以来没有响应的连接杀除的时间。默认值为75秒,也就是没有活动的连接将在大约11分钟以后将被丢弃。(对于普通应用来说,这个值有一些偏大,可以根据需要改小.特别是web类服务器需要改小该值,15是个比较合适的值)
【检测办法】
1. 系统不再出现“Too many open files”报错现象。
2. 处于TIME_WAIT状态的sockets不会激长。
在 Linux 上可用以下语句看了一下服务器的TCP状态(连接状态数量统计):
netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
返回结果范例如下:
ESTABLISHED 1423
FIN_WAIT1 1
FIN_WAIT2 262
SYN_SENT 1
TIME_WAIT 962
-----------------------------------------------------------------------------------------------
apache/conf> vi extra/httpd-default.conf
KeepAlive On
keep-alvie默认是开启的
服务器负载均衡有三大基本Feature:负载均衡算法,健康检查和会话保持
java.lang.reflect.UndeclaredThrowableException
at $Proxy298.parseSchema(Unknown Source)
at org.apache.cxf.endpoint.dynamic.DynamicClientFactory.addSchemas(DynamicClientFactory.java:423)
at org.apache.cxf.endpoint.dynamic.DynamicClientFactory.createClient(DynamicClientFactory.java:271)
at org.apache.cxf.endpoint.dynamic.DynamicClientFactory.createClient(DynamicClientFactory.java:198)
at org.apache.cxf.endpoint.dynamic.DynamicClientFactory.createClient(DynamicClientFactory.java:191)
at org.apache.cxf.endpoint.dynamic.DynamicClientFactory.createClient(DynamicClientFactory.java:146)
at com.cup.maps.online.OnlineTrans.getResponseByType(OnlineTrans.java:630)
at com.cup.maps.online.OnlineTrans.access$000(OnlineTrans.java:57)
at com.cup.maps.online.OnlineTrans$ServiceDealThread.run(OnlineTrans.java:834)
Caused by: java.lang.reflect.InvocationTargetException
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:60)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:37)
at java.lang.reflect.Method.invoke(Method.java:611)
at org.apache.cxf.common.util.ReflectionInvokationHandler.invoke(ReflectionInvokationHandler.java:52)
... 9 more
Caused by: java.lang.NullPointerException
at org.apache.xerces.dom.ParentNode.nodeListItem(Unknown Source)
at org.apache.xerces.dom.ParentNode.item(Unknown Source)
at com.sun.xml.internal.bind.unmarshaller.DOMScanner.visit(DOMScanner.java:246)
at com.sun.xml.internal.bind.unmarshaller.DOMScanner.visit(DOMScanner.java:277)
at com.sun.xml.internal.bind.unmarshaller.DOMScanner.visit(DOMScanner.java:246)
at com.sun.xml.internal.bind.unmarshaller.DOMScanner.visit(DOMScanner.java:277)
at com.sun.xml.internal.bind.unmarshaller.DOMScanner.visit(DOMScanner.java:246)
at com.sun.xml.internal.bind.unmarshaller.DOMScanner.scan(DOMScanner.java:123)
at com.sun.tools.internal.xjc.api.impl.s2j.SchemaCompilerImpl.parseSchema(SchemaCompilerImpl.java:136)
... 14 more
解决:通讯配置文件同步,会有多个线程同时使用cxf生成ws客户端,此处代码非线程安全导致报错。
TestHttpHeartBeat测试HttpClient的executeMethod执行3000次,未见内存泄露
Exception in thread "pool-1-thread-1" java.lang.IllegalStateException: Unable to create JAXBContext for generated packages: "com.cup.mtq" doesnt contain ObjectFactory.class or jaxb.index
at org.apache.cxf.endpoint.dynamic.DynamicClientFactory.createClient(DynamicClientFactory.java:345)
at org.apache.cxf.endpoint.dynamic.DynamicClientFactory.createClient(DynamicClientFactory.java:198)
at org.apache.cxf.endpoint.dynamic.DynamicClientFactory.createClient(DynamicClientFactory.java:191)
at org.apache.cxf.endpoint.dynamic.DynamicClientFactory.createClient(DynamicClientFactory.java:146)
at TestcxfCreateWsClient.run(TestcxfCreateWsClient.java:52)
at java.util.concurrent.ThreadPoolExecutor$Worker.runTask(ThreadPoolExecutor.java:895)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:918)
at java.lang.Thread.run(Thread.java:662)
Caused by: javax.xml.bind.JAXBException: "com.cup.mtq" doesnt contain ObjectFactory.class or jaxb.index
at com.sun.xml.bind.v2.ContextFactory.createContext(ContextFactory.java:197)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:39)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:25)
at java.lang.reflect.Method.invoke(Method.java:597)
at javax.xml.bind.ContextFinder.newInstance(ContextFinder.java:128)
at javax.xml.bind.ContextFinder.find(ContextFinder.java:277)
at javax.xml.bind.JAXBContext.newInstance(JAXBContext.java:372)
at org.apache.cxf.endpoint.dynamic.DynamicClientFactory.createClient(DynamicClientFactory.java:342)
... 7 more
javac: 找不到文件: C:\DOCUME~1\沈雷\LOCALS~2\Temp\cxf-tmp-833848\cxf-compiler3952818340990681712.tmp (系统找不到指定的文件。)
解决:使用ExecutePool会导致此问题,使用Thread线程调用cxf.createClient不会有问题。
另外,在.profile中添加PATH=$PATH:/usr/java6_64/bin:.生效后重启也能解决问题
前置管理启动时报错:
The last packet sent successfully to the server was 0 milliseconds ago. The driver has not received any packets from the server.)
at org.jboss.resource.adapter.jdbc.local.LocalManagedConnectionFactory.getLocalManagedConnection(LocalManagedConnectionFactory.java:225)
at org.jboss.resource.adapter.jdbc.local.LocalManagedConnectionFactory.createManagedConnection(LocalManagedConnectionFactory.java:195)
at org.jboss.resource.connectionmanager.InternalManagedConnectionPool.createConnectionEventListener(InternalManagedConnectionPool.java:639)
at org.jboss.resource.connectionmanager.InternalManagedConnectionPool.getConnection(InternalManagedConnectionPool.java:273)
at org.jboss.resource.connectionmanager.JBossManagedConnectionPool$BasePool.getConnection(JBossManagedConnectionPool.java:689)
at org.jboss.resource.connectionmanager.BaseConnectionManager2.getManagedConnection(BaseConnectionManager2.java:404)
... 95 more
Caused by: com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Communications link failure
The last packet sent successfully to the server was 0 milliseconds ago. The driver has not received any packets from the server.
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:39)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:27)
at java.lang.reflect.Constructor.newInstance(Constructor.java:513)
at com.mysql.jdbc.Util.handleNewInstance(Util.java:408)
at com.mysql.jdbc.SQLError.createCommunicationsException(SQLError.java:1137)
at com.mysql.jdbc.MysqlIO.<init>(MysqlIO.java:356)
at com.mysql.jdbc.ConnectionImpl.coreConnect(ConnectionImpl.java:2504)
at com.mysql.jdbc.ConnectionImpl.connectOneTryOnly(ConnectionImpl.java:2541)
at com.mysql.jdbc.ConnectionImpl.createNewIO(ConnectionImpl.java:2323)
at com.mysql.jdbc.ConnectionImpl.<init>(ConnectionImpl.java:832)
at com.mysql.jdbc.JDBC4Connection.<init>(JDBC4Connection.java:46)
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:39)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:27)
at java.lang.reflect.Constructor.newInstance(Constructor.java:513)
at com.mysql.jdbc.Util.handleNewInstance(Util.java:408)
at com.mysql.jdbc.ConnectionImpl.getInstance(ConnectionImpl.java:417)
at com.mysql.jdbc.NonRegisteringDriver.connect(NonRegisteringDriver.java:344)
at org.jboss.resource.adapter.jdbc.local.LocalManagedConnectionFactory.getLocalManagedConnection(LocalManagedConnectionFactory.java:207)
... 100 more
解决:排除程序和jar包冲突问题后,发现管理应用的ip和访问用户mi_mgmap没有访问mimgmdb数据库的权限,如此增加即可:
grant all privileges on mimgmdb.* to mi_mgmap@'146.240.10.64' identified by 'mi_mgmap';
grant all privileges on mionldb.* to mi_mgmap@'146.240.10.64' identified by 'mi_mgmap';
服务器启动时,ServletContextListener的contextInitialized()方法被调用;服务器将要关闭时,ServletContextListener 的 contextDestroyed()方法被调用;
spring在web应用启动的listener类:org.springframework.web.context.ContextLoaderListener就用到了ServletContextListener。
系统室在146.240.25.38的apache上配置了ProxyRemote,使其通过访问代理服务访问外网,做法是:
在apache/conf/httpd.conf文件代理配置前添加:
ProxyRemote * http://172.18.64.89:3128
ProxyPreserveHost On 意思是传送原始请求的Host信息给被代理的机器。
javax.xml.bind.UnmarshalException
- with linked exception:
[org.xml.sax.SAXParseException: The element type "domain" must be terminated by the matching end-tag "</domain>".]
at javax.xml.bind.helpers.AbstractUnmarshallerImpl.createUnmarshalException(AbstractUnmarshallerImpl.java:315)
at com.sun.xml.bind.v2.runtime.unmarshaller.UnmarshallerImpl.createUnmarshalException(UnmarshallerImpl.java:514)
at com.sun.xml.bind.v2.runtime.unmarshaller.UnmarshallerImpl.unmarshal0(UnmarshallerImpl.java:215)
at com.sun.xml.bind.v2.runtime.unmarshaller.UnmarshallerImpl.unmarshal(UnmarshallerImpl.java:184)
at javax.xml.bind.helpers.AbstractUnmarshallerImpl.unmarshal(AbstractUnmarshallerImpl.java:137)
at javax.xml.bind.helpers.AbstractUnmarshallerImpl.unmarshal(AbstractUnmarshallerImpl.java:184)
解决:mtqService和mtqNetwork均有校验
linux
# uname -a # 查看内核/操作系统/CPU信息
# head -n 1 /etc/issue # 查看操作系统版本
# cat /proc/cpuinfo # 查看CPU信息
# hostname # 查看计算机名
# lspci -tv # 列出所有PCI设备
# lsusb -tv # 列出所有USB设备
# lsmod # 列出加载的内核模块
# env # 查看环境变量资源
# free -m # 查看内存使用量和交换区使用量
# df -h # 查看各分区使用情况
# du -sh <目录名> # 查看指定目录的大小
# grep MemTotal /proc/meminfo # 查看内存总量
# grep MemFree /proc/meminfo # 查看空闲内存量
# uptime # 查看系统运行时间、用户数、负载
# cat /proc/loadavg # 查看系统负载磁盘和分区
# mount | column -t # 查看挂接的分区状态
# fdisk -l # 查看所有分区
# swapon -s # 查看所有交换分区
# hdparm -i /dev/hda # 查看磁盘参数(仅适用于IDE设备)
# dmesg | grep IDE # 查看启动时IDE设备检测状况网络
# ifconfig # 查看所有网络接口的属性
# iptables -L # 查看防火墙设置
# route -n # 查看路由表
# netstat -lntp # 查看所有监听端口
# netstat -antp # 查看所有已经建立的连接
# netstat -s # 查看网络统计信息进程
# ps -ef # 查看所有进程
# top # 实时显示进程状态用户
# w # 查看活动用户
# id <用户名> # 查看指定用户信息
# last # 查看用户登录日志
# cut -d: -f1 /etc/passwd # 查看系统所有用户
# cut -d: -f1 /etc/group # 查看系统所有组
# crontab -l # 查看当前用户的计划任务服务
# chkconfig –list # 列出所有系统服务
# chkconfig –list | grep on # 列出所有启动的系统服务程序
# rpm -qa # 查看所有安装的软件包
查看主机名
vi /proc/sys/kernel/hostname
hostname
hostname –a: 获取主机别名。
hostname –d: 获取DNS域名。
hostname –f: 获取FQDN名称。
hostname –i: 获取主机的IP地址。
hostname –s: 获取域名的netbios名称。
hostname和ip的对应文件:
vi /etc/hosts
HttpClient对于要求接受后继服务的请求(301、302、303、307),比如POST和PUT,不支持自动转发,因此需要自己对页面转向做处理。
client.executeMethod(post);
System.out.println(post.getStatusLine().toString());
post.releaseConnection();
//检查是否重定向
int statuscode = post.getStatusCode();
if ((statuscode == HttpStatus.SC_MOVED_TEMPORARILY) ||
(statuscode == HttpStatus.SC_MOVED_PERMANENTLY) ||
(statuscode == HttpStatus.SC_SEE_OTHER) ||
(statuscode == HttpStatus.SC_TEMPORARY_REDIRECT)) {
//读取新的URL地址
Header header = post.getResponseHeader("location");
if (header != null) {
String newuri = header.getValue();
if ((newuri == null) || (newuri.equals("")))
newuri = "/";
GetMethod redirect = new GetMethod(newuri);
client.executeMethod(redirect);
System.out.println("Redirect:"+ redirect.getStatusLine().toString());
redirect.releaseConnection();
} else
System.out.println("Invalid redirect");
}
HttpClient支持自动重传,如果要自定义exception重传需要实现HttpMethodRetryHandler类,然后设置:
httpget.getParams().setParameter(HttpMethodParams.RETRY_HANDLER, myretryhandler);
<%@ page isELIgnored="true" %> 表示是否禁用EL语言,TRUE表示禁止.FALSE表示不禁止.JSP2.0中默认的启用EL语言。
<%=request.getParameter(“username”)%> 等价于 ${param.username}
<%=user.getAddr( ) %> 等价于 ${user.addr}
<%=request.getAttribute(“userlist”) %> 等价于$ { requestScope.userlist } 注意不是request.getParameter
EL表达式:http://baike.baidu.com/view/1488964.htm?fr=aladdin
DWR的逆向Ajax主要包括两种模式:主动模式和被动模式。其中主动模式包括polling和comet两种,被动模式只有piggyback这一种。默认是下面的第一种piggyback
1、piggyback方式
这是默认的方式。
如果后台有什么内容需要推送到前台,是要等到那个页面进行下一次ajax请求的时候,将需要推送的内容附加在该次请求之后,传回到页面。
只有等到下次请求页面主动发起了,中间的变化内容才传递回页面。
2、comet方式
当服务端建立和浏览器的连接,将页面内容发送到浏览器之后,对应的连接并不关闭,只是暂时挂起。如果后面有什么新的内容需要推送到客户端的时候
直接通过前面挂起的连接再次传送数据。服务器所能提供的连接数目是一定的,在大量的挂起的连接没有关闭的情况下,可能造成新的连接请求不能接入,
从而影响到服务质量。
3、polling方式
由浏览器定时向服务端发送ajax请求,询问后台是否有什么内容需要推送,有的话就会由服务端返回推送内容。这种方式和我们直接在页面通过定时器发送ajax请求,
然后查询后台是否有变化内容的实现是类似的。只不过用了dwr之后这部分工作由框架帮我们完成了。
<!-- 使用polling和comet的方式 -->
<init-param>
<param-name>pollAndCometEnabled</param-name>
<param-value>true</param-value>
</init-param>
<!-- comet方式 -->
<init-param>
<param-name>activeReverseAjaxEnabled</param-name>
<param-value>true</param-value>
</init-param>
<!-- polling方式:在comet方式的基础之上,再配置以下参数 -->
<init-param>
<param-name>org.directwebremoting.extend.ServerLoadMonitor</param-name>
<param-value>org.directwebremoting.impl.PollingServerLoadMonitor</param-value>
</init-param>
<!-- 毫秒数。页面默认的请求间隔时间是5秒 -->
<init-param>
<param-name>disconnectedTime</param-name>
<param-value>60000</param-value>
</init-param>
veloctiy中将某javabean输出到前台vhtml时,需要该javabean是public的,并且该属性的get函数也是public的才行。例如:
public class Model {
String abc = "a111111";
public String getAbc() {
return abc;
}
}
ctx.put("model2", new Model());
velocity页面取值的区别?一个int型,一个string
alert("@@@@@@@@@@@="+$tblcd); 267777
alert("@@@@@@@@@@@="+'$tblcd');01013001
在spring 中,常用的ViewResolver 有如下几种:
InternalResourceViewResolver 将逻辑视图名字解析为一个路径
BeanNameViewResolver 将逻辑视图名字解析为bean的Name属性,从而根据name属性,找定义View的bean
ResourceBundleResolver 和BeanNameViewResolver一样,只不过定义的view-bean都在一个properties文件中,用这个类进行加载这个properties文件
XmlViewResolver 和ResourceBundleResolver一样,只不过定义的view-bean在一个xml文件中,用这个类来加载xml文件
DispatcherServlet会加载所有的viewResolver到一个list中,并按照优先级进行解析。
注意:①order中的值越小,优先级越高。
②而id为viewResolver的viewResolver的优先级是最低的。
问:velocityViewResolver不起作用?
解决:如果为DispatcherServlet指定多个ViewResolver的话,不要给予InternalResourceViewResolver以及其他UrlBasedViewResolver子类过高的优先级,
因为这些ViewResolver即使找不到相应的视图,也不会返回null以给我们轮询下一个ViewResolver的机会。要给org.springframework.web.servlet.view.velocity.VelocityViewResolver
最高级别的等级。
@ModelAttribute获取POST请求的FORM表单数据
JSP表单如下
<form method="post" action="hao.do">
a: <input id="a" type="text" name="a"/>
b: <input id="b" type="text" name="b"/>
<input type="submit" value="Submit" />
</form>
Java Pojo如下
public class Pojo{
private String a;
private int b;
}
Java Controller如下
@RequestMapping(method = RequestMethod.POST)
public String processSubmit(@ModelAttribute("pojo") Pojo pojo) {
return "helloWorld";
}
switch语句的判断条件可以接受int,byte,char,short,enum。不能接受其他类型.
构造器Constructor不能被继承,因此不能重写Overriding,但可以被重载Overloading
overload和override的区别
override(重写)
1、方法名、参数、返回值相同。
2、子类方法不能缩小父类方法的访问权限。
3、子类方法不能抛出比父类方法更多的异常(但子类方法可以不抛出异常)。
4、存在于父类和子类之间。
5、方法被定义为final不能被重写。
overload(重载)
1、参数类型、个数、顺序至少有一个不相同。
2、不能重载只有返回值不同的方法名。
3、存在于父类和子类、同类中。
abstract的method是否可同时是static,是否可同时是native,是否可同时是synchronized?
都可以的
Error与Exception有什么区别?
Exception表示应用程序级错误,Error表示系统错误或低层资源的错误
List, Set, Map是否继承自Collection接口?
Map不继承,另外两个继承
short s1 = 1; s1 += 1;有什么错?
不会报错,+=这个运算具有隐式转换的功能
Math类中提供了三个与取整有关的方法:ceil、floor、round。ceil的英文意义是天花板,该方法就表示向上取整,floor的英文意义是地板,该方法就表示向下取整
round方法,它表示“四舍五入”,算法为Math.floor(x+0.5),即将原来的数字加上0.5后再向下取整
HashMap是Hashtable的轻量级实现(非线程安全的实现),他们都完成了Map接口,主要区别在于HashMap允许空(null)键值(key),
由于非线程安全,效率上可能高于Hashtable。
Anonymous Inner Class (匿名内部类)匿名的内部类是没有名字的内部类。
匿名的内部类不能extends(继承)其它类,但一个内部类可以作为一个接口,由另一个内部类实现。
String s = new String("xyz");创建了几个String Object?
一个引用s,一个对象new String在堆中,一个存于常量池,即永久代中。
银行卡包括借记卡,准贷记卡和贷记卡,其中,准贷记卡跟贷记卡并称为信用卡。
1、贷记卡是指发卡银行给予持卡人一定的信用额度,持卡人可在信用额度内先消费,后还款的银行卡,一般可以透支取现。
如果在贷记卡里面你的账户有钱的话,这部分钱不会获得银行利息,即贷记卡存款不计息。
2、准贷记卡是指持卡人须先按发卡银行要求交存一定金额的备用金(其实这个备用金你马上就可以全部取走的,跟没存没多少差别),
当备用金账户余额不足支付时,可在发卡银行规定的信用额度内透支的银行卡,这个卡一般不可以透支取现,不过可以透支消费,
但透支消费后往往没有免息期。另外,如果在准贷记卡里面你的账户有钱的话,是可以从银行获得活期利息的。
3、借记卡是指先存款后消费(或取现),没有透支功能的银行卡。其按功能不同,又可分为转账卡(含储蓄卡)、专用卡及储值卡。
如果在借记卡里面你的账户有钱的话,是可以从银行获得活期利息的。
apache负载均衡
http://146.240.25.39:4488/mi
hibernate java project 最小依赖包
hibernate-release-4.0.0.Beta4.zip包里面lib/required下的jar包全部添加到工程的library里面,
另外还需添加slf4j的实现包slf4j-log4j12-1.5.8.jar和log4j的实现包log4j-1.2.16.jar,还有别忘了把JDBC的驱动jar包也加入到library
UPJAS1.x包含的组件版本
Component Version
JBoss Application Server 5.1.0.GA
JBoss Microcontainer 2.0.10.GA
JBoss Web (based on Tomcat 6.0) 2.1.12.GA-patch-01
JBoss EJB3 1.3.8
Hibernate Core 3.3.2.GA_CP04
Hibernate Entity Manager 3.4.0.GA_CP04
Hibernate Annotations 3.4.0.GA_CP04
Hibernate Validator 3.1.0.GA
JBoss WS-CXF 3.1.2.SP9
JPA 1.0.0
HornetQ HornetQ_2_2_20_EAP_GA
tomcat数据源配置使用:
1、apache-tomcat-6.0.37\conf\context.xml增加
<Resource name="jdbc/mysqldb"
auth="Container"
type="javax.sql.DataSource"
driverClassName="com.mysql.jdbc.Driver"
url="jdbc:mysql://146.240.54.1:60016/mimgmdb?useUnicode=true&characterEncoding=utf-8&useOldAliasMetadataBehavior=true&zeroDateTimeBehavior=convertToNull"
username="mi_mgmap"
password="mi_mgmap"
maxActive="100"
maxIdle="30"
maxWait="10000"
logAbandoned="true" />
2、index.jsp中调用:
<%
Context initContext = new InitialContext();
DataSource ds = (DataSource)initContext.lookup("java:comp/env/jdbc/mysqldb");
Connection conn = ds.getConnection();
Statement stat = conn.createStatement();
String sql = "select * from tbl_user";
ResultSet rs = stat.executeQuery(sql);
if(rs.next())
out.print(rs.getString(1));
conn.close();
initContext.close();
%>
换成db2的配置:(竟然无需db2驱动。。。)
<Resource name="jdbcMapsMng"
auth="Container"
type="javax.sql.DataSource"
driverClassName="com.ibm.db2.jcc.DB2Driver"
url="jdbc:db2://172.17.252.83:60004/mamgmdb:currentSchema=MA_MGMDB;"
username="ma_mgmdb"
password="ma_mgmdb"
maxActive="100"
maxIdle="30"
maxWait="10000"
logAbandoned="true" />
jboss数据源配置:
1、新增server/default/cup-deploy/jdbc/mysql-mimgm-ds.xml文件,内容如下:
<datasources>
<local-tx-datasource>
<jndi-name>miMng</jndi-name>
<connection-url>jdbc:mysql://172.17.254.249:3306/mimgmdb?useUnicode=true&characterEncoding=utf-8&useOldAliasMetadataBehavior=true&zeroDateTimeBehavior=convertToNull</connection-url>
<driver-class>com.mysql.jdbc.Driver</driver-class>
<user-name>mi_mgmdb</user-name>
<password>mi_mgmdb</password>
<exception-sorter-class-name>org.jboss.resource.adapter.jdbc.vendor.MySQLExceptionSorter</exception-sorter-class-name>
<!-- should only be used on drivers after 3.22.1 with "ping" support
<valid-connection-checker-class-name>org.jboss.resource.adapter.jdbc.vendor.MySQLValidConnectionChecker</valid-connection-checker-class-name>
-->
<!-- sql to call when connection is created
<new-connection-sql>some arbitrary sql</new-connection-sql>
-->
<!-- sql to call on an existing pooled connection when it is obtained from pool - MySQLValidConnectionChecker is preferred for newer drivers
<check-valid-connection-sql>some arbitrary sql</check-valid-connection-sql>
-->
<!-- corresponding type-mapping in the standardjbosscmp-jdbc.xml (optional) -->
<use-java-context>false</use-java-context>
<min-pool-size>5</min-pool-size>
<max-pool-size>100</max-pool-size>
<blocking-timeout-millis>30000</blocking-timeout-millis>
<idle-timeout-minutes>10</idle-timeout-minutes>
<set-tx-query-timeout/>
<query-timeout>60</query-timeout> <!-- maximum of 1 minutes for queries -->
<metadata>
<type-mapping>mySQL</type-mapping>
</metadata>
</local-tx-datasource>
</datasources>
2、修改server/default/conf/login-config.xml文件,如果已在第1步中配置了password,这个文件可以不用改,但是密码是明文的,
如果在这个文件里面加了以后,启动后密码是密文(其实可破解)。
<application-policy name="EncryptDBPassword_mimgmdb">
<authentication>
<login-module code="org.jboss.resource.security.SecureIdentityLoginModule" flag="required">
<module-option name="username">ma_mgmdb</module-option>
<module-option name="password">-5cdd895416a30c6207a6df87216de44</module-option>
<module-option name="managedConnectionFactoryName">jboss.jca:name=miMng,service=LocalTxCM</module-option>
</login-module>
</authentication>
</application-policy>
3、使用
外部client程序调用:
Context initContext = new InitialContext();
Properties props = new Properties();
props.setProperty("java.naming.factory.initial",
"org.jnp.interfaces.NamingContextFactory");
props.setProperty("java.naming.provider.url",
"jnp://172.17.236.133:11004");//"jnp://172.17.236.133:11004"
props.setProperty("java.naming.factory.url.pkgs",
"org.jboss.naming:org.jnp.interfaces");
initContext = new InitialContext(props);
DataSource ds = (DataSource)initContext.lookup("miMng");
Connection conn = ds.getConnection();
Statement stat = conn.createStatement();
String sql = "select * from tbl_user";
ResultSet rs = stat.executeQuery(sql);
if(rs.next())
System.out.print(rs.getString(1));
conn.close();
initContext.close();
war包内程序调用:
<%
Context initContext = new InitialContext();
DataSource ds = (DataSource)initContext.lookup("miMng");
Connection conn = ds.getConnection();
Statement stat = conn.createStatement();
String sql = "select * from tbl_user";
ResultSet rs = stat.executeQuery(sql);
if(rs.next())
out.print(rs.getString(1));
conn.close();
initContext.close();
%>
报错:
org.jboss.resource.JBossResourceException: Apparently wrong driver class specified for URL:
class: com.mysql.jdbc.Driver, url: jdbc:mysql://146.240.54.1:60016/mimgmdb?useUnicode=true&characterEncoding=utf-8&useOldAliasMetadataBehavior=true&zeroDateTimeBehavior=convertToNull
org.jboss.resource.adapter.jdbc.local.LocalManagedConnectionFactory.getDriver(LocalManagedConnectionFactory.java:492)
解决:将war包的WEB-INF/lib下的mysql驱动移动到server\default\lib下就好了
高危漏洞
Slow HTTP Denial Of Service Attack
这个攻击的原理和slowloris有点类似,略有不同的是利用的HTTP POST:POST的时候,指定一个非常大的
content-length,然后以很低的速度发包,比如10-100s发一个字节,hold住这个连接不断开。这样当客
户端连接多了后,占用住了webserver的所有可用连接,从而导致DOS。
管理系统因浏览器flash插件原因无法显示?
解决:安装install_flash_player_ax_14.0.0.176.1407893783.exe
java.net.UnknownHostException: miftcom01: miftcom01
at java.net.InetAddress.getLocalHost(InetAddress.java:1360)
at org.jboss.system.server.ServerInfo.getHostName(ServerInfo.java:344)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:39)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:25)
at java.lang.reflect.Method.invoke(Method.java:597)
at org.jboss.reflect.plugins.introspection.ReflectionUtils.invoke(ReflectionUtils.java:59)
at org.jboss.reflect.plugins.introspection.ReflectMethodInfoImpl.invoke(ReflectMethodInfoImpl.java:150)
at org.jboss.beans.info.plugins.DefaultPropertyInfo.get(DefaultPropertyInfo.java:133)
at org.jboss.managed.plugins.factory.AbstractInstanceClassFactory.getValue(AbstractInstanceClassFactory.java:202)
at org.jboss.deployers.plugins.managed.BeanMetaDataICF.getValue(BeanMetaDataICF.java:205)
at org.jboss.deployers.plugins.managed.BeanMetaDataICF.getValue(BeanMetaDataICF.java:54)
at org.jboss.managed.plugins.factory.AbstractManagedObjectPopulator.populateValues(AbstractManagedObjectPopulator.java:204)
at org.jboss.managed.plugins.factory.AbstractManagedObjectPopulator.populateManagedObject(AbstractManagedObjectPopulator.java:130)
at org.jboss.managed.plugins.factory.AbstractManagedObjectFactory.initManagedObject(AbstractManagedObjectFactory.java:422)
at org.jboss.managed.api.factory.ManagedObjectFactory.initManagedObject(ManagedObjectFactory.java:77)
at org.jboss.system.server.profileservice.ProfileServiceBootstrap.initBootstrapMDs(ProfileServiceBootstrap.java:450)
at org.jboss.system.server.profileservice.ProfileServiceBootstrap.start(ProfileServiceBootstrap.java:242)
at org.jboss.bootstrap.AbstractServerImpl.start(AbstractServerImpl.java:461)
at org.jboss.Main.boot(Main.java:221)
at org.jboss.Main$1.run(Main.java:556)
at java.lang.Thread.run(Thread.java:662)
解决:vi /etc/hosts查看hostname与ip设置是否一致。
javascript调用android4.2中的方法失败?
Android4.2对webview中Javascript接口声明进行了修改,Android 4.2以上版本调用Javascript接口失败的解决方法是在方法之前
使用声明@JavascriptInterface。
view plaincopyprint?.addJavascriptInterface(new Object()
{
@JavascriptInterface
public void download(int bookId)
{
bid = String.valueOf(bookId);
downLoad.show();
}
访问url:http://172.17.252.88:10000/mjc/MtqWebService?wsdl报如下错:
Error creating bean with name 'MtqWebServiceServlethttp': Invocation of init method failed;
nested exception is javax.xml.ws.WebServiceException: org.apache.cxf.service.factory.ServiceConstructionException
解决:MjcRequest类缺少无参构造函数,考,报错这么模糊。
public MjcResponse callByObject(MjcRequest mr) {}
public MjcRequest(){}
mtqj1.4.3版本改造成访问这个url需要给content-length,否则报411
http://172.17.248.74:11000/mjc/webtrans/s?aa=1111
mtq.properties中的READ_TIME_OUT设置是mtqj同步交易超时最大值。
注掉READ_TIME_OUT后刷新并不能还原成原先java中定义的值。
增加link的para=OB,表示mjc在调用时,函数入参是MjcCoreRequest,返回参数是MjcCoreResponse
mtqj的java端接口(MtqWebService+MtqMethodInvocationHandler)使用改变:
callByObject(MjcRequest mjcRequest):交易报文默认使用UTF-8转字节传递
callByObjectUsedBytes(MjcCoreRequest mjcCoreRequest):字节传递
http接口-MtqWebAction:取request.getInputStream(),字节传递
日志由异步线程来打的坏处是:
如果tps高导致记录的日志太大的话,而异步线程在写磁盘的速度又低,会导致日志队列变的巨大,导致fullgc时间过长,且无法清理。陷入死循环。
ConcurrentLinkedQueue非阻塞队列
BlockingQueue 阻塞队列
ant中条件判断这里有2种形式,一种是运用 target 的if and unless attributes (ant 中自带功能),
一种是运用ant-contrib(一个ant的插件)中的if else。
2014-09-25 16:45:32,937 [Thread-4630] ERROR com.cup.maps.online.OnlineTrans - WS调用失败:
java.lang.reflect.UndeclaredThrowableException
at $Proxy298.parseSchema(Unknown Source)
at org.apache.cxf.endpoint.dynamic.DynamicClientFactory.addSchemas(DynamicClientFactory.java:423)
at org.apache.cxf.endpoint.dynamic.DynamicClientFactory.createClient(DynamicClientFactory.java:271)
at org.apache.cxf.endpoint.dynamic.DynamicClientFactory.createClient(DynamicClientFactory.java:198)
at org.apache.cxf.endpoint.dynamic.DynamicClientFactory.createClient(DynamicClientFactory.java:191)
at org.apache.cxf.endpoint.dynamic.DynamicClientFactory.createClient(DynamicClientFactory.java:146)
at com.cup.maps.online.OnlineTrans.getResponseByType(OnlineTrans.java:628)
at com.cup.maps.online.OnlineTrans.access$000(OnlineTrans.java:57)
at com.cup.maps.online.OnlineTrans$ServiceDealThread.run(OnlineTrans.java:834)
Caused by:
java.lang.reflect.InvocationTargetException
at sun.reflect.GeneratedMethodAccessor500.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:37)
at java.lang.reflect.Method.invoke(Method.java:600)
at org.apache.cxf.common.util.ReflectionInvokationHandler.invoke(ReflectionInvokationHandler.java:52)
... 9 more
Caused by:
java.lang.StackOverflowError
at org.apache.xerces.dom.ElementNSImpl.setName(Unknown Source)
at org.apache.xerces.dom.ElementNSImpl.<init>(Unknown Source)
at org.apache.xerces.dom.CoreDocumentImpl.createElementNS(Unknown Source)
at com.sun.xml.internal.bind.marshaller.SAX2DOMEx.startElement(SAX2DOMEx.java:118)
at com.sun.tools.internal.xjc.reader.internalizer.DOMBuilder.startElement(DOMBuilder.java:84)
at org.xml.sax.helpers.XMLFilterImpl.startElement(Unknown Source)
at com.sun.tools.internal.xjc.reader.internalizer.WhitespaceStripper.startElement(WhitespaceStripper.java:109)
at org.xml.sax.helpers.XMLFilterImpl.startElement(Unknown Source)
at com.sun.tools.internal.xjc.reader.internalizer.VersionChecker.startElement(VersionChecker.java:94)
at org.xml.sax.helpers.XMLFilterImpl.startElement(Unknown Source)
at com.sun.tools.internal.xjc.reader.internalizer.AbstractReferenceFinderImpl.startElement(AbstractReferenceFinderImpl.java:80)
at org.xml.sax.helpers.XMLFilterImpl.startElement(Unknown Source)
at com.sun.xml.internal.bind.unmarshaller.DOMScanner.visit(DOMScanner.java:236)
...
at com.sun.xml.internal.bind.unmarshaller.DOMScanner.scan(DOMScanner.java:119)
at com.sun.tools.internal.xjc.api.impl.s2j.SchemaCompilerImpl.parseSchema(SchemaCompilerImpl.java:131)
... 13 more
解决:多线程调用DynamicClientFactory.createClient()时出现死循环,导致StackOverflowError错误。解决方法重启。
提出的缺陷
http://stackoverflow.com/questions/23907726/jaxwsdynamicclientfactory-newinstance-createclientwsdl-java-lang-reflect-u
http://mail-archives.apache.org/mod_mbox/cxf-issues/201405.mbox/%3CJIRA.12717029.1401278298753.30879.1401278406504@arcas%3E
2014-09-25 16:46:29,770 [Thread-4635] ERROR com.cup.maps.online.OnlineTrans - WS调用失败:
java.lang.reflect.UndeclaredThrowableException
at $Proxy298.bind(Unknown Source)
at org.apache.cxf.endpoint.dynamic.DynamicClientFactory.createClient(DynamicClientFactory.java:273)
at org.apache.cxf.endpoint.dynamic.DynamicClientFactory.createClient(DynamicClientFactory.java:198)
at org.apache.cxf.endpoint.dynamic.DynamicClientFactory.createClient(DynamicClientFactory.java:191)
at org.apache.cxf.endpoint.dynamic.DynamicClientFactory.createClient(DynamicClientFactory.java:146)
at com.cup.maps.online.OnlineTrans.getResponseByType(OnlineTrans.java:628)
at com.cup.maps.online.OnlineTrans.access$000(OnlineTrans.java:57)
at com.cup.maps.online.OnlineTrans$ServiceDealThread.run(OnlineTrans.java:834)
Caused by:
java.lang.reflect.InvocationTargetException
at sun.reflect.GeneratedMethodAccessor528.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:37)
at java.lang.reflect.Method.invoke(Method.java:600)
at org.apache.cxf.common.util.ReflectionInvokationHandler.invoke(ReflectionInvokationHandler.java:52)
... 8 more
Caused by:
java.lang.reflect.UndeclaredThrowableException
at $Proxy300.error(Unknown Source)
at com.sun.tools.internal.xjc.api.impl.s2j.SchemaCompilerImpl.error(SchemaCompilerImpl.java:276)
at com.sun.tools.internal.xjc.util.ErrorReceiverFilter.error(ErrorReceiverFilter.java:73)
at com.sun.xml.internal.xsom.impl.parser.ParserContext$2.error(ParserContext.java:178)
at com.sun.xml.internal.xsom.impl.parser.ParserContext$1.reportError(ParserContext.java:156)
at com.sun.xml.internal.xsom.impl.parser.NGCCRuntimeEx.reportError(NGCCRuntimeEx.java:146)
at com.sun.xml.internal.xsom.impl.parser.DelayedRef.resolve(DelayedRef.java:98)
at com.sun.xml.internal.xsom.impl.parser.DelayedRef.run(DelayedRef.java:64)
at com.sun.xml.internal.xsom.impl.parser.ParserContext.getResult(ParserContext.java:107)
at com.sun.xml.internal.xsom.parser.XSOMParser.getResult(XSOMParser.java:202)
at com.sun.tools.internal.xjc.ModelLoader.createXSOM(ModelLoader.java:515)
at com.sun.tools.internal.xjc.api.impl.s2j.SchemaCompilerImpl.bind(SchemaCompilerImpl.java:228)
... 12 more
Caused by:
java.lang.reflect.InvocationTargetException
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:48)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:37)
at java.lang.reflect.Method.invoke(Method.java:600)
at org.apache.cxf.common.util.ReflectionInvokationHandler.invoke(ReflectionInvokationHandler.java:52)
... 24 more
Caused by:
java.lang.RuntimeException: Error compiling schema from WSDL at {http://145.0.153.23:10080/mjc/MtqWebService?WSDL}: undefined simple or complex type 'tns:callByObject'
at org.apache.cxf.endpoint.dynamic.DynamicClientFactory$InnerErrorListener.error(DynamicClientFactory.java:579)
... 29 more
Caused by:
org.xml.sax.SAXParseException: undefined simple or complex type 'tns:callByObject'
at com.sun.xml.internal.xsom.impl.parser.ParserContext$1.reportError(ParserContext.java:152)
... 19 more
解决:上面那个报错发生后,再次调用这个函数DynamicClientFactory.createClient均会出现这个问题。
ulimit 限制的是当前 shell 进程以及其派生的子进程.
建议设置成无限制(unlimited)的一些重要设置是:
数据段长度:ulimit –d unlimited
最大内存大小:ulimit –m unlimited
堆栈大小:ulimit –s unlimited
CPU 时间:ulimit –t unlimited
虚拟内存:ulimit –v unlimited
response.getoutputstream 可以close()多次吗?
解决:试验后发现可以执行多次不报错。
替换某个目录/home/mi_mgmap/sl下的所有文件的某个字符串/SERVICE01/ma,改成/maps
即使用/maps替换/SERVICE01/ma,命令如下:
sed -i "s/\/SERVICE01\/ma/\/maps/g" `grep /SERVICE01/ma -rl /home/mi_mgmap/sl`
注意:特殊字符 / 需要用 \/ 代替;`是1左边的符号;/home/mi_mgmap/sl是需要替换文件的目录
查找某一类型文件(比如.h文件)中含有的字符串(比如ABC)
find . -name "*.h"|xargs grep -R ABC
调整JBOSS最大连接数.
配置deploy/jboss-web.deployer/server.xml文件 .
<Connector port="8080" address="0.0.0.0" maxThreads="1600" minSpareThreads="100"
maxSpareThreads="250" emptySessionPath="false" enableLookups="false" redirectPort="8443"
acceptCount="800" connectionTimeout="20000" disableUploadTimeout="true" URIEncoding="UTF-8"/>
maxThreads:表示最多同时处理的连接数。应该将线程数(最大线程数)设置比最大预期负载(同时并发的点击)多25%(经验规则)。
acceptCount:当同时连接的人数达到maxThreads时,还可以接收排队的连接。
minSpareThread:指“启动以后,总是保持该数量的线程空闲等待”;设置比预期负载多25%。
maxSpareThread:指“如果超过了minSpareThread,然后总是保持该数量的线程空闲等待”;设置比预期负载多25%。
其中主要修改两个参数maxThreads和acceptCount值。增加maxThreads,减少acceptCount值有利缩短系统的响应时间。
但是maxThreads和acceptCount的总和最高值不能超过6000,而且maxThreads过大会增加CPU和内存消耗,
故低配置用户可通过降低maxThreads并同时增大acceptCount值来保证系统的稳定。
下表罗列出了在不同并发情况下jboss参数与并发在线的一般关系。
并发数服务器内存jboss参数
maxThreadsacceptCount
50以下2G256800
50-3004G6001024
300-8008G10241528
800-10008G10242048
1000-120012G15262048
1200-150016G20482048
top命令找到占用CPU最高的java线程?
1、top -Hp 28174 -d 2 -n 6
解释:查找进程号pid=28174的所有线程,每隔2秒显示一次,共6次。
找到最耗CPU的线程是20766,转换成16进制511e
2、/usr/java/jdk1.6.0_37/bin/jstack -l 28174 | grep 511e -A 20
用jstack命令查看线程堆栈,-A 20表示显示以511e开头的后20行记录。
例:
"DestroyJavaVM" prio=10 tid=0x00002aaab4268800 nid=0x511e waiting on condition [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
Locked ownable synchronizers:
- None
(此方法还能看到哪个线程存活时间最长)
jsp、freemarker、velocity优缺点
jsp优点:官方标准,支持TAG、EL,使用java代码,丰富的第三方标签库。缺点是前后分离较难,容易破坏MVC结构。
velocity优点:不能写java代码,严格的前后分离;性能最佳;使用表达式语言。缺点是非官方标准;文档少。
freemarker优点:不能写java代码,严格的前后分离;性能较好;使用表达式语言;内置大量常用功能;支持jsp标签。缺点是非官方标准;文档少。
JSF优点是开发大量数据交互和表单展示时比较方便;缺点是学习曲线陡峭,UI组件及其生命周期需要学习,组件限制了前端展示的自由度,
对于企业内部系统比较合适。最好的框架是自己开发的框架,修改方便,了解框架极限。
velocity在与spring一起使用时,要使得vhtml模板能使用jsp里面的request对象,要在spring-mvc.xml中的
<bean id="velocityViewResolver"
配置
<property name="requestContextAttribute" value="req"/>
这样在vhtml中可使用如下方法:
${req.contextPath} == /biz (注意前面有个斜杠/)
Velocity与jQuery的$发生冲突时的三种解决办法:
Velocity的$与Jquery的$发生冲突时的解决方法有以下几个:
1、使用jQuery代替$。
如:jQuery.ajax();
缺点:不适合扩展,一旦替换成第三方库时,那就麻烦大发
2、使用jQuery.noConflict。
如:var j = jQuery.noConflict(); j.ajax();
缺点:当使用jQuery的相关插件时,会使得插件失效哦!
3、wrap jQuery中的冲突方法。
如$.ajax()在Velocity中会冲突,则重新定义如下:
function dw(){}
dw.ajax=function(s){
jQuery.ajax(s);
}
dw.ajax();
方案3基本上解决了1、2中的缺点~~~故推荐使用第三种方法!
SPRING MVC 的请求参数获取的几种方法?
1、通过@PathVariabl注解获取路径中传递参数
JAVA
@RequestMapping(value = "/{id}/{str}")
public ModelAndView helloWorld(@PathVariable String id, @PathVariable String str) {
System.out.println(id);
System.out.println(str);
return new ModelAndView("/helloWorld");
}
2、用@ModelAttribute注解获取POST请求的FORM表单数据
JSP
<form method="post" action="hao.do">
a: <input id="a" type="text" name="a"/>
b: <input id="b" type="text" name="b"/>
<input type="submit" value="Submit" />
</form>
JAVA pojo
public class Pojo{
private String a;
private int b;
}
JAVA controller
@RequestMapping(method = RequestMethod.POST)
public String processSubmit(@ModelAttribute("pojo") Pojo pojo) {
return "helloWorld";
}
3、直接用HttpServletRequest获取
JAVA
@RequestMapping(method = RequestMethod.GET)
public String get(HttpServletRequest request, HttpServletResponse response) {
System.out.println(request.getParameter("a"));
return "helloWorld";
}
4、用注解@RequestParam绑定请求参数a到变量a
当请求参数a不存在时会有异常发生,可以通过设置属性required=false解决,
例如: @RequestParam(value="a", required=false)
JAVA
@RequestMapping(value = "/requestParam", method = RequestMethod.GET)
public String setupForm(@RequestParam("a") String a, ModelMap model) {
System.out.println(a);
return "helloWorld";}
<UL id=comparePro>
<li id=compare_prod_list_001>信用卡贷款活动产品1-中国建设银行</li>
<li id=compare_prod_list_002>信用卡贷款活动产品2-中国建设银行</li>
<li id=compare_prod_list_003>信用卡贷款活动产品3-中国建设银行</li>
<li id=other>其他</li>
</UL>
要取到所有 id以compare_prod_list_开头的<li> : var list=$('li[id^=compare_prod_list_]');
遍历json 对象的属性并且动态添加属性
var person= {
name: 'zhangsan',
pass: '123' ,
'sni.ni' : 'sss',
hello:function (){
for(var i=0;i<arguments.length;i++){
//在不知参数个数情况下可通过for循环遍历
// arguments这个是js 默认提供
alert("arr["+i+"]="+arguments[i]);
}
}
}
//遍历属性
for(var item in person){
if(typeof person[item] === 'string'){
alert("person中"+item+"的值="+person[item]);
}else if(typeof person[item] === 'function'){
person[item](1,1);//js 的function的参数可以动态的改变
}
}
//添加属性
person.isMe = 'kaobian'; // 这种是属性名字正常的
//当属性名字不正常时,像下面这种,必须用这种形式的,
person['isMe.kaobian'] = 'hello kaobian'; //上面的也可以用下面的形式
for(var item in person){
if(typeof person[item] === 'string'){
alert("person中"+item+"的值="+person[item]);
}else if(typeof person[item] === 'function'){
person[item](1,1);
}
}
调用load方法的完整格式是:load( url, [data], [callback] ),其中
url:是指要导入文件的地址。
data:可选参数;因为Load不仅仅可以导入静态的html文件,还可以导入动态脚本,例如PHP文件,所以要导入的是动态文件时,我们可以把要传递的参数放在这里。
callback:可选参数;是指调用load方法并得到服务器响应后,再执行的另外一个函数。
一:如何使用data
1.加载一个php文件,该php文件不含传递参数
$("#myID").load("test.php");
//在id为#myID的元素里导入test.php运行后的结果
2. 加载一个php文件,该php文件含有一个传递参数
$("#myID").load("test.php",{"name" : "Adam"});
//导入的php文件含有一个传递参数,类似于:test.php?name=Adam
3. 加载一个php文件,该php文件含有多个传递参数。注:参数间用逗号分隔
$("#myID").load("test.php",{"name" : "Adam" ,"site":"61dh.com"});
//导入的php文件含有一个传递参数,类似于:test.php?name=Adam&site=61dh.com
4. 加载一个php文件,该php文件以数组作为传递参数
$("#myID").load("test.php",{'myinfo[]', ["Adam", "61dh.com"]});
//导入的php文件含有一个数组传递参数。
注意:使用load,这些参数是以POST的方式传递的,因此在test.php里,不能用GET来获取参数。
$(":input") 选择所有的表单输入元素,包括input, textarea, select 和 button
$(":text") 选择所有的text input元素
$("#myELement") 选择id值等于myElement的元素,id值不能重复在文档中只能有一个id值是myElement所以得到的是唯一的元素
$("div") 选择所有的div标签元素,返回div元素数组
$(".myClass") 选择使用myClass类的css的所有元素
$("*") 选择文档中的所有的元素,可以运用多种的选择方式进行联合选择:例如$("#myELement,div,.myclass")
层叠选择器:
$("form input") 选择所有的form元素中的input元素
$("#main > *") 选择id值为main的所有的子元素
$("label + input") 选择所有的label元素的下一个input元素节点,经测试选择器返回的是label标签后面直接跟一个input标签的所有input标签元素
$("#prev ~ div") 同胞选择器,该选择器返回的为id为prev的标签元素的所有的属于同一个父元素的div标签
基本过滤选择器:
$("tr:first") 选择所有tr元素的第一个
$("tr:last") 选择所有tr元素的最后一个
$("input:not(:checked) + span")
过滤掉:checked的选择器的所有的input元素
$("tr:even") 选择所有的tr元素的第0,2,4... ...个元素(注意:因为所选择的多个元素时为数组,所以序号是从0开始)
$("tr:odd") 选择所有的tr元素的第1,3,5... ...个元素
$("td:eq(2)") 选择所有的td元素中序号为2的那个td元素
$("td:gt(4)") 选择td元素中序号大于4的所有td元素
$("td:ll(4)") 选择td元素中序号小于4的所有的td元素
$(":header")
$("div:animated")
内容过滤选择器:
$("div:contains('John')") 选择所有div中含有John文本的元素
$("td:empty") 选择所有的为空(也不包括文本节点)的td元素的数组
$("div:has(p)") 选择所有含有p标签的div元素
$("td:parent") 选择所有的以td为父节点的元素数组
可视化过滤选择器:
$("div:hidden") 选择所有的被hidden的div元素
$("div:visible") 选择所有的可视化的div元素
属性过滤选择器:
$("div[id]") 选择所有含有id属性的div元素
$("input[name='newsletter']") 选择所有的name属性等于'newsletter'的input元素
$("input[name!='newsletter']") 选择所有的name属性不等于'newsletter'的input元素
$("input[name^='news']") 选择所有的name属性以'news'开头的input元素
$("input[name$='news']") 选择所有的name属性以'news'结尾的input元素
$("input[name*='man']") 选择所有的name属性包含'news'的input元素
$("input[id][name$='man']") 可以使用多个属性进行联合选择,该选择器是得到所有的含有id属性并且那么属性以man结尾的元素
子元素过滤选择器:
$("ul li:nth-child(2)"),$("ul li:nth-child(odd)"),$("ul li:nth-child(3n + 1)")
$("div span:first-child") 返回所有的div元素的第一个子节点的数组
$("div span:last-child") 返回所有的div元素的最后一个节点的数组
$("div button:only-child") 返回所有的div中只有唯一一个子节点的所有子节点的数组
表单元素选择器:
$(":input") 选择所有的表单输入元素,包括input, textarea, select 和 button
$(":text") 选择所有的text input元素
$(":password") 选择所有的password input元素
$(":radio") 选择所有的radio input元素
$(":checkbox") 选择所有的checkbox input元素
$(":submit") 选择所有的submit input元素
$(":image") 选择所有的image input元素
$(":reset") 选择所有的reset input元素
$(":button") 选择所有的button input元素
$(":file") 选择所有的file input元素
$(":hidden") 选择所有类型为hidden的input元素或表单的隐藏域
表单元素过滤选择器:
$(":enabled") 选择所有的可操作的表单元素
$(":disabled") 选择所有的不可操作的表单元素
$(":checked") 选择所有的被checked的表单元素
$("select option:selected") 选择所有的select 的子元素中被selected的元素
选取一个name 为”S_03_22″的input text框的上一个td的text值
$(”input[@name =S_03_22]“).parent().prev().text()
名字以”S_”开始,并且不是以”_R”结尾的
$(”input[@name ^='S_']“).not(”[@name $='_R']“)
一个名为radio_01的radio所选的值
$(”input[@name =radio_01][@checked]“).val();
$("A B") 查找A元素下面的所有子节点,包括非直接子节点
$("A>B") 查找A元素下面的直接子节点 www.2cto.com
$("A+B") 查找A元素后面的兄弟节点,包括非直接子节点
$("A~B") 查找A元素后面的兄弟节点,不包括非直接子节点
unix系统提供两个数据文件:
utmp记录当前登陆进系统的各个用户
wtmp跟踪各个登陆和注销事件
who命令读取utmp并打印
last命令读取wtmp并打印
测试85-/maps/usr/ma_onl/xty/unix>uname -a
AIX P570_H_5 1 6 00C7112D4C00(操作系统 主机名 操作系统主版本 从版本号 硬件号码)
hostname 主机名
超级用户通过此命令设置主机名,该名字通常是TCPIP网络上主机的名字。
测试85-/maps/usr/ma_onl/xty/unix>date -u +%a
Sun
测试85-/maps/usr/ma_onl/xty/unix>date -u +%x
11/09/14
格式输出
测试85-/maps/usr/ma_onl/xty/unix>echo $TZ
Asia/Shanghai
该环境变量决定时区
UNIX下core文件的分析 一般步骤:
1. file core文件,可以显示出core文件是哪个进程产生的
2.使用gdb或者dbx加载core文件, gdb 进程名 core文件
3.where,显示堆栈信息,显示出coredump的地方
使用如下方法提交表单时,recid将不会传到后台。必须在form表单中增加一个input=hidden列,名字叫recid
var path = "${req.contextPath}/vm/edit/$tblcd?recid="+1;
jQuery('#form2').attr("action", path).submit();
0配置的spring mvc需要在web.xml如下配置:
<context:component-scan base-package="com.cup.maps.parameter.bizcontrol.contol" />
<aop:aspectj-autoproxy />
spring aop需要增加到:
<context:component-scan base-package="com.cup.maps.parameter.bizcontrol.contol,com.cup.maps.parameter.bizcontrol.advice">
<context:include-filter type="annotation" expression="org.aspectj.lang.annotation.Aspect" />
</context:component-scan>
<aop:aspectj-autoproxy />
使用stax读取xml:
"<message name="PARAM_EDITPAGE_TYPE_0">0</message>"
1、reader.getAttributeName(0) -> name
2、reader.getAttributeValue(0)-> PARAM_EDITPAGE_TYPE_0
3、reader.getElementText()-> 0
在调用语句3后,1、2都不能调用了,会报错。
jquery复选框全选、全不选?
<input type="checkbox" id="recids" />全选
<input type="checkbox" id="recid" value="$actives.recid"/>
<input type="checkbox" id="recid" value="$actives.recid"/>
function doInit(){//初始化加载
jQuery("#recids").change(function(){
jQuery(":checkbox").prop("checked",this.checked);
});
}
Hibernate
save() 保存持久化对象,返回对应的主键值
persist()保存持久化对象,无返回值
load()加载持久化实例,无匹配时抛出HibernateException异常;如果设置了延迟加载,返回未初始化对象,直到调用该对象方法时,Hibernate才会访问db
get()加载持久化实例,无匹配时返回null;而且无延迟加载功能。
持久化对象的修改,会在flush()时保存入数据库,如:
News n = sess.load(News.class,new Integer(pk));
n.setTitle("");
sess.flush();
对于托管对象,可以采用update() merge() updateOrSave()方法保存修改:
update()
merge() 与update区别是不会持久化给定对象
updateOrSave()
lock() 将某个托管对象重新持久化
delete() 删除持久化实例
Hibernate映射文件
主从表级联操作,持久化实体操作的传播:(默认是none)
<one-to-one name="person" cascade="persist"/>
<one-to-one name="person" cascade="persist,delete,lock"/>
<one-to-one name="person" cascade="all"/>
Hibernate批量插入,多次调用下面语句将导致OutofMemory,解决是每隔若干条save记录后session.flush()+session.clear():
session.save(bean); //session级别缓存。
HQL查询:
session.createQuery("...").setString("","").list();
apache配置负载均衡session粘性?
解决:
1、需要在apache的配置文件httpd.conf里最后一段加上
ProxyPass /mposWcg balancer://wcgbalancer stickySession=JSESSIONID
ProxyPassReverse /mposWcg balancer://wcgbalancer
<Proxy balancer://wcgbalancer>
BalancerMember http://172.18.63.69:12000/mposWcg loadfactor=1 route=Node1
BalancerMember http://172.18.63.70:12000/mposWcg loadfactor=1 route=Node2
</Proxy>
2、增加jboss的server.xml中jvmRoute并重启,两台设置要不一样
vi ~/upjas/upjas-minimal/server/default/deploy/jbossweb.sar/server.xml
修改 <Engine name="jboss.web" defaultHost="localhost">
成<Engine name="jboss.web" defaultHost="localhost" jvmRoute="Node1">
原理是给浏览器的Cookie中出了jsessionid外还增加了jvmRoute值,apache可以知道是从哪个jboss来的。
Cookie:"JSESSIONID=33430E7895899E3CD7A051A4457D1D85.Node1"
严重: Exception sending context initialized event to listener instance of class org.springframework.web.context.ContextLoaderListener
org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'sessionFactory' defined in ServletContext resource [/WEB-INF/applicationContext.xml]: Initialization of bean failed; nested exception is java.lang.NoClassDefFoundError: javax/transaction/TransactionManager
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.doCreateBean(AbstractAutowireCapableBeanFactory.java:532)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.createBean(AbstractAutowireCapableBeanFactory.java:461)
at org.springframework.beans.factory.support.AbstractBeanFactory$1.getObject(AbstractBeanFactory.java:295)
at org.springframework.beans.factory.support.DefaultSingletonBeanRegistry.getSingleton(DefaultSingletonBeanRegistry.java:223)
at org.springframework.beans.factory.support.AbstractBeanFactory.doGetBean(AbstractBeanFactory.java:292)
at org.springframework.beans.factory.support.AbstractBeanFactory.getBean(AbstractBeanFactory.java:194)
at org.springframework.beans.factory.support.DefaultListableBeanFactory.preInstantiateSingletons(DefaultListableBeanFactory.java:608)
at org.springframework.context.support.AbstractApplicationContext.finishBeanFactoryInitialization(AbstractApplicationContext.java:932)
at org.springframework.context.support.AbstractApplicationContext.refresh(AbstractApplicationContext.java:479)
at org.springframework.web.context.ContextLoader.configureAndRefreshWebApplicationContext(ContextLoader.java:389)
at org.springframework.web.context.ContextLoader.initWebApplicationContext(ContextLoader.java:294)
at org.springframework.web.context.ContextLoaderListener.contextInitialized(ContextLoaderListener.java:112)
at org.apache.catalina.core.StandardContext.listenerStart(StandardContext.java:4206)
at org.apache.catalina.core.StandardContext.start(StandardContext.java:4705)
at org.apache.catalina.core.ContainerBase.start(ContainerBase.java:1057)
at org.apache.catalina.core.StandardHost.start(StandardHost.java:840)
at org.apache.catalina.core.ContainerBase.start(ContainerBase.java:1057)
at org.apache.catalina.core.StandardEngine.start(StandardEngine.java:463)
at org.apache.catalina.core.StandardService.start(StandardService.java:525)
at org.apache.catalina.core.StandardServer.start(StandardServer.java:754)
at org.apache.catalina.startup.Catalina.start(Catalina.java:595)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:39)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:25)
at java.lang.reflect.Method.invoke(Method.java:597)
at org.apache.catalina.startup.Bootstrap.start(Bootstrap.java:289)
at org.apache.catalina.startup.Bootstrap.main(Bootstrap.java:414)
Caused by: java.lang.NoClassDefFoundError: javax/transaction/TransactionManager
at java.lang.Class.getDeclaredMethods0(Native Method)
at java.lang.Class.privateGetDeclaredMethods(Class.java:2436)
at java.lang.Class.privateGetPublicMethods(Class.java:2556)
at java.lang.Class.getMethods(Class.java:1412)
at org.springframework.beans.ExtendedBeanInfoFactory.supports(ExtendedBeanInfoFactory.java:53)
at org.springframework.beans.ExtendedBeanInfoFactory.getBeanInfo(ExtendedBeanInfoFactory.java:44)
at org.springframework.beans.CachedIntrospectionResults.<init>(CachedIntrospectionResults.java:236)
at org.springframework.beans.CachedIntrospectionResults.forClass(CachedIntrospectionResults.java:152)
at org.springframework.beans.BeanWrapperImpl.getCachedIntrospectionResults(BeanWrapperImpl.java:321)
at org.springframework.beans.BeanWrapperImpl.getPropertyDescriptorInternal(BeanWrapperImpl.java:351)
at org.springframework.beans.BeanWrapperImpl.isWritableProperty(BeanWrapperImpl.java:427)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.applyPropertyValues(AbstractAutowireCapableBeanFactory.java:1395)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.populateBean(AbstractAutowireCapableBeanFactory.java:1134)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.doCreateBean(AbstractAutowireCapableBeanFactory.java:522)
... 26 more
Caused by: java.lang.ClassNotFoundException: javax.transaction.TransactionManager
at org.apache.catalina.loader.WebappClassLoader.loadClass(WebappClassLoader.java:1680)
at org.apache.catalina.loader.WebappClassLoader.loadClass(WebappClassLoader.java:1526)
... 40 more
解决:加入jta.jar
java.lang.ClassNotFoundException: antlr.RecognitionException
at org.apache.catalina.loader.WebappClassLoader.loadClass(WebappClassLoader.java:1680)
at org.apache.catalina.loader.WebappClassLoader.loadClass(WebappClassLoader.java:1526)
at org.hibernate.hql.ast.ASTQueryTranslatorFactory.createQueryTranslator(ASTQueryTranslatorFactory.java:58)
at org.hibernate.engine.query.HQLQueryPlan.<init>(HQLQueryPlan.java:98)
at org.hibernate.engine.query.HQLQueryPlan.<init>(HQLQueryPlan.java:80)
at org.hibernate.engine.query.QueryPlanCache.getHQLQueryPlan(QueryPlanCache.java:124)
at org.hibernate.impl.AbstractSessionImpl.getHQLQueryPlan(AbstractSessionImpl.java:156)
at org.hibernate.impl.AbstractSessionImpl.createQuery(AbstractSessionImpl.java:135)
at org.hibernate.impl.SessionImpl.createQuery(SessionImpl.java:1694)
at org.springframework.orm.hibernate3.HibernateTemplate$30.doInHibernate(HibernateTemplate.java:914)
at org.springframework.orm.hibernate3.HibernateTemplate$30.doInHibernate(HibernateTemplate.java:912)
at org.springframework.orm.hibernate3.HibernateTemplate.doExecute(HibernateTemplate.java:406)
at org.springframework.orm.hibernate3.HibernateTemplate.executeWithNativeSession(HibernateTemplate.java:374)
at org.springframework.orm.hibernate3.HibernateTemplate.find(HibernateTemplate.java:912)
at com.cup.maps.parameter.bizcontrol.dao.ParamDao.getInqFldByTblcd(ParamDao.java:14)
at com.cup.maps.parameter.bizcontrol.service.ParamSerivceImpl.genInqFldInParaFileds(ParamSerivceImpl.java:118)
at com.cup.maps.parameter.bizcontrol.service.ParamSerivceImpl.setParamQueryInq(ParamSerivceImpl.java:103)
at com.cup.maps.parameter.bizcontrol.contol.InitController.bizParaminit(InitController.java:41)
at com.cup.maps.parameter.bizcontrol.contol.InitController$$FastClassByCGLIB$$886e2fe6.invoke(<generated>)
at org.springframework.cglib.proxy.MethodProxy.invoke(MethodProxy.java:204)
at org.springframework.aop.framework.CglibAopProxy$CglibMethodInvocation.invokeJoinpoint(CglibAopProxy.java:698)
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:150)
at org.springframework.aop.aspectj.MethodInvocationProceedingJoinPoint.proceed(MethodInvocationProceedingJoinPoint.java:91)
at com.cup.maps.parameter.bizcontrol.advice.DealforVm.privcheck(DealforVm.java:41)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:39)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:25)
at java.lang.reflect.Method.invoke(Method.java:597)
at org.springframework.aop.aspectj.AbstractAspectJAdvice.invokeAdviceMethodWithGivenArgs(AbstractAspectJAdvice.java:621)
at org.springframework.aop.aspectj.AbstractAspectJAdvice.invokeAdviceMethod(AbstractAspectJAdvice.java:610)
at org.springframework.aop.aspectj.AspectJAroundAdvice.invoke(AspectJAroundAdvice.java:65)
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:172)
at org.springframework.aop.framework.adapter.AfterReturningAdviceInterceptor.invoke(AfterReturningAdviceInterceptor.java:51)
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:172)
at org.springframework.aop.interceptor.ExposeInvocationInterceptor.invoke(ExposeInvocationInterceptor.java:91)
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:172)
at org.springframework.aop.framework.CglibAopProxy$DynamicAdvisedInterceptor.intercept(CglibAopProxy.java:631)
at com.cup.maps.parameter.bizcontrol.contol.InitController$$EnhancerByCGLIB$$529de169.bizParaminit(<generated>)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:39)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:25)
at java.lang.reflect.Method.invoke(Method.java:597)
at org.springframework.web.bind.annotation.support.HandlerMethodInvoker.invokeHandlerMethod(HandlerMethodInvoker.java:176)
at org.springframework.web.servlet.mvc.annotation.AnnotationMethodHandlerAdapter.invokeHandlerMethod(AnnotationMethodHandlerAdapter.java:440)
at org.springframework.web.servlet.mvc.annotation.AnnotationMethodHandlerAdapter.handle(AnnotationMethodHandlerAdapter.java:428)
at org.springframework.web.servlet.DispatcherServlet.doDispatch(DispatcherServlet.java:925)
at org.springframework.web.servlet.DispatcherServlet.doService(DispatcherServlet.java:856)
at org.springframework.web.servlet.FrameworkServlet.processRequest(FrameworkServlet.java:936)
at org.springframework.web.servlet.FrameworkServlet.doGet(FrameworkServlet.java:827)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:617)
at org.springframework.web.servlet.FrameworkServlet.service(FrameworkServlet.java:812)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:723)
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:290)
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:206)
at org.apache.catalina.core.StandardWrapperValve.invoke(StandardWrapperValve.java:233)
at org.apache.catalina.core.StandardContextValve.invoke(StandardContextValve.java:191)
at org.apache.catalina.core.StandardHostValve.invoke(StandardHostValve.java:127)
at org.apache.catalina.valves.ErrorReportValve.invoke(ErrorReportValve.java:103)
at org.apache.catalina.core.StandardEngineValve.invoke(StandardEngineValve.java:109)
at org.apache.catalina.connector.CoyoteAdapter.service(CoyoteAdapter.java:293)
at org.apache.coyote.http11.Http11AprProcessor.process(Http11AprProcessor.java:879)
at org.apache.coyote.http11.Http11AprProtocol$Http11ConnectionHandler.process(Http11AprProtocol.java:617)
at org.apache.tomcat.util.net.AprEndpoint$Worker.run(AprEndpoint.java:1760)
at java.lang.Thread.run(Thread.java:662)
解决:引入antlr.jar
org.hibernate.hql.ast.QuerySyntaxException: TblMamgmParaFldAttr is not mapped [from TblMamgmParaFldAttr a]
at org.hibernate.hql.ast.util.SessionFactoryHelper.requireClassPersister(SessionFactoryHelper.java:181)
at org.hibernate.hql.ast.tree.FromElementFactory.addFromElement(FromElementFactory.java:109)
解决:使用hbm.xml中的class name 而不是table真实表名。
find("from TblMamgmParaFldAttr a");
org.hibernate.MappingException: Unknown entity: com.cup.maps.parameter.bizcontrol.model.hibernate.TblMamgmParaFldAttr
at org.hibernate.impl.SessionFactoryImpl.getEntityPersister(SessionFactoryImpl.java:629)
at org.hibernate.event.def.DefaultLoadEventListener.onLoad(DefaultLoadEventListener.java:91)
解决:spring和hibernate整合在配置sessionFactory时有两种配置方法。
方法一:不要hibernate.cfg.xml,在applicationContext.xml中配置如下
<bean id="sessionFactory"
class="org.springframework.orm.hibernate3.LocalSessionFactoryBean">
<property name="dataSource" ref="myDataSource"></property>
<property name="mappingResources">
<list>
<value>com/cup/maps/parameter/bizcontrol/model/hibernate/TblMamgmParaFldAttr.hbm.xml</value>
</list>
</property>
<property name="hibernateProperties">
<props>
<prop key="hibernate.dialect">
org.hibernate.dialect.DB2Dialect
</prop>
<prop key="hibernate.show_sql">true</prop>
<prop key="hibernate.connection.release_mode">
auto
</prop>
<prop key="hibernate.transaction.auto_close_session">
true
</prop>
<prop key="show_sql">true</prop>
</props>
</property>
</bean>
方法二:
applicationContext.xml中配置:
<bean id="sessionFactory"
class="org.springframework.orm.hibernate3.LocalSessionFactoryBean">
<property name="dataSource" ref="myDataSource"></property>
<property name="configLocations">
<value>classpath:hibernate.cfg.xml</value>
</property>
</bean>
hibernate.cfg.xml中配置(propertry要再mapping之前):
<?xml version='1.0' encoding='UTF-8'?>
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory>
<property name="dialect">org.hibernate.dialect.DB2Dialect</property>
<property name="show_sql">true</property>
<property name="hibernate.show_sql">true</property>
<property name="hibernate.connection.release_mode">auto</property>
<property name="hibernate.transaction.auto_close_session">true</property>
<mapping
resource="com/cup/maps/parameter/bizcontrol/model/hibernate/TblMamgmIndustryInsAttr.hbm.xml" />
<mapping
resource="com/cup/maps/parameter/bizcontrol/model/hibernate/TblMamgmParaFldAttr.hbm.xml" />
</session-factory>
</hibernate-configuration>
Caused by: java.lang.NoClassDefFoundError: javassist/util/proxy/MethodFilter
...
at org.hibernate.tuple.entity.PojoEntityTuplizer.<init>(PojoEntityTuplizer.java:77)
... 16 more
Caused by: java.lang.ClassNotFoundException: javassist.util.proxy.MethodFilter
at java.net.URLClassLoader$1.run(URLClassLoader.java:200)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:188)
at java.lang.ClassLoader.loadClass(ClassLoader.java:307)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:301)
at java.lang.ClassLoader.loadClass(ClassLoader.java:252)
at java.lang.ClassLoader.loadClassInternal(ClassLoader.java:320)
... 21 more
解决:缺少javassist.jar,在upjas\upjas-minimal\lib下。
org.hibernate.QueryException: could not resolve property: tblcd of: com.cup.maps.parameter.bizcontrol.model.hibernate.TblMamgmParaFldAttr
at org.hibernate.persister.entity.AbstractPropertyMapping.propertyException(AbstractPropertyMapping.java:67)
at org.hibernate.persister.entity.AbstractPropertyMapping.toType(AbstractPropertyMapping.java:61)
解决:字段名有问题,tblcd改成tblCd。
criteria.add(Restrictions.eq("tblcd", tblcd)).add(Restrictions.eq("inqFldIn", "1"));
改成
criteria.add(Restrictions.eq("tblCd", tblcd)).add(Restrictions.eq("inqFldIn", "1"));
org.hibernate.HibernateException: No Hibernate Session bound to thread, and configuration does not allow creation of non-transactional one here
at org.springframework.orm.hibernate3.SpringSessionContext.currentSession(SpringSessionContext.java:64)
at org.hibernate.impl.SessionFactoryImpl.getCurrentSession(SessionFactoryImpl.java:623)
解决:
Session session = sessionFactory.getCurrentSession();这句报错。因为是直接从spring中获得的bean。
正确代码如下:
SessionFactory sessionFactory = (SessionFactory)SpringContextUtil.getBean("mgmSessionFactory");
Session session = sessionFactory.openSession();
Transaction tx = session.beginTransaction();
。。。
tx.commit();
//session.close(); 无需调用close
org.hibernate.SessionException: Session was already closed
org.hibernate.impl.SessionImpl.close(SessionImpl.java:304)
com.cup.maps.parameter.bizcontrol.cache.ParamCache.init(ParamCache.java:60)
解决:如果不是使用的SessionFactory.getSession()来获得Session。而是使用SessionFactory.getCurrentSession()或者sessionFactory.openSession();
方法来获得Session时,当事务结束的时候,不管是提交还是回滚事务,hibernate会自动关闭Session的。
因此在tx.commit();后面不需要再session.close();
java.lang.UnsupportedOperationException: The user must supply a JDBC connection
at org.hibernate.connection.UserSuppliedConnectionProvider.getConnection(UserSuppliedConnectionProvider.java:54)
at org.hibernate.jdbc.ConnectionManager.openConnection(ConnectionManager.java:446)
解决:
win7 TortoiseCVS-1.12.5 cvs checkout乱码?
解决:卸载当前cvsnt软件,重新安装老版本cvsnt_setup.exe,重启win7就好了
解决Spring MVC ResponseBody 乱码问题?
在SpringMVC中,ResponseBody返回的中文是乱码,google了一下,原因是这可以说是spring mvc的一个bug,
spring MVC有一系列HttpMessageConverter去处理用@ResponseBody注解的返回值,如返回list则使用
MappingJacksonHttpMessageConverter,返回string,则使用 StringHttpMessageConverter,这个convert
使用的是字符集是iso-8859-1,而且是final的
public static final Charset DEFAULT_CHARSET = Charset.forName("ISO-8859-1");
解决方法是在
<context:annotation-config />
前面加入以下配置:
<bean class="org.springframework.web.servlet.mvc.annotation.AnnotationMethodHandlerAdapter" >
<property name="messageConverters">
<list>
<bean class = "org.springframework.http.converter.StringHttpMessageConverter">
<property name = "supportedMediaTypes">
<list>
<value>text/plain;charset=UTF-8</value>
</list>
</property>
</bean>
</list>
</property>
</bean>
但是也有网友认为前面这种方式不太优雅,而且不一定有效,经试验下面这种方法也可以:
@RequestMapping(value="qxyjqyresult",produces = "plain/text; charset=UTF-8")
@ResponseBody
public String getQxyjqyResult(String filename) throws Throwable {
return "中文"
}
也就是用produces。
使用另外一个相关联的对象的标识符作为主键。
<id>元素中的<generator>用来为该持久化类的实例生成唯一的标识,hibernate提供了很多内置的实现。
Increment:由hibernate自动递增生成标识符,用于为long, short或者int类型生成唯一标识。
identity :由底层数据库生成标识符(自动增长),返回的标识符是 long, short 或者int类型的。
sequence :hibernate根据底层数据库序列生成标识符,返回的标识符 是long, short或者 int类型的。
hilo :使用一个高/低位算法来高效的生成long, short 或者int类型的标识符。
uuid.hex :用一个128-bit的UUID算法生成32位字符串类型的标识符。
native :根据底层数据库的能力选择identity, sequence 或者hilo中的一个。
assigned :让应用程序在save()之前为对象分配一个标示符。
foreign :使用另外一个相关联的对象的标识符。和<one-to-one>联合一起使用。
List list = session
.createQuery(
"select b.id.drdlItemKey,b.drdlItemVal from TblMamgmDrdlCfg a,TblMamgmDrdlItemDef b where a.drdlId = b.id.drdlId and a.drdlNm = :dropDownNm")
.setString("dropDownNm", dropDownNm).list();
联合主键在hbm.xml中的联合主键配置是: <composite-id name="id" class="com.cup.maps.parameter.bizcontrol.model.hibernate.TblMamgmDrdlItemDefId">
原生sql中使用则是b.id.drdlItemKey。
org.hibernate.LazyInitializationException: failed to lazily initialize a collection of role: com.cup.maps.parameter.bizcontrol.model.hibernate.TblMamgmDrdlCfg.drdlItemList, no session or session was closed
解决:这个是懒加载异常,就是在查询时没有加载关联表的对象,你读取这个关联对象的时候,hibernate的session已经关闭,所以无法获取对象。
你可以在配置文件里关闭懒加载 lazy=false
spring mvc中遇到了如何实现页面跳转的问题.比如在页面A中的提交按钮用户提交后,需要重定向到另外一个新的页面,并且有可能要把一些参数带
过去.
这其实在实现中有两个方法
1 在controller中实现redirect,可以使用sendRedirect()方法,然后返回
public ModelAndView handleRequest(HttpServletRequest request, HttpServletResponse response) throws Exception
{
........
response.sendRedirect("photohouxuandetail.do?pid="+pid);
return null;
}
2 还可以用redirect来实现,这样viewResolver认为是重定向操作,不再渲染该视图了,而是直接向客户端发出redirect响应
return new ModelAndView("redirect:photohouxuandetail.do?pid="+pid);
org.springframework.dao.DataIntegrityViolationException: not-null property references a null or transient value: com.cup.maps.parameter.bizcontrol.model.hibernate.TblMamgmDrdlItemDef.operIn; nested exception is org.hibernate.PropertyValueException: not-null property references a null or transient value: com.cup.maps.parameter.bizcontrol.model.hibernate.TblMamgmDrdlItemDef.operIn
at org.springframework.orm.hibernate3.SessionFactoryUtils.convertHibernateAccessException(SessionFactoryUtils.java:665)
解决:在Hibernate中使用数据库字段默认值的配置
1、在相关表的映射XML文件的class项增加:dynamic-insert="true"
2、同时需在相关字段设置:not-null="false"
org.springframework.dao.DataIntegrityViolationException: could not update: [com.cup.maps.parameter.bizcontrol.model.hibernate.TblMamgmDrdlItemDef#component[drdlId,drdlItemKey]{drdlItemKey=1111, drdlId=1111}]; SQL [update MA_MGMDB.TBL_MAMGM_DRDL_ITEM_DEF set DRDL_ITEM_VAL=?, OPER_IN=?, EVENT_ID=?, REC_ID=?, REC_UPD_USR_ID=?, REC_UPD_TS=?, REC_CRT_TS=? where DRDL_ID=? and DRDL_ITEM_KEY=?]; constraint [null]; nested exception is org.hibernate.exception.ConstraintViolationException: could not update: [com.cup.maps.parameter.bizcontrol.model.hibernate.TblMamgmDrdlItemDef#component[drdlId,drdlItemKey]{drdlItemKey=1111, drdlId=1111}]
at org.springframework.orm.hibernate3.SessionFactoryUtils.convertHibernateAccessException(SessionFactoryUtils.java:643)
at org.springframework.orm.hibernate3.HibernateAccessor.convertHibernateAccessException(HibernateAccessor.java:412)
解决:DataIntegrityViolationException。字段对应属性非空,改成not-null="false"
严重: Exception sending context initialized event to listener instance of class org.springframework.web.context.ContextLoaderListener
org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'paramService' defined in ServletContext resource [/WEB-INF/applicationContext.xml]: Initialization of bean failed; nested exception is org.springframework.beans.factory.BeanNotOfRequiredTypeException: Bean named 'bziControltxAdvice' must be of type [org.aopalliance.aop.Advice], but was actually of type [org.springframework.transaction.interceptor.TransactionInterceptor]
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.doCreateBean(AbstractAutowireCapableBeanFactory.java:532)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.createBean(AbstractAutowireCapableBeanFactory.java:461)
at org.springframework.beans.factory.support.AbstractBeanFactory$1.getObject(AbstractBeanFactory.java:295)
解决:TransactionInterceptor是 org.aopalliance.aop.Advice
的一个实现,可能是Jar包的冲突。
到jar包中去查看。
我的问题是: aopalliance-1.0.jar 和 aopalliance-alpha1.jar之间的冲突。
org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'dataTableController': Injection of autowired dependencies failed; nested exception is org.springframework.beans.factory.BeanCreationException: Could not autowire field: com.cup.maps.parameter.bizcontrol.service.ParamSerivceImpl com.cup.maps.parameter.bizcontrol.contol.DataTableController.pService; nested exception is org.springframework.beans.factory.NoSuchBeanDefinitionException: No qualifying bean of type [com.cup.maps.parameter.bizcontrol.service.ParamSerivceImpl] found for dependency: expected at least 1 bean which qualifies as autowire candidate for this dependency. Dependency annotations: {@org.springframework.beans.factory.annotation.Autowired(required=true)}
at org.springframework.beans.factory.annotation.AutowiredAnnotationBeanPostProcessor.postProcessPropertyValues(AutowiredAnnotationBeanPostProcessor.java:288)
解决:强制转换的必须是接口类ParamService,而不是实际类ParamSerivceImpl
ParamService pService = (ParamSerivceImpl) SpringContextUtil.getBean("paramService");
改成
ParamService pService = (ParamService) SpringContextUtil.getBean("paramService");
Hibernate: select tmpmamgmin_.INDUSTRY_INS_ATTR_CD, tmpmamgmin_.INDUSTRY_INS_ATTR_NM as INDUSTRY2_6_, tmpmamgmin_.INDUSTRY_INS_ID_CD as INDUSTRY3_6_, tmpmamgmin_.INDUSTRY_INS_CATA_OPT as INDUSTRY4_6_, tmpmamgmin_.TEST_MD as TEST5_6_, tmpmamgmin_.RVSL_IN as RVSL6_6_, tmpmamgmin_.TO_RVSL_IN as TO7_6_, tmpmamgmin_.SYS_TO_SYS_FLAG as SYS8_6_, tmpmamgmin_.PROD_CUP_OPER_SPEC as PROD9_6_, tmpmamgmin_.CHNL_LD_CUP_OPER_SPEC as CHNL10_6_, tmpmamgmin_.CHNL_LD_CUP_BRANCH_OPER_SPEC as CHNL11_6_, tmpmamgmin_.CHNL_OPER_SPEC as CHNL12_6_, tmpmamgmin_.SP_OPER_SPEC as SP13_6_, tmpmamgmin_.SUCC_SP_RESP_INF as SUCC14_6_, tmpmamgmin_.REPAY_SP_RESP_INF as REPAY15_6_, tmpmamgmin_.NOTOUTBILL_SP_RESP_INF as NOTOUTBILL16_6_, tmpmamgmin_.SPEC_SP_RESP_INF as SPEC17_6_, tmpmamgmin_.CORRECT_USR_NO_SP_RESP_INF as CORRECT18_6_, tmpmamgmin_.REMARK as REMARK6_, tmpmamgmin_.OPER_IN as OPER20_6_, tmpmamgmin_.EVENT_ID as EVENT21_6_, tmpmamgmin_.REC_ID as REC22_6_, tmpmamgmin_.REC_UPD_USR_ID as REC23_6_, tmpmamgmin_.REC_UPD_TS as REC24_6_, tmpmamgmin_.REC_CRT_TS as REC25_6_ from MA_MGMDB.TMP_MAMGM_INDUSTRY_INS_ATTR tmpmamgmin_ where tmpmamgmin_.INDUSTRY_INS_ATTR_CD=?
org.springframework.orm.hibernate3.HibernateSystemException: identifier of an instance of com.cup.maps.parameter.bizcontrol.model.hibernate.TblMamgmIndustryInsAttr was altered from 00002400-1-001 to 00002400-1-001; nested exception is org.hibernate.HibernateException: identifier of an instance of com.cup.maps.parameter.bizcontrol.model.hibernate.TblMamgmIndustryInsAttr was altered from 00002400-1-001 to 00002400-1-001
at org.springframework.orm.hibernate3.SessionFactoryUtils.convertHibernateAccessException(SessionFactoryUtils.java:690)
解决:实体中主键被修改了,所以报错。从00002400-1-001 改成了00002400-1-001,因为页面trim的关系。
spring多次执行flush也不会有问题:
this.getHibernateTemplate().flush();
在hibernate中实现oracle的主键自增策略
1、在oracle 首先创建sequence
create sequence seq_id
minvalue 1
start with 1
increment by 1
cache 20;
2.在你的hbm.xml中的配置
<id column="ID0000" name="id" type="integer">
<generator class="sequence">
<param name="sequence">seq_id</param>
</generator>
</id>
spring3中bean自动注入
@Resource(name="paramService")
ParamService paramService;
在dwr_spring.xml中配置的bean,必须在applicationContext.xml中配置,spring-mvc.xml不可以。
spring托管类,要想达到这个效果:在初始化并注入所有属性后,执行某个方法:
1、实现InitializingBean
public class ParamCache implements InitializingBean
2、实现这个方法afterPropertiesSet
public void afterPropertiesSet() throws Exception {
init();
}
使用sessionFactory时未绑定事务,使用方法:
Session session = sessionFactory.openSession();
Transaction tx = session.beginTransaction();
Criteria criteria = session.createCriteria(TblMamgmParaTblAttr.class);
tx.commit();
DAO层
DAO层主要是做数据持久层的工作,负责与数据库进行联络的一些任务都封装在此,DAO层的设计首先是设计DAO的接口,然后在Spring的配置文件
中定义此接口的实现类,然后就可在模块中调用此接口来进行数据业务的处理,而不用关心此接口的具体实现类是哪个类,显得结构非常清晰,
DAO层的数据源配置,以及有关数据库连接的参数都在Spring的配置文件中进行配置。
Service层
Service层主要负责业务模块的逻辑应用设计。同样是首先设计接口,再设计其实现的类,接着再Spring的配置文件中配置其实现的关联。
这样我们就可以在应用中调用Service接口来进行业务处理。Service层的业务实现,具体要调用到已定义的DAO层的接口,封装Service层
的业务逻辑有利于通用的业务逻辑的独立性和重复利用性,程序显得非常简洁。
Controller层
Controller层负责具体的业务模块流程的控制,在此层里面要调用Serice层的接口来控制业务流程,控制的配置也同样是在Spring的配置文件
里面进行,针对具体的业务流程,会有不同的控制器,我们具体的设计过程中可以将流程进行抽象归纳,设计出可以重复利用的子单元流程模块,
这样不仅使程序结构变得清晰,也大大减少了代码量。
View层
此层与控制层结合比较紧密,需要二者结合起来协同工发。View层主要负责前台jsp页面的表示,
DAO层,Service层这两个层次都可以单独开发,互相的耦合度很低,完全可以独立进行,这样的一种模式在开发大项目的过程中尤其有优势,
Controller,View层因为耦合度比较高,因而要结合在一起开发,但是也可以看作一个整体独立于前两个层进行开发。这样,在层与层之前
我们只需要知道接口的定义,调用接口即可完成所需要的逻辑单元应用,一切显得非常清晰简单。
DAO设计的总体规划需要和设计的表,和实现类之间一一对应。
DAO层所定义的接口里的方法都大同小异,这是由我们在DAO层对数据库访问的操作来决定的,对数据库的操作,我们基本要用到的就是新增,
更新,删除,查询等方法。因而DAO层里面基本上都应该要涵盖这些方法对应的操作。除此之外,可以定义一些自定义的特殊的对数据库访问的方法。
Service逻辑层设计
Service层是建立在DAO层之上的,建立了DAO层后才可以建立Service层,而Service层又是在Controller层之下的,因而Service层应该既调用DAO层
的接口,又要提供接口给Controller层的类来进行调用,它刚好处于一个中间层的位置。每个模型都有一个Service接口,每个接口分别封装各自的
业务处理方法。
在DAO层定义的一些方法,在Service层并没有使用,那为什么还要在DAO层进行定义呢?这是由我们定义的需求逻辑所决定的。DAO层的操作
经过抽象后基本上都是通用的,因而我们在定义DAO层的时候可以将相关的方法定义完毕,这样的好处是在对Service进行扩展的时候不需要
再对DAO层进行修改,提高了程序的可扩展性。
前置PIT环境管理启动时现象:nohup和serverlog中没有报错,cpu占用率近于0,等待很长时间以后nohup中报错,获取不了数据源miMng。
原因:server/default/lib中upjas_dbpm.jar没有删除,而upjas_setEnv.sh里面设置了dbpm的ip地址和PIT环境不在一个网段,所以用了很长的时间
去连接,可能jar包里面还重试了多次。
onblur="if(value==''){value='your email address'}" 失去焦点的时候
onfocus="" 得到焦点的时候
$("#textDiv").show();//显示div
$("#imgDiv").hide();//隐藏div
$("#sendPhoneNum").css("display", "none"); //通过jquery的css方法,设置div隐藏
$("#top_notice").attr("style", "display:block;"); //给元素设置style属性
用CSS设置浮动层
margin-top:0px; position:absolute; display:none
velocity 字符串解析报错:
#set($bmpnumvalue=${flds.value}.substring($bmpnum,$bmpnumend))
要改成下面这种,原因未知
#set($bmpnumvalue=$flds.value.substring($bmpnum,$bmpnumend))
jquery如果判断元素是否隐藏(hide)?_百度知道
答
$("p").is(":hidden")
让input表单只读的几种方法
方法1: onfocus=this.blur()
<input type="text" name="input1" value="建站学" onfocus=this.blur()>
方法2: readonly
<input type="text" name="input1" value="建站学" readonly>
<input type="text" name="input1" value="建站学" readonly="true">
方法3: disabled
<input type="text" name="input1" value="建站学" disabled>
Hibernate配置文件中设置隔离级别,默认是4
#hibernate.connection.isolation 4
或
<property name=” hibernate.connection.isolation”>4</property>
1:读操作未提交(Read Uncommitted)
2:读操作已提交(Read Committed)
4:可重读(Repeatable Read)
8:可串行化(Serializable)
1、更新丢失(Lost Update):两个事务都企图去更新一行数据,导致事务抛出异常退出,两个事务的更新都白费了。
2、脏数据(Dirty Read):如果第二个应用程序使用了第一个应用程序修改过的数据,而这个数据处于未提交状态,这时就会发生脏读。
第一个应用程序随后可能会请求回滚被修改的数据,从而导致第二个事务使用的数据被损坏,即所谓的“变脏”。
3、不可重读(Unrepeatable Read):一个事务两次读同一行数据,可是这两次读到的数据不一样,就叫不可重读。如果一个事务在提交数据之前,
另一个事务可以修改和删除这些数据,就会发生不可重读。
4、幻读(Phantom Read):一个事务执行了两次查询,发现第二次查询结果比第一次查询多出了一行,这可能是因为另一个事务在这两次查询
之间插入了新行。
1、读操作未提交(Read Uncommitted):说明一个事务在提交前,其变化对于其他事务来说是可见的。这样脏读、不可重读和幻读都是允许的。
当一个事务已经写入一行数据但未提交,其他事务都不能再写入此行数据;但是,任何事务都可以读任何数据。这个隔离级别使用排写锁实现。
2、读操作已提交(Read Committed):读取未提交的数据是不允许的,它使用临时的共读锁和排写锁实现。这种隔离级别不允许脏读,
但不可重读和幻读是允许的。
3、可重读(Repeatable Read):说明事务保证能够再次读取相同的数据而不会失败。此隔离级别不允许脏读和不可重读,但幻读会出现。
4、可串行化(Serializable):提供最严格的事务隔离。这个隔离级别不允许事务并行执行,只允许串行执行。这样,脏读、不可重读
或幻读都不可发生。
java.io.IOException: Missing config file: 'WEB-INF/para/dwr_spring.xml'
org.directwebremoting.impl.DwrXmlConfigurator.setServletResourceName(DwrXmlConfigurator.java:78)
org.directwebremoting.impl.StartupUtil.configureFromInitParams(StartupUtil.java:645)
jboss里面WEB-INF/para/dwr_spring.xml说是找不到?
解决:权宜之计
1、删除配置未知
<!-- <init-param>
<param-name>config-1</param-name>
<param-value>WEB-INF/para/dwr_spring.xml</param-value>
</init-param>
-->
2、把dwr.xml配置文件移动位置,并改名。
把WEB-INF/para/dwr_spring.xml移动到web.xml平级目录,然后改名成dwr.xml
hibernate 默认jdbc事务,并整合spring后配置(在applicationContext.xml文件中):
<bean id="MgmDataSource"
class="org.springframework.jndi.JndiObjectFactoryBean">
<property name="jndiName" value="jdbcMapsMng"></property>
</bean>
<bean id="mgmSessionFactory"
class="org.springframework.orm.hibernate3.LocalSessionFactoryBean">
<property name="dataSource" ref="MgmDataSource"></property>
<property name="configLocations">
<value>classpath:hibernate.cfg.xml</value>
</property>
</bean>
<!-- 配置事务管理器 指定其作用的sessionFactory把事务交给Spring去处理 -->
<bean id="transactionManager" class="org.springframework.orm.hibernate3.HibernateTransactionManager">
<property name="sessionFactory">
<ref bean="mgmSessionFactory"/>
</property>
</bean>
<!-- bizcontrol 配置事务的传播特性 -->
<tx:advice id="bziControltxAdvice" transaction-manager="transactionManager">
<tx:attributes>
<tx:method name="save*" propagation="REQUIRED"/>
<tx:method name="delete*" propagation="REQUIRED"/>
<tx:method name="active*" propagation="REQUIRED"/>
<tx:method name="get*" read-only="true" propagation="NOT_SUPPORTED"/>
<tx:method name="*" read-only="true"/>
</tx:attributes>
</tx:advice>
<!-- 那些类的哪些方法参与事务 -->
<aop:config>
<aop:pointcut id="allServiceMethod" expression="execution(* com.cup.maps.parameter.bizcontrol.service.*.*(..))"/>
<aop:advisor pointcut-ref="allServiceMethod" advice-ref="bziControltxAdvice"/>
</aop:config>
hibernate 使用jboss的jta事务,并整合spring
1、applicationContext.xml文件中配置:
<bean id="MgmDataSource"
class="org.springframework.jndi.JndiObjectFactoryBean">
<property name="jndiName" value="jdbcMapsMng"></property>
</bean>
<bean id="mgmSessionFactory"
class="org.springframework.orm.hibernate3.LocalSessionFactoryBean">
<property name="dataSource" ref="MgmDataSource"></property>
<property name="configLocations">
<value>classpath:hibernate.cfg.xml</value>
</property>
</bean>
<!-- 配置Spring使用JTA事务 -->
<tx:jta-transaction-manager />
<!-- bizcontrol 配置事务的传播特性 -->
<tx:advice id="bziControltxAdvice" transaction-manager="transactionManager">
<tx:attributes>
<tx:method name="save*" propagation="REQUIRED"/>
<tx:method name="delete*" propagation="REQUIRED"/>
<tx:method name="active*" propagation="REQUIRED"/>
<tx:method name="get*" read-only="true" propagation="NOT_SUPPORTED"/>
<tx:method name="*" read-only="true"/>
</tx:attributes>
</tx:advice>
<!-- 那些类的哪些方法参与事务 -->
<aop:config>
<aop:pointcut id="allServiceMethod" expression="execution(* com.cup.maps.parameter.bizcontrol.service.*.*(..))"/>
<aop:advisor pointcut-ref="allServiceMethod" advice-ref="bziControltxAdvice"/>
</aop:config>
2、hibernate.cfg.xml中配置:
<property name="hibernate.current_session_context_class">jta</property>
<property name="hibernate.transaction.manager_lookup_class">org.hibernate.transaction.JBossTransactionManagerLookup</property>
<property name="hibernate.transaction.factory_class">org.hibernate.transaction.JTATransactionFactory</property>
3、com.cup.maps.parameter.bizcontrol.service包下的所有类的save、active、delete开头的方法自动具有事务属性。
form提交时
action="${req.contextPath}/vm/paramimport/$tblcd"
必须要写成这样
action="${req.contextPath}/vm/paramimport/${tblcd}"
dwr返回list<javabean>时报错:bean is null
解决:dwr.xml中要配置新加bean的东东,否则页面bean==null
<convert converter="bean" match="com.cup.maps.parameter.bizcontrol.model.DropDownItem">
<param name="include" value="key,value" />
</convert>
jquery获得某个name是INQ_加变量eventDef表示的值的select元素:
解决:jQuery("select[name=INQ_"+eventDef+"]").empty();
弹出框
var sw = screen.width;
var sh = screen.height;
var w = 500;
var h = 600;
var l = (sw-w)/2;
var t = 200;
var parm=",toolbar=no,location=no,directories=no,status=no,menubar=no,scrollbars=yes,resizable=no,maxsige=yes";
var scoll="width="+w+",height="+h+",left="+l+",top="+t;
var urls = "${req.contextPath}/vm/load/biztree?bpmparamaction=hySearch";
window.open(urls,"_blank",scoll+parm);
注意:window.open()浏览器不支持隐藏地址栏
window.open()使用POST方式提交?
解决:注意form的target="newWin"
function submitForm(){
window.open('','newWin','width=400,height=500,scrollbars=yes');
form对象.submit();
}
<FORM name=form action="YourActionFile.html" method="post" target="newWin">
...
</Form>
alert(parseInt("11111010", 2));
alert(parseInt("11111010", 2).toString(16));
overflow从字面意义上来讲就是溢出的意思,换句话说,你有个层,但是里面的内容,图片或者文字要比层大,
overflow就是针对这种情况进行处理的。
包含4个属性值,visible,hidden,auto,scroll
visible就是超出的内容仍然正常被显示出来。
hidden就是超出的内容被隐藏。
auto是默认值,根据内容剪切或者加滚动条。
scroll就是总加滚动条
bizcontrol生效页面,IE8无法生效?
解决:F12,浏览器模式选型IE8兼容性视图,文本模式选择IE8标准。原因是IE8兼容性模式下才支持JSON.stringify。
bizcontrol新增修改页面,IE8无法保存?
解决:发现IE8没有tmpvalue.trim()函数竟然,使用jQuery.trim(tmpvalue)替代。
firefox里生效页面,选择一条记录,点参数查看,然后点返回,报“文档已过期”错误,IE里面没有此错误?
解决:无法解决,不过在报“文档已过期”错误的那个页面上,点“重试”再次进入参数查看页面,点返回,回到参数查询页面。
hibernate关联记录,配置过滤条件和排序字段
<set name="drdlItemList" table="TBL_MAMGM_DRDL_ITEM_DEF" lazy="false" where="OPER_IN NOT IN ('D','d')" order-by="DRDL_ITEM_KEY">
<key column="DRDL_ID" />
<one-to-many
class="com.cup.maps.parameter.bizcontrol.model.hibernate.TblMamgmDrdlItemDef" />
</set>
db2查看锁表信息
>db2pd -db mamgmdb -locks show detail
表解锁
db2 force application all
SELECT * FROM SYSCAT.TABLES WHERE TBSPACEID = 2 AND TABLEID = 512;
SELECT * FROM SYSCAT.COLUMNS WHERE TABNAME= '*******' AND COLNO = 8
Javascript 判断是否存在函数的方法?
function aa()
{
this.length=1;
this.size =2;
}
if (typeof(aa)=="function")
alert(1);
else
alert(2);
使用SqlMapClientTemplate查询?
当执行没有参数的查询时:
List result = getSqlMapClientTemplate().queryForList("TestSpace.qryTest");
"TestSpace"为iBatis SqlMap文件的命名空间;"qryTest"为iBatis SqlMap的查询方法id
当按照主键获取某条记录信息时:
Long id = new Long("2");
Object resultObj = getSqlMapClientTemplate().queryForObject("TestSpace.getTest", id);
LRU缓存介绍与实现 (Java)?
public class LRUCache<K,V> extends LinkedHashMap<K, V>{
private LinkedHashMap<K,V> cache =null ;
private int cacheSize = 0;
public LRUCache(int cacheSize){
this.cacheSize = cacheSize;
int hashTableCapacity = (int) Math.ceil (cacheSize / 0.75f) + 1;
cache = new LinkedHashMap<K, V>(hashTableCapacity, 0.75f,true)
{
// (an anonymous inner class)
private static final long serialVersionUID = 1;
@Override
protected boolean removeEldestEntry (Map.Entry<K, V> eldest)
{
System.out.println("size="+size());
return size () > LRUCache.this.cacheSize;
}
};
}
public V put(K key,V value){
return cache.put(key, value);
}
public V get(Object key){
return cache.get(key);
}
}
LRUCache<String, String> lruCache = new LRUCache<String, String>(5);
LinkedHashMap缺省是使用插入顺序的,如何构造一个访问顺序的LinkedHashMap呢?
public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) accessOrder = true 即可。
LinkedHashMap提供按照访问的次序来排序的功能?
LinkedHashMap改写HashMap的get(key)方法(HashMap不需要排序)和HashMap.Entry的recordAccess(HashMap)方法
public Object get(Object key) {
Entry e = (Entry)getEntry(key);
if (e == null)
return null;
e.recordAccess(this);
return e.value;
}
void recordAccess(HashMap m) {
LinkedHashMap lm = (LinkedHashMap)m;
if (lm.accessOrder) {
lm.modCount++;
remove();
addBefore(lm.header);
}
}
注 意addBefore(lm.header)是将该entry放在header线性表的最后。(参考LinkedHashMap.Entry extends HashMap.Entry
比起HashMap.Entry多了before, after两个域,是双向的)
关于在RCP程序开发过程中遇到的:No Application ID has been found错误提示?
原因:依赖项添加不完整,漏掉了某些插件。
解决:运行配置中,在Main选项卡中选择运行方式为run an Application,然后在plugins选项卡中选择chose plugins and fregments from the list,
然后在列表中Workspace Plugins里面选择自己的插件,在target platform中先设为全不选,然后再点击右边的add required Plugins。
这样就可以把必须的插件都自动的添加到项目中。
Jar mismatch! Fix your dependenciesmPOSAppUnknownAndroid Dependency Problem?
解决:在开发Android项目的时候,有时需要引用多个项目作为library。在引用项目的时候,有时会出现“Jar mismatch! Fix your dependencies”错误。
这是因为两个项目的jar包(android-support-v4.jar)不一致。
解决方法是把2个jar都删除,然后各自加上最新的jar包。
Conversion to Dalvik format failed with error 1?
解决:做为lib工程,java build path标签的Libraries中不应该直接从Add External JARs引入android.jar,而是应该从Add Library
进入,再从Android Classpath Container进,点next,点Finish进入。




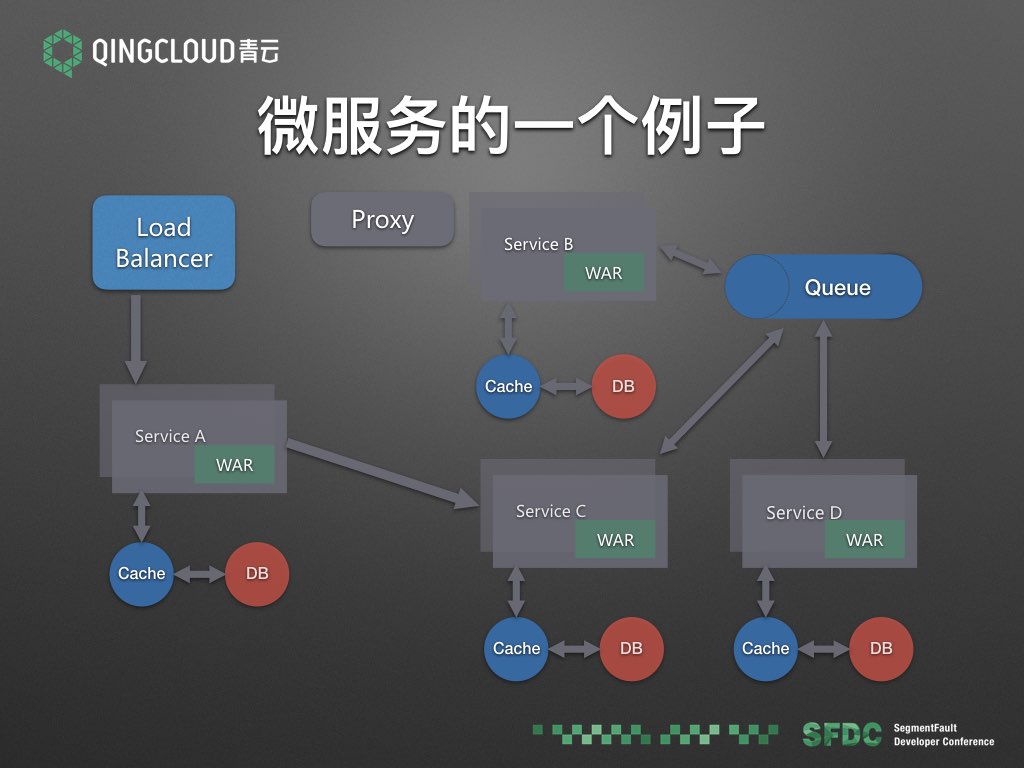











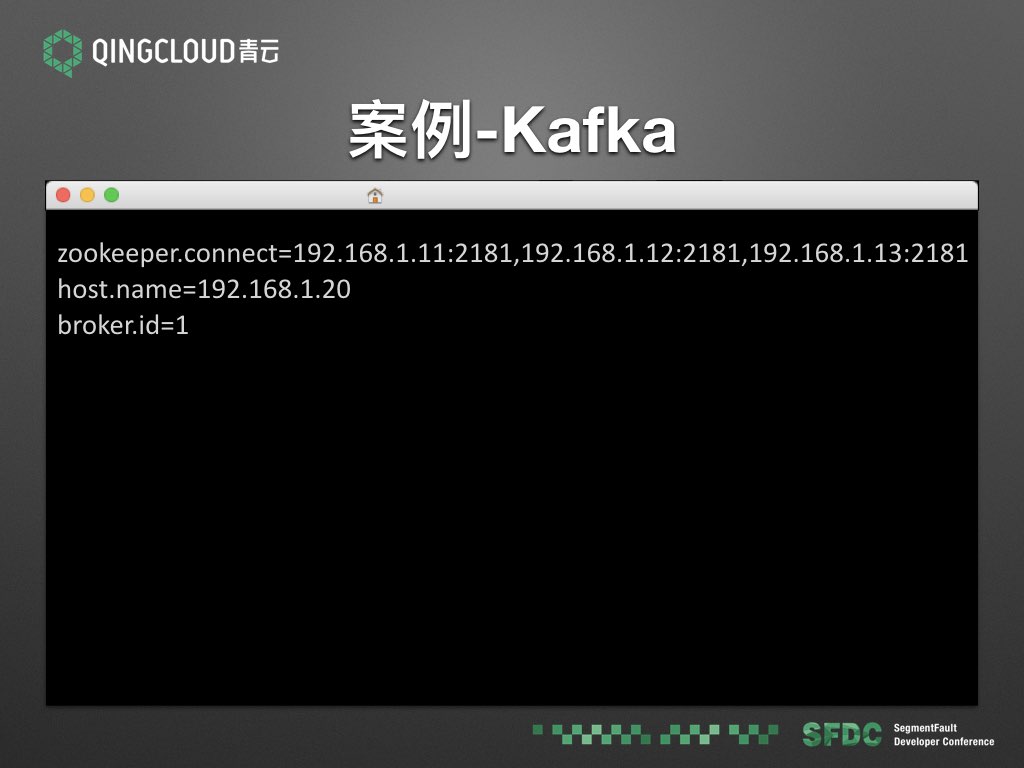



















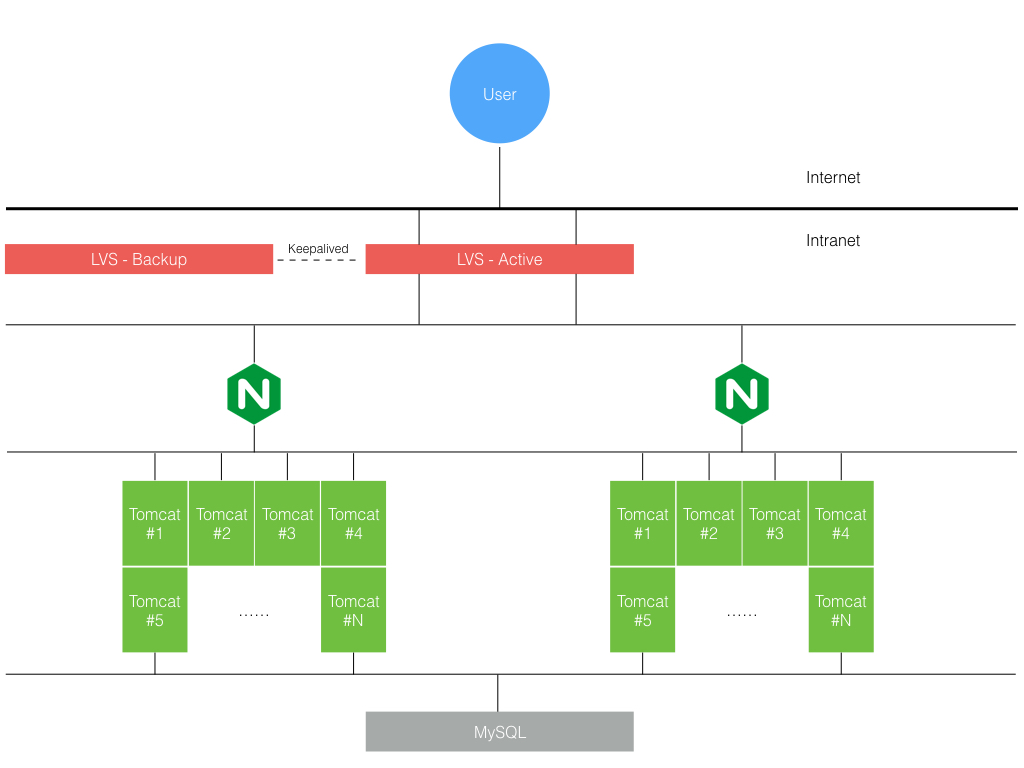
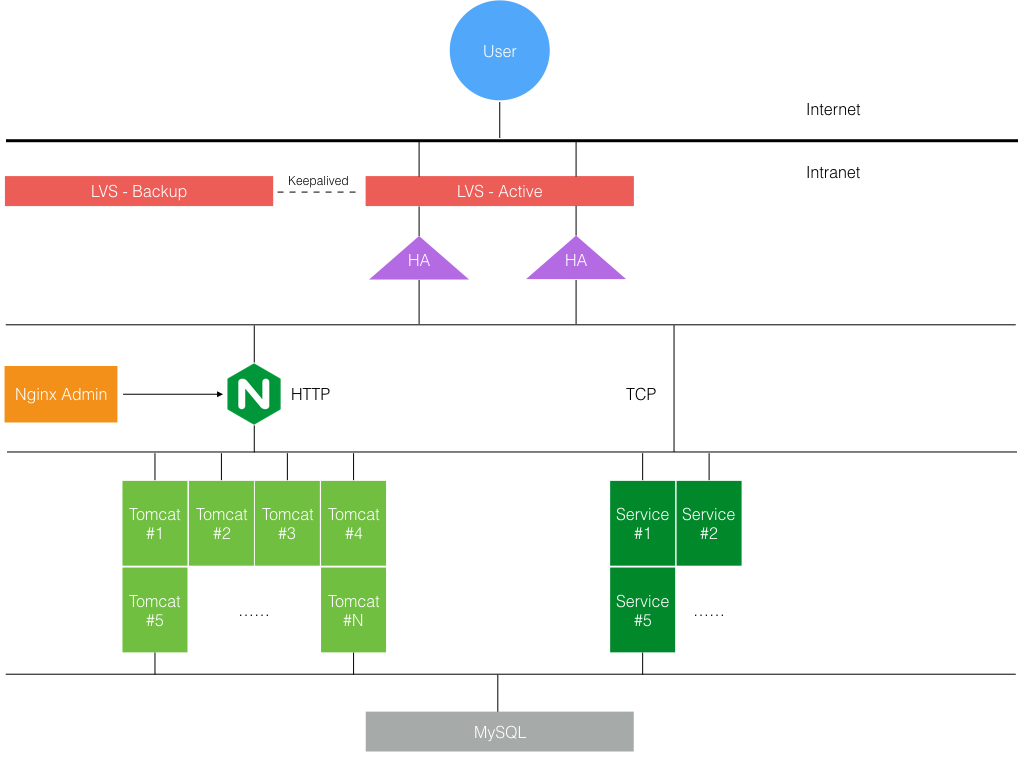

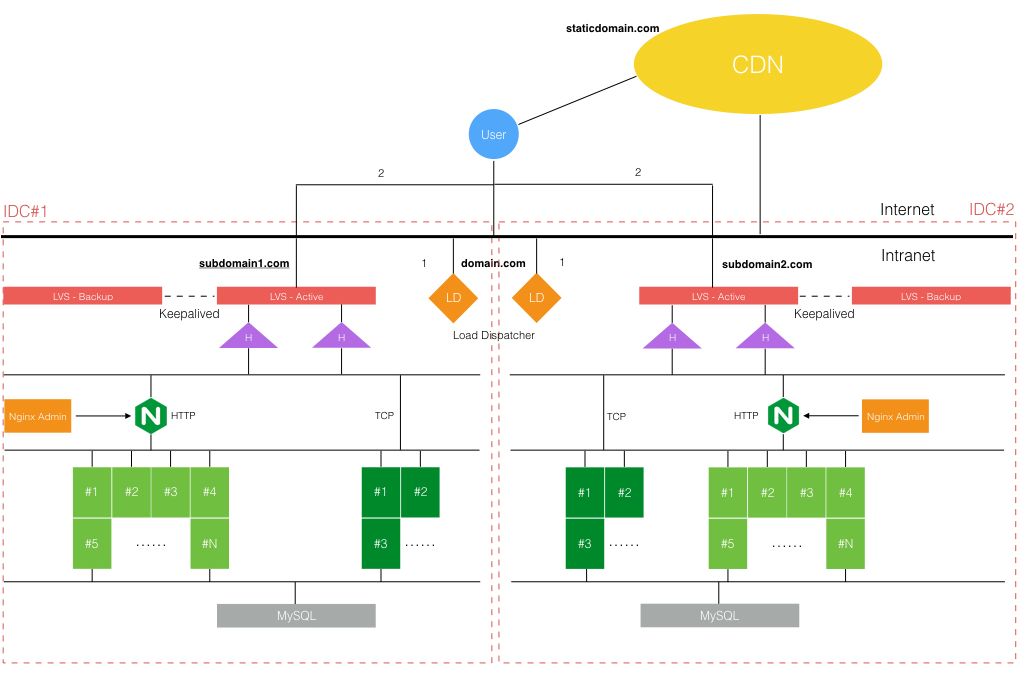
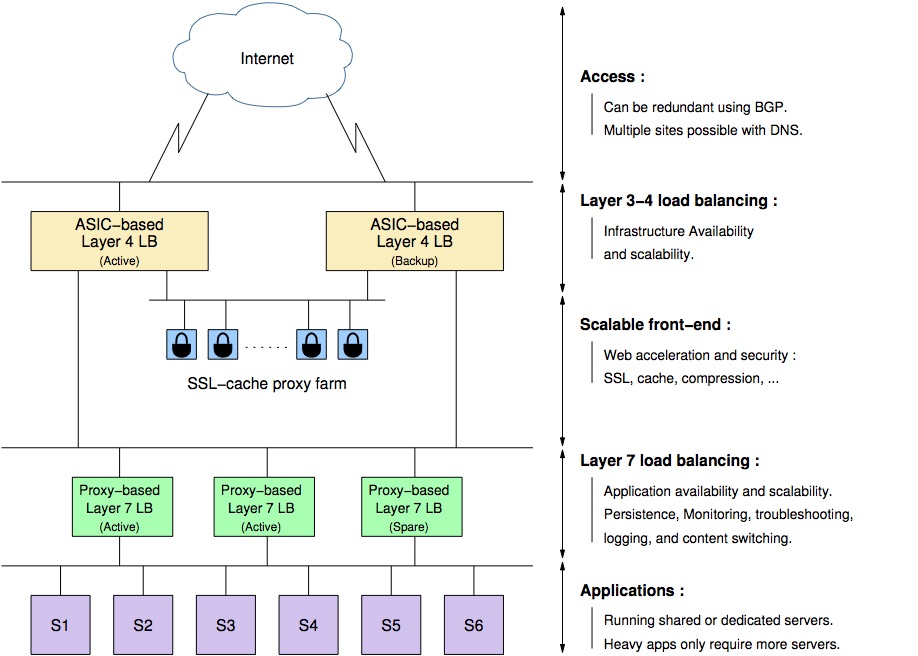
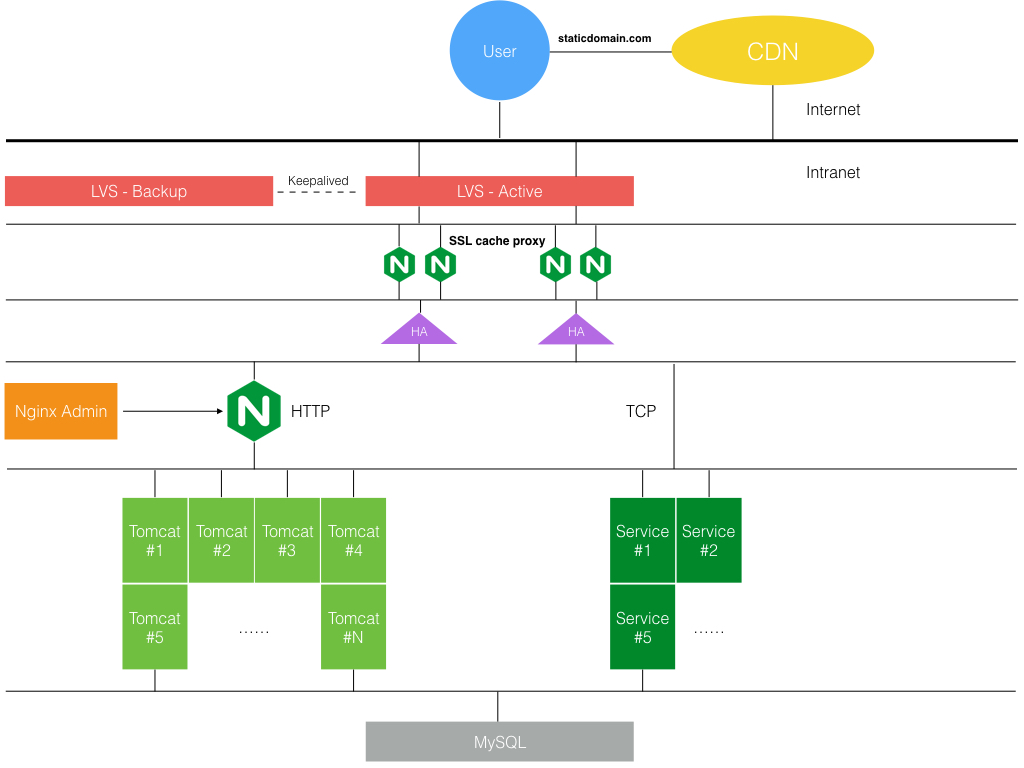































































 ,我们只在官网的页面上找到了51张照片,而不是正文所述的52张。
,我们只在官网的页面上找到了51张照片,而不是正文所述的52张。








 少女心的人,也不太可能没有被某一种粉色安利到。
少女心的人,也不太可能没有被某一种粉色安利到。 “公主风”。 如何把时髦的高级粉巧妙地融入自己的家?让我们跟着那些厉害建筑事务所的作品来学一学。
“公主风”。 如何把时髦的高级粉巧妙地融入自己的家?让我们跟着那些厉害建筑事务所的作品来学一学。