↧
Android性能优化-线程性能优化
↧
山东人最爱用倒装句?有无搞错啊你地,明明最厉害的是广东人
据说最近有个热门话题
是“山东人说话爱用倒装句”
南都君(微信公众号:nddaily)看到后觉得吧
这倒装句用得确实溜你们山东人
但说到倒装句
得让我们广东人走先!
看看我们的日常对话
这样说话太爽了简直
有位广东妹纸
这样记录她的日常
笑得我啊
厉害了我的广东孩纸
据说这样说话让北方人很头痛
有知乎网友说
在南方小城工作
经常听到同事说
“我走先哈”
第一次听心里默默想:
什么鬼!
后来才知道
原来是 “我先走了”的意思
XX先
这是粤语句式最经典的
只不过很多广东人
把粤语发音转换成普通话来说
然而句式并没调转回来
这就成了我们平时调侃的
广普
比如:
我吃先(我食先)
我睡先(我训先)
还有
给张纸我(俾张纸我)
去哪里啊他(去边啊佢)
闭嘴啦你(收皮啦你)
谢谢啊你(唔该晒你)
这几句倒装一定要学会
每天都会用到:
唔该晒你(谢谢你啊)
借借啊唔该(麻烦让一让)
自己收下台唔该(麻烦自己收一下桌子)
作为一个自称“在广东吃了多年虾饺和凤爪”的非广东人,知乎用户ALEX YA对广东人特殊的语法做了如下总结:
类似的广普还有
口水多过浪花(口水比浪花还多,形容一个人话太多)
来多一笼虾饺(多来一笼虾饺)
给多张票你们(多给你们一张票)
广东孩纸表示这样说话好舒服
!!!
其实,什么是倒装句?
倒装句是为了强调、突出等语的目的而颠倒原有语序的句式。颠倒了的成分可以恢复原位而句意基本不变,句法成分不变。
我们小时候学的文言文中
就有大量的倒装句
比如:
不患人之不己知,患不知人也。(《论语·学而》)
(正确语序应是不患人之不知己,患不知人也)
吾谁欺?欺天乎?(《论语·子罕》)
(正确语序应是吾欺谁?欺天乎?)
而粤语被指较多地保留了文言文的句式
如果说山东人爱说倒装句
那是可以普及到全国的现象
但广东人爱用倒装句
就是粤语文化的现象了!!
好啦!
南都君去吃饭先
有什么想说留言给我
南都君综合
实习生 李萍萍
* 公众号如需转载南都君原创内容,请后台联系授权;未经授权,不得转载。
冷空气已发货!广东人,拜托不要再穿短袖了,表达下对冬天的尊重……
隔着汽车玻璃就能用POS机将粤通卡刷光?!真相和防范措施都在这!
25岁潮汕女子上东莞见网友后失联,已确认遇害!监控中男子已被警方控制
点亮大拇指啊你们

↧
↧
考虑把大型项目拆解成微服务吗?
【编者的话】本文理性的讨论了拆解大型项目到微服务的过程,讨论了拆解过程中会遇到的问题和编程语言的选择,并给出了作者自己的建议。
微服务是处理臃肿、凌乱系统的一剂良药。然而,拆解一个大型项目为一系列的微服务所付出的代价是值得的吗?现在存在一些优点和缺点,那么微服务的哪些特点吸引了众多公司和开发人员呢?
最常见的应用场景是将一个大型系统切换到基于微服务的基础设施。我倾向将这个过程称为“分解”应用程序,因为我们把紧耦合的代码分解成多个小的服务。这包括了从仅添加一两个微服务到完全重构主要应用程序到微服务架构。
简而言之,我相信分解一个大型系统为微服务组合是值得的。然而,这是一个长期投资,可能需要一段时间才能得到回报。每个项目或公司在这一过程中都会有不同的经验和教训。这里有一些共同的主题,它们也是我最近在分解大型项目到微服务过程中遇到的。
放慢节奏
在开发软件的过程中,我们通常切分大型的任务为小的部分,便于一步一步实施。采用微服务时,与这个过程非常相似。我们需要分解大的项目为一系列的微服务。很多方面,我们像堆砌木桩一样处理它们:我们需要随时间的推移而添加组成部分,将项目分解成丰富且有用的多个组成部分。
当你首次介绍微服务思想给开发团队时,可能他们会很容易接受。微服务是开发社区中的发展趋势,于是人们都渴望试一下。更夸张的趋势甚至会变成“能够改变app中一个功能而不影响其他200项功能,这不是很棒么?”
然而,实现松耦合和独立应用的过程远不止两周。可能需要花费数个月甚至数年来解耦合你的应用程序到不同的功能服务。
将项目分解作为一项长期的任务是非常重要的。客户和投资者并不在意你是否将已有的功能拆分为微服务。他们只是关心是否你在如期地产出。当已经感受到微服务架构的威力,你和你的团队需要推动其发展。同样,这也是一种技术债务。
这也就是为什么需要花费时间去解体大型项目。把拆解项目作为一个长期项目的时候,可能需要花费多年时间才能得到相应的收益。每一部分代码的拆分都应该作为一个重要决定。在你拆解速度过快时,可能会产生严重的问题。
自由通常不是免费的
微服务架构可以采用不同的开发语言和框架实现。微服务限制一组有限的编程语言来共享应用程序,允许开发人员使用,并且只能用这些。
对于开发者来说,这可以引出很多非常激动人心的决定。但是,你可能希望在选择一门新编程语言或者框架来实现微服务时有所收敛。
学习新的编程语言或者框架对于个人经验来讲是非常有帮助的。同时开发者也很有兴趣去学习。尽管我可能满足于采用某些语言和框架来创作自己的私有项目,但是,在生产环境这个场景下,可能是完全不同的情况。
你和你的同事可能觉得用Rust语言写个服务是个好主意。从纸面上来讲,这个主意看上去很好。你可以用一个非常棒的语言去实现,同时让你的业务达到一个更好的境地。
值得注意的是,在你的团队和同事在实现它的时候,没有什么是一成不变的。团队生产是一件取决于你是否要去选择的事情。目前,你的公司可能具备资源和技能去采用Rust来创造一个高效的微服务。但是,你的团队是否会在Rust服务上进行持续投入?这依赖于在微服务上的投入,你可能发现自己已经完全归属在微服务上了。
当你选择一门编程语言,你其实是在抉择未来是否继续投入。抛开你当前团队的规模和状态的情况下,最差的情况是你可能朝着一个令人沮丧的方向并且浪费了大量的开发资源。
DevOps的负担
当你决定去拆分一个项目时,我强烈推荐增加在DevOps上的投入。微服务的显著特点是他们在持续部署上的稳定。这里面还有很多其他的说法。当服务准备完毕时,微服务使你可以快速的部署。这对于部署过程是非常好的,因为你不需要重新部署一整套应用。
这只是理论上的情况。
事实上,创建和维护的服务越多,部署环节自然会越多。你需要能够在有限时间内有效的部署多个服务。如果只有有限个开发人员培训过部署方式,事情可能会失控。
这就是为什么要教会开发者具备从开发到部署代码的能力。理想情况是,他们可以便捷的部署代码并监控。他们还应该具备突发情况下部署和掌控服务的能力。此外,开发者应该熟悉微服务及对常规生产环境故障的感知力。我经历过许多的部署错误,如果开发人员熟悉这些故障,解决起来会更快。这可能是几秒钟宕机到几分钟宕机的差别。
此外,这个事情的复杂度可能会因为稳定性和语言多样性而加重。再次重申一下,并不是所有的新语言和框架在部署上像其在开发上那么方便。明智的选择是在承担较小风险的同时,采用较先进的语言和框架,毕竟它们可能不是为生产环境而准备的。
结束语
分解一整个项目会带来很多可变化的部分。解决这件事情的关键是让团队提高效率,并计划好自己的时间。他们需要时间来实现新特性和修复,同时采取有效措施拆解应用程序。
采用微服务,你可以自由选择编程语言或者框架。这种自由度是非常令人兴奋的,但是不要陷入到追求最前沿的陷阱里,毕竟生产环境需要的是稳定。
同样,在分解项目过程中,DevOps带来了另一种复杂性。收获的优势没有在每次的重新部署中发挥出来。然而,这需要更多的支持和对部署过程中新增服务的所有权。
我非常确信分解一个大型项目到微服务的过程是值得的。然而,这是一个长期的投资,可能需要一段时间才能收到回报。
原文链接: So You’re Thinking of Decomposing Your Monolith into Microservices(翻译:陈杰)
===================================================
译者介绍
陈杰,BOSS直聘app的数据工程师,工作重心为基于用户行为的数据推荐,平时也乐于去实现一些突发的想法。在疲于配置系统环境时发现了Docker,跟大家一起学习、使用和研究Docker。
↧
谁应该为使用 OpenPilot 开源自动驾驶软件负责?
知名黑客 George Hotz 通过他的公司 Comma.ai 开源了自动驾驶软件和硬件。如果你的汽车使用了开源的自动驾驶软件,由于软件bug 汽车撞上建筑物,或其它汽车甚至行人, 谁应该对车祸负责?许多法律专家和 Hotz 本人都相信,如果你使用了Comma.ai的代码,出了问题负责的不是Comma.ai而是你。但消费者保护组织 Consumer Watchdog的顾问 John Simpson认为这不公平,他认为Hotz需要承担部分责任,随着修改代码的开发者增多,责任将会日益模糊。他认为是Hotz公开了代码,Hotz需要和用户一起承担责任。Hotz 通过源代码使用的 MIT许可证为自己加入免责声明,将法律责任转移到下载者。律所O’Melveny & Myers LLP 合伙人Heather Meeker指出,如果 Hotz 出售了包含开源软件的产品,或者向汽车制造商做出能正常工作的保证,那么Hotz将需要为损失承担责任;如果汽车制造商使用了 Hotz的软件,那么责任可能就转移到了它身上了。
稿源: Solidot
↧
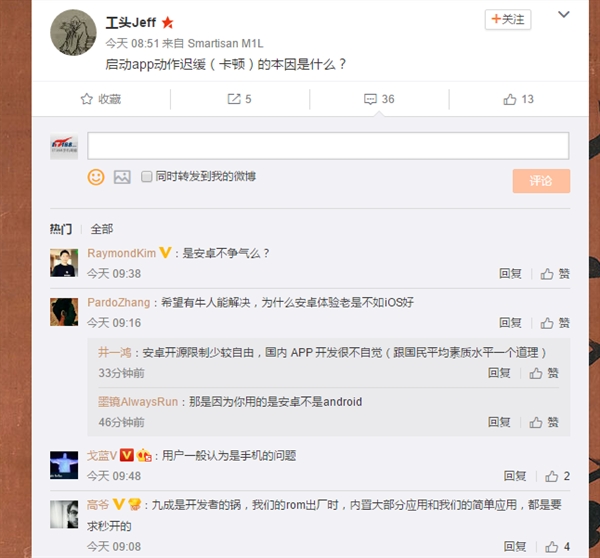
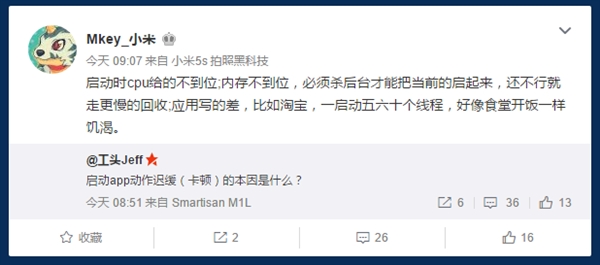
小米工程师回应Android应用为啥启动慢|淘宝躺枪
关于安卓系统体验差、不流畅的言论一直存在,尤其是应用启动速度相比 iOS 有着不小的差距。
对此,前锤子科技 CTO 钱晨@工头 Jeff 今天在微博上发问,启动 app 动作迟缓(卡顿)的本因是什么?
这一问题引发了业内不少人士的讨论,其中小米 MIUI 开发的@Mkey_小米表示,造成卡顿的原因有很多种,具体来讲, 包括应用启动时 CPU 给的不到位;内存不到位,甚至必须杀后台才能把当前的启动起来,还不行就走更慢的回收过程;还有一部分原因是应用写的差,比如淘宝,一启动五六十个线程,好像食堂开饭一样饥渴。
而魅族的开发者@高爷也紧跟着回复,表示这种现象九成是开发者的锅,魅族的 ROM 在出厂时内置大部分应用都是要求秒开的。三星员工@戈蓝V也表示,用户一般认为是手机的问题,同样暗指大部分是开发者的责任。
那么问题来了,为啥在 iOS 上那么规矩,跑到 Android 上就成流氓了呢?
↧
↧
HTTP-RPC:轻量级跨平台REST框架
核心要点
- HTTP-RPC是一个开发RESTful应用的轻量级开源框架,同时符合RPC隐喻的做法;
- 提供了服务端和客户端的API;
- 支持各种操作系统和设备;
- 支持多种语言,包括Java、Objective-C/Swift和JavaScript。
HTTP-RPC是一个开源框架,致力于简化基于REST的应用开发。它允许开发人员创建和访问基于HTTP的Web服务,这个过程会使用便利的、类似于RPC隐喻的做法,同时还能保留基础的REST理念,比如无状态和统一资源访问。
目前,这个项目支持使用Java来实现REST服务,使用Java、Objective-C/Swift或JavaScript来消费服务。相对于基于Java的更大的REST框架,服务端组件提供了一种轻量级的替代方案,对于微服务和物联网(Internet of Things,IOT)应用来说,这是一个理想的选择。统一的跨平台客户端API能够使与服务的交互变得非常容易,不用关心目标设备或操作系统是什么。
概览
HTTP-RPC服务要通过HTTP动作来进行访问,比如对目标资源的GET或POST请求。目标是通过路径来进行指定的,路径代表了资源的名称,通常会使用一个名词来组成URL,比如/calendar或/contacts。
参数会通过查询字符串或类似于HTML表单那样的请求体的方式来提供。结果通常会返回JSON格式,当然不返回任何值的操作也是支持的。
例如,如下的请求将会得到两个数字的和,这两个数字分别是通过a和b这两个查询参数指定的:
GET /math/sum?a=2&b=4
除此之外,参数值也可以通过一个列表来指定,而不是两个固定的变量:
GET /math/sum?values=1&values=2&values=3
在这两种情况下,服务都会在响应中返回6这个值。
POST、PUT和DELETE操作的行为与之类似。
实现服务
HTTP-RPC的服务端库是以一个JAR文件的形式来进行分发的,这个库只有32KB,并没有外部的依赖。它包含了如下的包/类:
org.httprpc
WebService——HTTP-RPC所提供的RPC服务的抽象基础类,为其添加注解就能指定“远程方法调用”或服务方法。
org.httprpc.beans
BeanAdapter——适配器类,将Java Bean实例的内容呈现为一个Map,适用于序列化为JSON的场景。
org.httprpc.sql
ResultSetAdapter——适配器类,它代表了JDBC结果集的内容,将其作为一个可迭代的列表,适用于将流(streaming)转换为JSON。
Parameters——用于简化预处理语句(prepared statement)执行的类。
org.httprpc.util
IteratorAdapter——适配器类,它以一个可迭代列表的形式展现迭代器中的内容,适用于将流(streaming)转换为JSON。
上述的每个类都会在后文中进行更详细的讨论。
WebService类
WebService类是一个用于实现HTTP-RPC Web服务的基础抽象类。我们定义服务操作的方式就是为某个具体的服务实现添加公开方法。
@RPC注解用来标记某个方法可以进行远程访问。这个注解会为方法关联一个HTTP动作和资源路径。当服务发布之后,所有带有注解的公开方法将会自动允许远程执行。
例如,如下的类可以用于实现我们前文所述的简单加法操作:
public class MathService extends WebService {
@RPC(method="GET", path="sum")
public double getSum(double a, double b) {
return a + b;
}
@RPC(method="GET", path="sum")
public double getSum(List<Double> values) {
double total = 0;
for (double value : values) {
total += value;
}
return total;
}
}注意,上面的两个方法都会映射到“/math/sum”路径上。具体执行哪个方法,要根据所提供参数值的名称来确定。例如,如下的请求将会调用第一个方法:
GET /math/sum?a=2&b=4
如下的请求将会调用第二个方法:
GET /math/sum?values=1&values=2&values=3
方法参数与返回类型
方法参数可以是任意的数字原始类型或包装类、boolean、java.lang.Boolean或java.lang.String。参数也可以是java.net.URL或java.util.List实例。URL参数代表了二进制内容,比如JPEG或PNG图片。List参数则代表了多个值的参数,List中的元素可以是任意支持的简单类型,比如 List<Integer>或List<URL>。
方法可以返回任意的数字原始类型或包装类、boolean、java.lang.Boolean或java.lang.CharSequence,也可以返回java.util.List或java.util.Map实例。
结果会映射为对应的JSON类型,如下所示:
- java.lang.Number或数字原始类型:number
- java.lang.Boolean或boolean原始类型:true/false
- java.lang.CharSequence:string
- java.util.List:array
- java.util.Map:object
需要注意的是,List和Map类型并不需要支持随机存取(random access),只需要支持迭代就可以。另外,实现了java.lang.AutoCloseable的List和Map类型在它们的值写入到输出流之后,将会自动关闭。这样的话,服务的实现就能够以流的方式来响应数据,而不是在写入之前预先将其缓冲在内存中。
例如,org.httprpc.sql.ResultSetAdapter类包装了一个java.sql.ResultSet实例,将它的内容暴露为可向前移动( forward-scrolling)、自动关闭的map值的列表。关闭这个列表将会自动关闭底层的结果集,从而确保数据库资源不会泄露。
ResultSetAdapter稍后还会详细讨论。
请求元数据
WebService提供了如下的方法,允许它的扩展类获取当前请求的附加信息:
getLocale()——返回当前请求相关的地域信息;
getUserName()——返回当前请求相关的用户名,如果请求没有认证过的话,会返回null;
getUserRoles()——返回一个集合,代表了用户所属的角色,如果用户没有认证过的话,会返回null。
这些方法所返回的值都是由受保护的setter方法注入的,对于每个服务请求,这些setter方法只会调用一次。这些setter方法的本意是不希望由应用程序的代码调用的,但是它们有助于对服务实现进行单元测试。
BeanAdapter类
BeanAdapter类允许服务方法返回Java Bean对象,并对其内容进行转换。这个类实现了Map接口,并将Bean中的属性暴露为Map中的条目,允许自定义的数据类型序列化为JSON。
例如,如下的Bean类可能会用来代表一组值的基本统计数据:
public class Statistics {
private int count = 0;
private double sum = 0;
private double average = 0;
public int getCount() {
return count;
}
public void setCount(int count) {
this.count = count;
}
public double getSum() {
return sum;
}
public void setSum(double sum) {
this.sum = sum;
}
public double getAverage() {
return average;
}
public void setAverage(double average) {
this.average = average;
}
}使用这个类的getStatistics()方法,可能会如下所示:
@RPC(method="GET", path="statistics")
public Map<String, ?> getStatistics(List<Double> values) {
Statistics statistics = new Statistics();
int n = values.size();
statistics.setCount(n);
for (int i = 0; i < n; i++) {
statistics.setSum(statistics.getSum() + values.get(i));
}
statistics.setAverage(statistics.getSum() / n);
return new BeanAdapter(statistics);
}尽管值实际上存储在强类型的Statistics对象中,但是adapter能让数据看起来像map一样,这样的话,就能以JSON对象的形式将数据返回给调用者。
需要注意的是,如果某个属性返回的是嵌套的Bean类型,那么该属性的值将会自动包装为一个BeanAdapter实例。除此之外,如果属性返回的是List或Map类型,那么这个值将会包装到对应类型的adapter之中,自动化地包装其子元素。这样的话,就允许服务方法返回递归的结构,比如树形结构的数据。
BeanAdapter能够非常便利地将JPA查询的结果转换为JSON。该 地址的样例展现了如何组合使用BeanAdapter与Hibernate。
ResultSetAdapter和Parameters类
借助ResultSetAdapter类,我们能够让服务方法高效地返回SQL查询的结果。这个类实现了List接口,让JDBC结果集中的每一行都以Map实例的形式进行展现,这样的话,数据非常适于序列化为JSON格式。它还实现了AutoCloseable接口,能够保证底层的结果集可以正常关闭,避免数据库资源的泄露。
ResultSetAdapter只能向前移动,它的内容无法通过get()和size()方法来获取。这样的话,结果集内容可以直接返回给调用者,不需要任何的中间缓冲。调用者只需简单地执行JDBC查询,将得到的结果集传递给ResultSetAdapter的构造器,并返回该adapter实例即可:
@RPC(method="GET", path="data")
public ResultSetAdapter getData() throws SQLException {
Statement statement = connection.createStatement();
ResultSet resultSet = statement.executeQuery("select * from some_table");
return new ResultSetAdapter(resultSet);
}Parameters类提供了一种执行预处理语句的方式,这个过程中会使用命名的参数值(named parameter value)而不是使用参数的索引。与在JPQL中类似,参数名称会通过“:”字符来指定,样例如下:
SELECT * FROM some_table WHERE column_a = :a OR column_b = :b OR column_c = COALESCE(:c, 4.0)
借助parse()方法,我们可以根据SQL语句来创建Parameters实例。这个方法会接受一个java.io.Reader类型的参数,其中包含了SQL的文本,样例如下:
Parameters parameters = Parameters.parse(new StringReader(sql));
通过Parameters类的getSQL()方法,能够返回根据标准JDBC语法所解析的SQL:
SELECT * FROM some_table WHERE column_a = ? OR column_b = ? OR column_c = COALESCE(?, 4.0)
这个值用来创建实际的预处理语句:
PreparedStatement statement = DriverManager.getConnection(url).prepareStatement(parameters.getSQL());
参数值会通过apply()方法应用到SQL语句之中。这个方法的第一个参数就是预处理语句,第二个参数是一个map,包含了语句中的变量:
HashMap arguments = new HashMap();
arguments.put("a", "hello");
arguments.put("b", 3);
parameters.apply(statement, arguments);显式的创建和注入参数Map看上去会很繁琐,因此WebService类提供了如下的静态便利方法来简化Map的创建过程:
public static <K> Map<K, ?> mapOf(Map.Entry<K, ?>... entries) { ... }
public static <K> Map.Entry<K, ?> entry(K key, Object value) { ... }通过使用这些便利方法,填充参数值的代码可以简化为:
parameters.apply(statement, mapOf(entry("a", "hello"), entry("b", 3)));在参数填充完成之后,语句就可以执行了:
return new ResultSetAdapter(statement.executeQuery());
该地址中的样例展现了关于如何通过ResultSetAdapter和Parameters类访问MySQL数据库。
IteratorAdapter类
借助IteratorAdapter类,我们能够让服务方法高效地返回任意游标所对应的内容。这个类实现了List接口,能够将迭代器生成的每个元素序列化为JSON,包括嵌套的List和Map结构。与ResultSetAdapter类似,IteratorAdapter实现了AutoCloseable接口。如果底层的迭代器类型也实现了AutoCloseable接口的话,IteratorAdapter会确保底层的游标会关闭,这样的话,资源不会产生泄露。
与ResultSetAdapter相同,IteratorAdapter只能向前移动,所以它的内容无法通过get()和size()方法进行访问。这样就允许将游标的内容直接返回给调用者,无需任何的中间缓冲。
IteratorAdapter通常会用来序列化NoSQL数据库所产生的结果数据,比如MongoDB所产生的数据。该 地址的样例展现了组合使用IteratorAdapter和Mongo的例子。
消费服务
HTTP-RPC客户端库提供了一致的接口,能够实现跨多平台的服务操作调用。例如,如下的代码片段展现了Java客户端的WebServiceProxy类,它可以用来访问之前所讨论的数学计算服务方法。在代码中,我们首先创建了一个WebServiceProxy实例,并通过一个线程池对其进行配置,这个池中包含了10个用来执行请求的线程。然后,它会调用服务的getSum(double, double)方法,并为参数“a”传递2,为参数“b”传递4。最后,它执行了getSum(List<Double>)方法,将1,2,3作为参数传递了进来。与前面章节讨论的WebService类相似,WebServiceProxy提供了静态的工具方法,帮助我们简化参数映射的创建过程:
//创建服务
URL serverURL = new URL("https://localhost:8443");
ExecutorService executorService = Executors.newFixedThreadPool(10);
WebServiceProxy serviceProxy = new WebServiceProxy(serverURL, executorService);
// 得到“a”和“b”的和
serviceProxy.invoke("GET", "/math/sum", mapOf(entry("a", 2), entry("b", 4)), new ResultHandler<Number>() {
@Override public void execute(Number result, Exception exception) {
//结果是6
}
});
// 得到所有值的和
serviceProxy.invoke("GET", "/math/sum", mapOf(entry("values", listOf(1, 2, 3))), new ResultHandler<Number>() {
@Override public void execute(Number result, Exception exception) {
// 结果是6
}
});结果处理器(result handler)是一个回调,在请求完成的时候就会调用它。在Java 7中,通常会使用匿名内部类来实现结果处理器。在Java 8之后,可以使用lambda表达式来替代,从而将调用代码缩减成如下所示:
//得到“a”和“b”的和
serviceProxy.invoke("GET", "/math/sum", mapOf(entry("a", 2), entry("b", 4)), (result, exception) -> {
//结果是6
});
//得到所有值的和
serviceProxy.invoke("GET", "/math/sum", mapOf(entry("values", listOf(1, 2, 3))), (result, exception) -> {
//结果是6
});如下的样例阐述了如何通过Swift代码来访问数学计算服务。这里会有一个WSWebServiceProxy实例,默认的URL会话会为其提供支撑功能,还有一个代理队列(delegate queue)支持10个并发操作,我们通过它们来执行远程方法调用。结果处理器是通过闭包实现的:
// 配置会话
let configuration = NSURLSessionConfiguration.defaultSessionConfiguration()
configuration.requestCachePolicy = NSURLRequestCachePolicy.ReloadIgnoringLocalAndRemoteCacheData
let delegateQueue = NSOperationQueue() delegateQueue.maxConcurrentOperationCount = 10
let session = NSURLSession(configuration: configuration, delegate: self, delegateQueue: delegateQueue)
// 初始化服务代理并调用方法
let serverURL = NSURL(string: "https://localhost:8443")
let serviceProxy = WSWebServiceProxy(session: session, serverURL: serverURL!)
// 得到“a”和“b”的和
serviceProxy.invoke("GET", path: "/math/sum", arguments: ["a": 2, "b": 4]) {(result, error) in
// 结果是6
}
//得到所有值的和
serviceProxy.invoke("GET", path: "/math/sum", arguments: ["values": [1, 2, 3]]) {(result, error) in
// 结果是6
}最后,这个样例阐述了如何通过JavaScript客户端来访问服务。我们使用WebServiceProxy实例来调用方法,并使用闭包来实现结果处理器:
// 创建服务代理
var serviceProxy = new WebServiceProxy();
// 得到“a”和“b”的和
serviceProxy.invoke("GET", "/math/sum", {a:4, b:2}, function(result, error) {
// 结果是6
});
// 得到所有值的和
serviceProxy.invoke("GET", "/math/sum", {values:[1, 2, 3, 4]}, function(result, error) {
// 结果是6
});更多信息
本文介绍了HTTP-RPC框架并提供了一些样例,展示了如何通过它来便利地创建RESTful Web服务 ,并通过Java、Objective-C/Swift和JavaScript消费Web服务。这个项目目前在GitHub上开发,并且非常活跃,将来还会提供对其他平台的支持。我们鼓励读者的反馈,也欢迎为其贡献功能。
关于它的更多信息,请参见项目的 README页面或通过gk_brown@verizon.net联系作者。
关于作者
Greg Brown是一名软件工程师,在咨询、产品以及开源开发方面有着20年以上的经验。他目前的关注点在于移动应用和REST服务。
查看英文原文: HTTP-RPC: A Lightweight Cross-Platform REST Framework
↧
Netflix 是怎样的一家公司?为什么它在美国非常成功?
奈飞,奈飞,奈何非我鱼与熊掌
陈达
毋庸置疑Netflix模式就是未来。很久很久以前,有一家公司叫Blockbuster,称霸租碟业许多年。某个叫Reed Hastings的哥们在那里租了个碟,结果由于超期归还被黑走“一大笔”逾期费(大概40美元),怒了。然后他忿忿地去健身,发觉健身房商业模式甚是美哉,不管你去得多还是少,会员费半毛钱也不能少交。很不巧,Hastings是一个动不动就要改变世界的软件工程师,想法来了就要干,更不巧的是他当时已经非常有钱。于是愤怒之余他创办了Netflix,也是做租碟生意,没有逾期费并且搞会员制。十三年后Netflix把Blockbuster干到了破产保护,大仇得报。这个故事告诉我们两个道理:1.客户服务一定要做好,不该薅的羊毛就别死命薅,不然你就是逼羊为虎。2. 工程师惹不起。
当然不能说Blockbuster命衰,事实上她是代表了过去输给了未来,而显然Netflix就是未来。但Blockbuster也并非一下子就溃不成军,具体而言她遭到了Netflix商业模式二重进化的长期又残酷的折磨。
商业模式
Netflix商业模式1.0
此阶段Netflix的只是在Blockbuster模式上一次勇敢的进化。
Blockbuster模式很单纯:你来我店,我租你碟,到期还碟,不还扣钱。乍一看八零后们这就是小时候家门口的租录像租书店啊有没有。早期的Blockbuster做的比其他竞争对手更到位的地方,是使用数据分析周围居住群众的人口特征,并以此来决定藏碟的种类。这种商业模式有一个形象的名字叫地主模式 (landlord),意思是我有资产,暂时租给你用一用。顺便一说,追本溯源几乎所有的商业模式都能归结成如下四种形象:Creator (制者),Distibutor (担夫), Landlord (地主)和 Broker (掮客)。
Blockbuster通过特许经营(franchising)和领先一步的数据分析干掉了一大批当地“门口的租碟店”,比较讽刺的是后来干掉她的Netflix用的也是更领先一步的大数据分析。至2004年的峰值,代表“过去”的Blockbuster 一共拥有九千多家店面与接近六万的雇员。所以在创办之初Netflix看起来确实有点在大风车前抽抽的唐吉坷德的意思。至少,当时一些花街极具远见的分析师对其是有颇为客气委婉的点评:一文不值的一坨屎 (a worthless piece of crap)。这坨屎现在值360亿美元,我读书少学历是胎教你真的不要骗我。
在1.0 进化的伊始Netflix只对Blockbuster模式做了两个改变 1. 轻资产化,无店面,网上运营。2. 邮碟到户。用户在网上订碟,Netflix用隔夜快递邮寄给客户,客户看完邮寄回Netflix。相较于Blockbuster,如此操作的直接比较优势是1. O2O,可以不出门,省腿。2. 选择多,你Blockbuster再一脸苦逼地去根据人口数据调整藏碟,也架不住别人线上选择的琳琅满目。
此时的Netflix无论做什么都在琢磨一个问题:怎样才能让用户体验比从Blockbuster租碟更好?很多人认为Netflix是一开始就采用flat rate月费会员制并且不收逾期费用,其实不然,Netflix也是摸石头过河逐步实验新玩法,一开始的收费是每张碟五毛,相比于Blockbuster平均每张五刀优势已经非常明显,四块半的差价让Netflix在需求曲线上向右走出了老远。
到了1999年9月,Netflix终于推出了无到期日、无逾期费、无邮费的三无会员制,一个月会费19.95美元,每次最多租四碟。仅仅取消逾期费这一招就可以把Blockbuster捅出一个大窟窿,因为Blockbuster客户对此费用确实苦不堪言,纷纷倒戈。有人问Blockbuster不会有样学样不收逾期费么?事实是当时逾期费占了Blockbuster总营收的16%,上市公司要向股东交代,大腿肉不敢轻易割。当然后来这块肉还是割了,Blockbuster也尝试自建了线上租碟平台Total Access,但最后都无法阻止这家巨无霸倔强的原地爆炸。
一张图可以描画代表未来的Netflix对战代表过去的Blockbuster天狗食月一般的大场面:

你说Netflix在灭掉老盟主的过程中到底信心有多足,其实他们也是走一步看一步,步步为营。2002年上市的招股说明书中有这么一段悲催的话:“从一开始到现在,我们积累了天量的亏损,我们甚至有9000万美元的权益赤字(资产负债表的负债大于资产)。我们需要极大地提高我们的营业利润率(operating margin)来实现盈利。我们可能永远不能盈利。”
不要看别人,说的就是你呢,京东同学。
Netflix商业模式2.0
用1.0逆袭成新盟主之后,Netflix无论做什么都开始琢磨另一个问题:怎样才能让用户体验比从Netflix租碟更好?我们来到了2006年,这一年是Netflix流媒体(streaming)的元年,在这一年之前Netflix的订阅人数是420万,基本服务月费降至17.99美元。你说流媒体这个点子在当时十分性感新颖吗,其实也谈不上,1995年就有人尝试搞流媒体的生意,但问题是技术实在跟不上灵感,下个片几百个钟头小白菜等成老泡菜。这也说明了新概念能赚钱的前提一定是技术到位,而不是vice versa,想想现在的AI(人工智能)和VR(虚拟现实)。
2006年美国家庭的宽带普及率比2005年上涨了40%,达到8400万人;还有另一个也许更重要的数据变化:相比2005年,家庭全部年收入为4万到5万美元之间的家庭,宽带普及率暴增70%。这是啥意思?这说明最Young最潮最有闲最可能不去看电视而使用Netflix服务的屌丝群体一下子网络化了,根据我个人比较相信的一个商业规律“得屌丝者得天下”,这应该是发展流媒体最好的时光,看起来东风已到。2005年的另一件大事也让仍然在摸索中“流媒体”实验取得了初次大捷:YouTube横空出世。
无论是租碟,还是流媒体,其实Netflix这门生意最核心的价值并无变化:VoD (Video on Demand)内容点播,随性随需求,不同于传统的实时直播(LIve Streaming)。在这一点上流媒体显然能够完胜租碟,所以我们看到Netflix开始逆袭曾经的自己。Netflix的流媒体从明面上看有那么几个优势:1. 便宜,月费降至10美元以下,在需求曲线上走得更远。2. 跨平台,电视、PC、Wii、PlayStation、XBox,you name it, 个性化设置随账户而走,换个平台你照样可以从之前的记忆点开始播。3. 用户个性化设置。4. 无广告或者“推广”或者whatever。4. 自制内容 (Netflix Originals),内容上创新自给自足,在内容独家性上深度布局。
2005年流媒体之前,Netflix订阅人数为420万;2016年流媒体十年之后,Netflix订阅人数为8320万,好一阵四舍五入一个亿的大东风。
护城河勘察(比较优势分析)
Netflix较明显的优势我就不多说了,比如全球市场和规模优势(economies of scales),但你要说它算不算绝对意义上的护城河,这是一个忍者贱人的问题。我认为规模优势在这个行业中其实不算是真正的护城河,因为根据巴老菲特的严酷定义,此河是指公司持久阻挡竞争而保持长久盈利的能力,规模优势在零售业或许尚能算是一圈河,但是在流媒体VoD行业——国内自不必说了早期没有版权壁垒结果有先行优势有规模优势的前辈都是说不行就不行——即使在美国,也有Blockbuster这样短短几年就撒手人寰的忧伤先例。技术革新唰唰唰的行业,规模优势在蜂拥而来的创新型竞争对手的乱拳面前都不是个事儿,说弄残你结果一个下手太重就弄死了你。
谈一谈我认为Netflix真正的护城河。
Content Portfolio (内容组合)
毋庸置疑Netflix上的内容储备十分傲人,如果要看完Netflix上所有的内容,不吃不喝不睡不出翔24/7地刷剧也需要你花将近四年时间。但一个比较让人错乱的事实是:比起2014年,目前Netflix的内容总量萎缩32%。2014年1月Netflix 向美国用户提供6484部电影和1609部剧集;但到了2016年3月,这个数量萎缩到4335部电影和1197部剧集。
Netflix对此的解释是他们排除了大量非独家的内容而尽量保持队伍的纯洁性,比如The Hunger Game (饥饿游戏)系列由于Amazon上也有提供,所以Netflix在版权到期了以后就没有再续期,而是让Hulu屁颠地捡了去。
所以我们看到Netflix目前重心不是在于量而是在于质,尤其是在于内容的独家性,这当然是一个凿护城河的思维,让上了瘾的用户根本无法变节,因为许多内容别无分店。而目前各大机构做的问卷调查也表明Netflix的内容是有点可以护城的。比如Morgan Stanley针对18岁以上人群的代表性抽样调查(样本容量= 2501)显示,29%的受访者表示内容翘楚非Netflix莫属, 18%认为是HBO(时代华纳旗下的付费电视网),而这俩厮遥遥领先其他竞争对手,具体数据可以参考下图。
看得出Netflix近几年在内容上是挺进击的,当然在投入上也是吃了春药的。2012年Netflix在内容上的投入大约是20亿美元,2016年预计要投入60亿美元(原创内容12亿),对一个预计2016年营收大约80亿的公司来说.......花开堪折直须折?

Netflix的原创内容在专业奖项上也是很有竞争力。在刚出炉的2016年艾美奖提名名单里,Netflix收获54个黄金时段艾美奖提名(Primetime Emmy nominations),仅次于FX(Fox旗下的FX电视网)和HBO;收获33个日间时段提名(Daytime Emmy nominations),为所有网络第一。考虑到Netflix自制剧的历史仅有短短的三年,成就已经斐然。Netflix引以为豪的制作包括纸牌屋系列(House of Cards)、女子监狱系列(Orange is the New Black)、制造杀人犯 (Making a Murderer)、毒枭 (Narcos)等等,我个人而言其中除了女子监狱看到一半弃剧了,其他的几部都是要跪着推。
技术与大数据的应用
Amazon看起来在零售业,但其实她是个科技公司;Tesla看起来在造车业,但其实她是个科技公司;Netflix看起来在娱乐业,但其实她是个科技公司。从一开始单挑Blockbuster,Netflix骨子里玩的就是一个O2O的概念,离不开信息技术的开路。时至如今更是如此,Netflix是出了名的开着业内顶薪打着灯笼挖IT工程师,公司官网专门开设Netflix Tech Blog讨论各种尖端技术问题。
Netflix的技术应用本质上要回答两个问题:
1. 如何提升用户观看体验?
2. 如何在内容上投用户所好?

Netflix对第一个问题的回答在我看来是十分有诚意的。据上述数据显示,在高峰时段Netflix占据北美全互联网1/3的带宽,吞吐量颇为惊人。不管用户的带宽是胖是瘦,最基本的体验需求就是两点:要高清,要流畅。但更清楚的画质与更少的带宽,往往是一个美丽的悖论,这就需要Netflix用到流媒体带宽节省的技术。
举个例子,大多数流媒体公司都会根据用户的带宽来决定传输的画质,比如在一个美好的周末晚上你早早地上了床想看个动作片,结果睡你上铺的哥们在打撸啊撸,于是你就眼睁睁地看着你的高清视频变成标清然后变成流畅视频最后变成不流畅视频。这个技术Netflix当然也用,每一个视频都有多个不同质量的视频文件来支持,一个235 kbps的带宽大概可以传输320X240的画面,5800 kbps的带宽可以传输1080p的画面。但是有一个问题,为了适应带宽的限制,同样的大小并且使用同一种encoding技术,压缩一部《魔兽》肯定比压缩一部《海绵宝宝》更狠,画质损失更惨重。
于是Netflix的算法小组花了四年时间来重新coding 这一切,不再进行统一粗暴的一刀切,而是根据每一个资源的特征来量体裁衣(title by title basis),精细化处理,每一部片子都会得到不同的算法。这项技术可以在为用户节省20%的带宽的同时,提高画面的质量,解决美丽的悖论。Netflix的工程师愿意做到多精细?他们认为即使是同一个剧集,每一集都是不同的,每一集都应该有自己的encoding。
总之看起来是超牛X超有诚意的技术啊,我读书少学历是胎教你千万不要骗我。
关于第二个问题,Netflix的答题思路就是为坊间津津乐道多年的大数据分析,并以此为出发点来进行用户推荐和自制原创内容,以大数据拍“大数剧”。这个估计大家都十分熟悉,但是我想问为什么大家都知道Netflix是个玩大数据的公司?各大电视台也都有各自不小的观众数据,HBO之类也有超过5000万的订阅用户,但为什么大家独独知道Netflix玩大数据并且玩得很溜呢?这是为什么呢?
因为是Netflix想让你知道。这是PR宣传的噱头,比如搞个什么比赛设计个大奖来吸引各界人才提供各种算法啦,比如用大数据分析定制《纸牌屋》获得空前成功啦,云云。作为后辈Netflix在行内其实如履薄冰,之前也说了她先是走一步算一步地拼死了Blockbuster,现在又要开始与业内最老牌的电视台制作方叫板,个个都是膀大腰圆腿粗袋深的主,不在PR上搞点噱头出来怎么压得过怎么抢客户。当网络铺天盖地宣传Netflix用大数据来分析用户观看习惯,你就会在心理上接受Netflix向你推荐的种种:好吧我就看你推荐的吧反正我都被你分析过看穿了。不过如果仔细观察你会发现,哟,Netflix的原创内容总是在最前面。好吧也许Netflix已经看穿了我只喜欢看Netflix原创系列。
我反正是不太相信仅仅通过大数据能够做出热门剧,《纸牌屋》之后Netflix还有Hemlock Grove (铁杉树丛),亚马逊靠且仅靠大数据也做了叫Alpha House(阿尔法屋)的剧集,但很显然这些“大数剧”都没有火。说实话在推出一个剧之前,能不能火谁的心里也没数,观众的口味跟个窜天猴儿似的没个水平标准,谁猜得到。所以Netflix大数据分析上面的优势,在这里到底算不算是条护城河,我持怀疑态度不敢枉下结论,谁敢下谁下。不过我倒是相信花大钱能够做出热门剧:砸顶星,砸名导,砸顶级制作团队,砸PR宣传,怎么事大怎么来;而这不就正是拍纸牌屋时Netflix做的么?
总之请你不要用什么大数据来骗我,我读书少,真不懂啥叫用大数据来拍片儿。
城堡搭起来,护城河挖出来,接下来,我们要开始攻城了。
财务数据
先看一下财务表现(货币单位一律为美元)。
2016年 Q1 Q2 盈利为2766万和4076万,2015年 Q3 Q4为2943万和4318万, TTM(最近12个月)每股收益0.29,TTM 市盈率 300x;2016 Q3 Q4每股收益预估0.06和0.07, 2016年每股收益预估0.28,forward ing 市盈率还是300X,当然三百倍的市盈率是不足以吓到我们的,咱都是见过大世面就算没有市盈率又能咋地,早已习惯与麻木。TTM营收为76亿,TTM市销率 5X,这还算拿得出手,营收的高速增长一直是Netflix的强项。
但重点是现金流。Netflix用户成长唰唰唰,大家以为这货必须是一头现金牛,但Netflix其实是一头献金牛。事实上2014年以来Netflix的营业现金流量 (cash flow from operating activities) 就一直是负值,并呈如同一个喇叭口越来越大的趋势,2016年Q2达到 -2.26亿,TTM过去一年营业现金流近-9亿,自由现金流(free cash flow)为-10.4亿,长久以来,这哥们如同一个被砍了八十刀的胖子摊在凶案现场,数年如一日地血流如注。但为啥明明净利是个大正数,现金流出来却如此惨不忍睹?

稍微懂一点营业现金流或者自由现金流计算方式的人都知道,同时出现正数净利与负数现金流,一般就是因为根据权责发生制原则(accrual basis,指收入与支出以实际权责发生的时间来确认,而非现金入账的而时间),产生了非现金的收入或者是现金支出未被费用化导致非现金资产增加。在Netflix的现金流量表中,用间接法(indirect method )从利润推营运现金流的过程里有一个硕大的减项:additions to streaming content assets (流媒体内容资产增加),此为年年季季现金放肆流出的罪魁祸首。行文至此可能有人会问,你能说人话吗?用大白话来讲,悲催现金流的原因是因为Netflix一直坚持不懈地拼在拍片的第一线。拍片你得先花钱,形成一大笔现金流出,但是利润表中并不计费用,而是杀青后计入内容资产,然后再每年进行摊销;所以现金流与净利在财务报表中会出现时间差。
正如之前提到 Netflix最重要的护城河之一就是内容,但是维护这条护城河是需要下血本的。从Netflix的现金流量表中我们可以算出Netflix每年或者每季度花费多少现金在内容上:将additions to streaming content assets与 change in streaming content liabilities (流媒体内容负债变化)做差,观看一下每季度往这条护城河里要扔多少真金白银:

最近12个月共计54.7亿,而Netflix官方预计2016年全年应该会是60亿。从季度来看,仅仅十个季度,花在内容上的现金已经翻倍。当然有人会说,用户数不也是翻番地增长么,花在内容上的成本自然应该水涨船高,毕竟没有肉哪来狼没有电车哪来痴汉。关于Netflix在内容上的投入到底性价比如何,我们可以将内容花费平摊到每一个用户头上。
以下是每季度用户数情况。

将前前图除以前图,可以得到:

我们可以看出为每一个人头所支付的内容花费事实上呈现不断上涨的趋势,理想中的规模效应其实目前并没有实现。究其原因,Netflix的用户增长出现了颓势,Netflix每花一块钱在内容上已经越来越难以拉动用户数量的增长,边际效应递减铁律当前。而这对于一个股价显然由用户增长来支配驱动的所谓“成长股”而言是一件不太美好的事情。

又有人要问了既然这头献金牛献金能力如此强,那么金从何来?简单,借钱呗。我发现大家谈Netflix的时候都不怎么谈债务,难道就因为是成长股大家就不关心融资来源?2014年Q2 长期债务为8.9亿,2015年Q2为23.7亿,2016年Q2为23.7亿,TTM 利息支出为1.4亿,衡量公司偿还利息能力的利息覆盖倍数 (interest coverage ratio,越高表示偿还利息能力越强)为1.89x (EBIT/利息支出),接近应引起警惕的1.5x警戒线。当然Netflix负债中占比最高的不是长期债务,而是关于内容的当期与长期负债,一共接近60亿,因此导致Debt to equity 比率=总负债/所有者权益=3.8,无论是tech业或者是娱乐业,行业平均水平反正肯定不到1。
当然我们仍然能容忍“某些”的“特定”的公司高杠杆经营,因为至少他们还有梦。不过在公司官方网站上的“投资者常见问题”板块,关于“你们打算如何为内容投入来融资?”这个尖锐的问题,公司坦荡的回答是“我们打算使用高利率的债务融资”。所以未来Netflix的债台只会筑得更高,但人家并不是没有告诉你;万一以后垮了,这口锅你还是得自己背。
行业与竞争
让我们把财务方面的不愉快都抛诸脑后,把让人不开心的数字和图表先放在一边,谈一谈质的问题,谈一谈Netflix所处的这个行业。之前说过我认为Netflix最宽的护城河一个是技术,另一个是内容,而显然公司也是围绕这两个重点在发展;但如果我是Netflix的股东,我愿意她单纯地只做一个科技公司,而不要去进军觥筹交错光艳照人的制片业。
为什么?
因为我很讨厌制片业。至少制片业对于公司股东而言是一门憋屈的生意,因为明星要的报酬基本都高到不要脸的地步,制片公司没有定价权。我记得邱国鹭先生在《投资中最简单的事》这本书中说到单纯拍电影的商业模式有内伤,大家看电影都是冲冰冰啊明明啊这些明星,或者冲刚刚啊安安啊这些名导而去,谁都不会冲某一家制片公司去,你听不到有人说“我看电影就冲华谊兄弟”或者“我是长春电影制片厂的脑残粉”。所以美国那么多的电影公司,最后不得不都成为某个媒体集团的附庸,因为仅仅拍片的单一的商业模式根本没法活;但是迪士尼活得好,是因为米老鼠和唐老鸭从来不要求涨工资。
所有人力资源成本贵成狗的行业都不能算是好行业。就像我长期持有一点点曼联足球俱乐部的股份,但是我是在投资吗,绝对不是,纯粹是作为脑残粉来满足一下情怀。从回报率的角度来看,俱乐部可以说是最差的投资,你看鲁尼的工资是每周26万英镑,这些说白了都出自股东的腰包。雅虎CEO Marissa Mayer 2015年的报酬是3600万美元,尚且因为报酬过高而屡遭诟病;但鲁尼2015年一个人的报酬就已经是1700万,问题是曼联还养着十几个小鲁尼,周薪上10万英镑的比比兼是,等于其他大公司同时养十几个几十个顶薪CEO。但是没办法啊足球是个特殊事业,这上阵的几十个大爷就是俱乐部的核心资产,不惜一切代价也要供着。再比如曼联要买尤文图斯的博格巴,要掏1.2亿欧元;这笔交易成了,球迷当然喜闻乐见花的又不是老子的钱,但作为曼联股东应该是无比惆怅。
所以我认为制片业是一个不可爱的行业;但Netflix走上这条坎坷之路,却又是一个必然的选择,因为除此之外其实她并没有其他选择。
我们都知道对于投资者而言,最好的行业就是垄断行业,垄断意味着定价权,意味着生产者剩余(Producer Surplus),虽然对社会福祉不一定是好事,但对股东而言短期内肯定是件好事。企业有定价权,体现在无论是对外的产品服务定价或是对内的人力资源定价或是对上游的供应商的定价,但Netflix曾经有吗?没有,一直以来不敢涨价,因为很大程度上她就是仗着价格优势灭掉了Blockbuster。Netflix甚至曾经还给了一些用户一生的承诺,保证7.99美元/月不变心,这叫做祖父条款 (grandfather clause,意思是指对某些用户保持老合同的效力)。另一方面,对于上游内容提供商Netflix也没有定价权,内容价格年年涨,如果不走上制片之路,,Netflix就会陷入下面这个夺命循环不可自拔:

曾经的Netflix 被困在这个痛苦的闭环里不可开交,他们只能不停地增加内容并不停地试图增加用户数量,但是永远也别想赚钱。
要打破这个闭环只能靠涨价,要涨价而但有不能让用户流失,只能在内容上培养用户黏度,于是自制内容就成为几乎唯一的出口。所以咱一点都不难理解为啥Netflix要走上自制内容这条不归路;而目前Netflix能够成功的关键,取自首席内容官(chief content officer, CCO) Ted Sarandos的一句话,就在于看是“Netflix变成HBO更快,还是HBO 变成Netflix更快。”
但是这样就能够抢到定价权吗?
先不说之前提到制片业对股东而言未必是个好行业,流媒体+原创内容的模式正在被蜂拥而至的竞争者袭用,因为此行业门槛其实不高,有实力的tech公司基本上是说搞就更搞。所以我们看到Netflix的对手排排队可以走出一个浩荡的队伍:Amazon推出Prime Video streaming,迪士尼、21世纪福克斯和康卡斯特(Comcast)这几个传媒巨头联合推出Hulu和Hulu Plus,HBO推出 HBO Now和HBO Go,Dish推出Sling TV,Google有YouTube Red,并且打算明年上线YouTube Unplugged来做TV streaming,Facebook也正在招兵买马找媒体公司找明星找网红,跟媒体不沾边的沃尔玛收购了Vudu,就连在旁边玩沙的Apple也是虎视眈眈,要来亲自操刀streaming的流言也不是一天两天了,并且之前就与HBO直接勾结在一起搞HBO Now。不错,Netflix仍然是当之无愧的行业老大;但是令人哽咽的是,其屁股上却死死地黏着一窝论实力都屌炸天的其他行业的老大。
Netflix的竞争者方阵

流媒体行业的竞争与肉搏将只会越来越奔放,行业的生产者剩余也只会越来越贫瘠;Netflix苦心经营要打破那个痛苦的闭环,但是打破了真的就能迎来曙光吗?Netflix毋庸置疑是伟大的公司,乃是一种生活方式的创造者,比如在美国有一句俚语,叫做 Netflix and chill,意思是“看看Netflix约约pao”(妹子们千万别听到对方说 Let’s Netflix and chill 就天真的以为只是一起看看片放放松然后欣然赴约了,此说法有特殊含义,请叫我护花小使者),Netflix文化已经深入市井与骨髓。但只是不知道在即将到来冰与火的大局里,Netflix的股东们是否能做到内心的chill;以目前的财务状况与行业现状,我真诚地无套路地为他们捏一把小汗。
奈飞虽然刚猛有余,奈何非我欲啖之鱼。
利益披露:作者在文章发表之时不持有上述股票仓位。
本文行文仓莽,如有不足之处,还请各位海涵斧正。

-----------------------------2016年10月18日第三季报更新风歌线-----------------------------------
奈飞2016年三季度报解读:一个新兵蛋子的宽床理想
陈达
不知道你怎么样,但我反正离开了奈飞是没法活。我目前在奈飞上已经是同时奋起直追五部皆让人心力交瘁的美剧(自己制定一个固定的播出时间,超强自律啊有木有),还不算 Bojack Horseman 这种工作累了或者蹲个马桶都能来一集的口水剧(纯美式好莱坞文化,强烈推荐)。这个季度新出的Stranger Things 、The Get Down 和 Narcos 第二季(与惊为天人的第一季相比追打落水狗的情节有点寡淡无味)都是烂番茄超标的准神作,我感觉不去看就会对不起我天残地缺与支离破碎的人生。
所以作为一个影业新兵,奈飞是拼了老命的;所以奈飞说第三季度我新增用户能来个beat 我一点也不惊讶,这一部接一部的神作都绕地球几圈了,我惊讶的是市场的反映是如此地惊讶。
先来看看财务表现。

数字有点密集,让我们来梳理。作为一个教科书式的成长股,首先让奈飞股价上下翻飞最大的守护天使或者作俑元凶就是四个大字:用户增长。过去这一年公司一遇季报就死给你看就是因为用户增长不行,而昨日盘后股价能旱地拔葱自然也是因为用户增长超过预期。我们来看一下用户增长的情况。


截止2016年第三季度,奈飞共有用户8674万,第三季度增长了356万用户,其中美国用户增长3万,国际320万,多出的1万是四舍五入。花街的预期分别是国内增长30万国际增长200万,普遍非常没有期许的目光,所以最后数据出来后大家都吓得纷纷使用撑杆跳。但是其实如果从增长率上来看,无论是国内还是国际仍然比不上去年Q4和今年Q1;何止是比不上根本就是差了一个天地。尤其是美国国内市场基本已经停止发育。好在奈飞给出的第四季度的 guidance还不错,这段让人美好憧憬的预告片也是撑杆跳的一大动力。
营收和净利没什么好说的,反正不是关键指标(搞笑不,净利不是关键指标),值得一提的是近利润率有一定提升,无论是国内还是国际板块我们都看见了利润率的优化。净利不是关键指标是因为比起奈飞的股价,奈飞赚到的钱少得可怜,所以过去12个月市盈率仍然是一个大于300的数字而未来12个月预期市盈率仍然是一个大于100的数字,好在这个没什么反正我们都习惯了。
让我比较惊讶的是市场好像不怎么去关心奈飞是如何使出吃奶甚至吃毒奶的力气来实现用户增长的。从本季报透露的现金流来看,作为一个教科书式的被用户数量绑架的上市公司,奈飞已经真正毫无保留地 all in了,要么一条路走到黑要么一条路走到飞,确实是非常对得起绑架她的华尔街。
我之前的文章说到过看奈飞的损益表要注意一个权责发生制(accrual accounting,指收入与支出的确认以实际权责发生的时间来进行,而不看现金入账的时间)的时间差,如果公司烧掉一笔资本开支去拍片,他不会直接计入费用,而是资本化以后进行摊销。所以你光看损益表是看不出这段时间奈飞烧了多少钱去拍戏的,我们应该去看现金流量表。而在现金流量表中有一项 additions to streaming content assets (流媒体内容资产增加)和另一项 change in streaming content liabilities (流媒体内容负债变化),这两者之差 = “这段时间老子为了拍个片烧了多少钱“。


我曾经提到奈飞是一头献金牛,是一个倒在地上血流如注的胖子。唉我当时还是太年轻了,这个季度我们才看到什么叫做血流如注的,两倍。从负2.5亿到负5亿,这流法也太难看了啊。有人不经要问这是为什么,很简单啊罪魁祸首还不就是拍片烧的嘛,你当一部又一部神作和准神作是自己从地里长出来的。第三季度比第四季度整整多烧了3.6亿美刀子在新内容制作上。之前奈飞预计2016年全年拍戏烧钱60亿,现在三个季度过去已经烧到49亿,看这蹭蹭上窜的势头今年破预算绝对是冇问题。
By the way,奈飞昨天财报也承诺了2017年要继续烧,预算暂时至少还是60亿(我估计是兜不住的)。作为一个每个月付八块钱“爷爷价”(意思是永远不涨价)的资深奈飞用户,我感到很幸福。一年花不到100刀我就能够享受到60亿的诚意巨献,我至今还是不明白为什么不是每一个地球人都订阅了奈飞的服务。
但是作为奈飞的股东可能就要想一想这钱烧得是不是有意义了。这是一个老问题,你烧的钱跟你拉到的皮条相比是否值得?增加用户不难,就像你上街逢人就发钱肯定能引来吆喝说不定还能引来国际友人, 问题是这烧法是否有意义。经济学上有一个大家耳熟能详的边际效用递减原理 (the law of diminishing marginal utility),意思是说给你一个志玲做老婆你会很受用,给你两个也许会更爽,但是给你三个四个一直到一万个,你的幸福感曲线可能就不涨了,甚至会出现呕吐的现象;企业生产也是一样,一开始你可以搞出规模经济,扩大生产而降低成本从而增加利润率,但是你到一定的规模再增加投入可能成本就压不下来了,继续勉强下去甚至能搞出规模不经济(diseconomies of Scale,此乃严肃学术用词,非我意淫而造)。在奈飞上也是一样,你只看见猪变肥五两但是没看见猪多吃十斤啊,所以这笔账要好好算一算。
已知,奈飞本季度增加了356万用户,同时奈飞多烧了3.6亿在拍片上,不算其他零零总总的获客成本,光拍片这一项奈飞平均要多花100刀才能多获取一个净用户(在努力保住原有用户的基础上增加新用户)。而之前呢,Q1到Q2是 85美元/人,15’Q4到16’Q1是 15美元/人,15’Q3到15’Q4是19.7美元/人,我们可以观测到明显的规模不经济。当然由于制片的较长周期,花出去的钱要到影片与剧集上映才能显出其效用,所以这些数目字不一定在时间上精准;但是我们仍然能从中看出奈飞为了增加用户数所付出的巨大代价,以及与这种代价不相匹配的回报。
代价真的不可谓不巨大,那么多烧掉的钱都是融来的,奈飞一直以来债务杠杆都放得不是很高,所以目前拍片的第一筹资渠道就是贴债务上杠杆。
很多人可能会问那么奈飞能不制片吗?答案是一个大写的不能,我之前提到过如果不拍片奈飞就会被网死在如同西绪弗斯推石头上山的夺命循环里。
只有拍片才是出路。

所以说到底这个行当如果有护城河的话,那就只能是内容,剩下的大数据啊算法啊都是虚架子,别人想模仿就能模仿。而奈飞要能够继续把这个雪球滚下去,必须要有最好的原创内容,必须有涨价的能力,甚至是翻倍地涨,你不能指望着全球市场还会有多大的潜力。这种文化领域要想充分渗透全球市场难比何止是登天,比如在我泱泱的大天朝,奈飞你这次不就缴械投降了吗,硬刚光***肿***你还不是刚不过。所以,这个饼或许还能画下去,但是不能只想着越画越大,更应该去想着越画越厚。而我想,之所以奈飞拿出了奶都能飞的劲头来制作一部又一部的神作,为的肯定是最后能紧紧抓住定价权,从而挖出真正的护城河。虽然目前来看这条小河仍然很浅也很飘摇。
当看到大幅度涨价的可行性之前,我还不想做股东(其实我对制片行业有成见所以无论如何都不打算做股东)。但是我个人非常愿意每个月拿出八块钱甚至是翻一番的价钱来做你奈飞的忠实的用户,为你的发展出自己的一份力。这个世界非常需要这样的公司来提升我们的生活品质,而我至今还是不明白为什么不是每一个地球人都订阅了奈飞的服务。
利益披露:作者不持有并在72小时内不会交易NFLX仓位。
本文行文仓莽,如有不足之处,还请各位海涵斧正。
如转载请署名陈达。
来源:知乎 www.zhihu.com
作者: 陈达
【知乎日报】千万用户的选择,做朋友圈里的新鲜事分享大牛。 点击下载
此问题还有 17 个回答,查看全部。
延伸阅读:
如果《纸牌屋》成功是因为大数据,为什么 Netflix 自制的《铁杉树丛》《女子监狱》等其他剧集却没有大热?
为什么《当幸福来敲门》的主角能够成功?
↧
JAVA虚拟机关闭钩子(Shutdown Hook)
Java程序经常也会遇到进程挂掉的情况,一些状态没有正确的保存下来,这时候就需要在JVM关掉的时候执行一些清理现场的代码。JAVA中的ShutdownHook提供了比较好的方案。
JDK提供了Java.Runtime.addShutdownHook(Thread hook)方法,可以注册一个JVM关闭的钩子,这个钩子可以在一下几种场景中被调用:
- 程序正常退出
- 使用System.exit()
- 终端使用Ctrl+C触发的中断
- 系统关闭
- OutOfMemory宕机
- 使用Kill pid命令干掉进程(注:在使用kill -9 pid时,是不会被调用的)
下面是JDK1.7中关于钩子的定义:
public void addShutdownHook(Thread hook)
参数:
hook - An initialized but unstarted Thread object
抛出:
IllegalArgumentException - If the specified hook has already been registered, or if it can be determined that the hook is already running or has already been run
IllegalStateException - If the virtual machine is already in the process of shutting down
SecurityException - If a security manager is present and it denies RuntimePermission("shutdownHooks")
从以下版本开始:
1.3
另请参见:
removeShutdownHook(java.lang.Thread), halt(int), exit(int)首先来测试第一种,程序正常退出的情况:
package com.hook;
import java.util.concurrent.TimeUnit;
public class HookTest
{
public void start()
{
Runtime.getRuntime().addShutdownHook(new Thread(new Runnable() {
@Override
public void run()
{
System.out.println("Execute Hook.....");
}
}));
}
public static void main(String[] args)
{
new HookTest().start();
System.out.println("The Application is doing something");
try
{
TimeUnit.MILLISECONDS.sleep(5000);
}
catch (InterruptedException e)
{
e.printStackTrace();
}
}
}运行结果:
The Application is doing something Execute Hook.....
如上可以看到,当main线程运行结束之后就会调用关闭钩子。
下面再来测试第五种情况(顺序有点乱,表在意这些细节):
package com.hook;
import java.util.concurrent.TimeUnit;
public class HookTest2
{
public void start()
{
Runtime.getRuntime().addShutdownHook(new Thread(new Runnable() {
@Override
public void run()
{
System.out.println("Execute Hook.....");
}
}));
}
public static void main(String[] args)
{
new HookTest().start();
System.out.println("The Application is doing something");
byte[] b = new byte[500*1024*1024];
try
{
TimeUnit.MILLISECONDS.sleep(5000);
}
catch (InterruptedException e)
{
e.printStackTrace();
}
}
}运行参数设置为:-Xmx20M 这样可以保证会有OutOfMemoryError的发生。
运行结果:
The Application is doing something
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
at com.hook.HookTest2.main(HookTest2.java:22)
Execute Hook.....可以看到程序遇到内存溢出错误后调用关闭钩子,与第一种情况中,程序等待5000ms运行结束之后推出调用关闭钩子不同。
接下来再来测试第三种情况:
package com.hook;
import java.util.concurrent.TimeUnit;
public class HookTest3
{
public void start()
{
Runtime.getRuntime().addShutdownHook(new Thread(new Runnable() {
@Override
public void run()
{
System.out.println("Execute Hook.....");
}
}));
}
public static void main(String[] args)
{
new HookTest3().start();
Thread thread = new Thread(new Runnable(){
@Override
public void run()
{
while(true)
{
System.out.println("thread is running....");
try
{
TimeUnit.MILLISECONDS.sleep(100);
}
catch (InterruptedException e)
{
e.printStackTrace();
}
}
}
});
thread.start();
}
}在命令行中编译:javac com/hook/HookTest3.java
在命令行中运行:Java com.hook.HookTest3 (之后按下Ctrl+C)
运行结果:
可以看到效果如预期。
还有几种情况就不一一列出了,有兴趣的读者可以试一下。
相关文章
- java虚拟机 jvm 局部变量表实战
- Class热替换与卸载
- Java虚拟机学习(10):类加载器(ClassLoader)
- Java虚拟机学习(9):对象引用强度
- Java虚拟机学习(8):查看JVM参数及值的命令行工具
- Java虚拟机学习(7):对象内存分配与回收
- Java虚拟机学习(6):对象访问
- Java虚拟机学习(5):内存调优
- Java虚拟机学习(4):JDK可视化监控工具
- Java虚拟机学习(3): 类加载机制
↧
使用python抓取并分析京东商品评论数据
本篇文章是python爬虫系列的第三篇,介绍如何抓取京东商城商品评论信息,并对这些评论信息进行分析和可视化。下面是要抓取的商品信息,一款女士文胸。这个商品共有红色,黑色和肤色三种颜色, 70B到90D共18个尺寸,以及超过700条的购买评论。

京东商品评论信息是由JS动态加载的,所以直接抓取商品详情页的URL并不能获得商品评论的信息。因此我们需要先找到存放商品评论信息的文件。这里我们使用Chrome浏览器里的开发者工具进行查找。
具体方法是在商品详情页点击鼠标右键,选择检查,在弹出的开发者工具界面中选择Network,设置为禁用缓存(Disable cache)和只查看JS文件。然后刷新页面。页面加载完成后向下滚动鼠标找到商品评价部分,等商品评价信息显示出来后,在下面Network界面的左侧筛选框中输入productPageComments,这时下面的加载记录中只有一条信息,这里包含的就是商品详情页的商品评论信息。点击这条信息,在右侧的Preview界面中可以看到其中包含了当前页面中的评论信息。(抓取价格信息输入prices)。

复制这条信息,并把URL地址放在浏览器中打开,里面包含了当前页的商品评论信息。这就是我们要抓取的URL地址。https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv100&productId=10001234327&score=0&sortType=5&page=0&pageSize=10
仔细观察这条URL地址可以发现,其中productId=10001234327是当前商品的商品ID。与商品详情页URL中的ID一致。而page=0是页码。如果我们要获取这个商品的所有评论,只需要更改page后面的数字即可。

在获得了商品评论的真实地址以及URL地址的规律后,我们开始使用python抓取这件商品的700+条评论信息。并对这些信息进行处理和分析。
开始前的准备工作
在开始抓取之前先要导入各种库文件,这里我们分别介绍下需要导入的每个库文件的名称以及在数据抓取和分析中的作用。requests用于进行页面抓取,time用于设置抓取过程中的Sleep时间,random用于生产随机数,这里的作用是将抓取页面的顺序打乱,re用于在抓取后的页面代码中提取需要的信息,numpy用于常规的指标计算,pandas用于进行数据汇总和透视分析,matplotlib用于绘制各站图表,jieba用于对评论内容进行分词和关键词提取。
#导入requests库(请求和页面抓取) import requests #导入time库(设置抓取Sleep时间) import time #导入random库(生成乱序随机数) import random #导入正则库(从页面代码中提取信息) import re #导入数值计算库(常规计算) import numpy as np #导入科学计算库(拼表及各种分析汇总) import pandas as pd #导入绘制图表库(数据可视化) import matplotlib.pyplot as plt #导入结巴分词库(分词) import jieba as jb #导入结巴分词(关键词提取) import jieba.analyse
将爬虫伪装成浏览器
导入完库文件后,还不能直接进行抓取,因为这样很容易被封。我们还需要对爬虫进行伪装,是爬虫看起来更像是来自浏览器的访问。这里主要的两个工作是设置请求中的头文件信息以及设置Cookie的内容。
头文件信息很容易找到,在Chrome的开发者工具中选择Network,刷新页面后选择Headers就可以看到本次访问的头文件信息,里面包含了一些浏览器的技术参数和引荐来源信息。将这些信息直接添加到代码中就可以,这里我们将头部信息保存在headers中。

#设置请求中头文件的信息
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11','Accept':'text/html;q=0.9,*/*;q=0.8','Accept-Charset':'ISO-8859-1,utf-8;q=0.7,*;q=0.3','Connection':'close','Referer':'https://www.jd.com/'
}在查看头文件信息的旁边还有一个Cookies标签,点击进去就是本次访问的Cookies信息。这里的Cookies信息与前面头文件中的Cookie信息一致,不过这里更加清晰。把Request Cookies信息复制到代码中即可,这里我们将Request Cookies信息保存在Cookie中。

#设置Cookie的内容
cookie={'TrackID':'1_VWwvLYiy1FUr7wSr6HHmHhadG8d1-Qv-TVaw8JwcFG4EksqyLyx1SO7O06_Y_XUCyQMksp3RVb2ezA','__jda':'122270672.1507607632.1423495705.1479785414.1479794553.92','__jdb':'122270672.1.1507607632|92.1479794553','__jdc':'122270672','__jdu':'1507607632','__jdv':'122270672|direct|-|none|-|1478747025001','areaId':'1','cn':'0','ipLoc-djd':'1-72-2799-0','ipLocation':'%u5317%u4EAC','mx':'0_X','rkv':'V0800','user-key':'216123d5-4ed3-47b0-9289-12345','xtest':'4657.553.d9798cdf31c02d86b8b81cc119d94836.b7a782741f667201b54880c925faec4b'}抓取商品评论信息
设置完请求的头文件和Cookie信息后,我们开始抓取京东商品评论的信息。前面分析URL的时候说过,URL中包含两个重要的信息,一个是商品ID,另一个是页码。这里我们只抓取一个商品的评论信息,因此商品ID不需要更改。但这个商品的评论有700+条,也就是有近80页需要抓取,因此页码不是一个固定值,需要在0-80之间变化。这里我们将URL分成两部分,通过随机生成页码然后拼接URL的方式进行抓取。
#设置URL的第一部分 url1='https://sclub.jd.com/comment/productPageComments.action?productId=10001234327&amp;amp;score=0&amp;amp;sortType=3&amp;amp;page=' #设置URL的第二部分 url2='&amp;amp;pageSize=10&amp;amp;callback=fetchJSON_comment98vv41127' #乱序输出0-80的唯一随机数 ran_num=random.sample(range(80), 80)
为了使抓取过程看起来更加随机,我们没有从第1页一直抓取到第80页。而是使用random生成0-80的唯一随机数,也就是要抓取的页码编号。然后再将页码编号与两部分URL进行拼接。这里我们只知道商品有700+的评论,但并不知道具体数字,所以抓取范围定位从0-80页。
下面是具体的抓取过程,使用for循环每次从0-80的随机数中找一个生成页码编号,与两部分的URL进行拼接。生成要抓取的URL地址并与前面设置好的头文件信息和Cookie信息一起发送请求获取页面信息。将获取到的页面信息进行汇总。每次请求间休息5秒针,避免过于频繁的请求导致返回空值。
#拼接URL并乱序循环抓取页面
for i in ran_num:
a = ran_num[0]
if i == a:
i=str(i)
url=(url1+i+url2)
r=requests.get(url=url,headers=headers,cookies=cookie)
html=r.content
else:
i=str(i)
url=(url1+i+url2)
r=requests.get(url=url,headers=headers,cookies=cookie)
html2=r.content
html = html + html2
time.sleep(5)
print("当前抓取页面:",url,"状态:",r)
在抓取的过程中输出每一步抓取的页面URL以及状态。通过下面的截图可以看到,在page参数后面的页码是随机生成的并不连续。
抓取完80个页面后,我们还需要对页面进行编码。完成编码后就可以看到其中所包含的中文评论信息了。后面大部分苦逼的工作就是要对这些评论信息进行不断提取和反复的清洗。
#对抓取的页面进行编码 html=str(html, encoding = "GBK")

这里建议将抓取完的数据存储在本地,后续工作可以直接从本地打开文件进行清洗和分析工作。避免每次都要重新抓取数据。这里我们将数据保存在桌面的page.txt文件中。
#将编码后的页面输出为txt文本存储
file = open("c:\\Users \\Desktop\\page.txt", "w")
file.write(html)
file.close()读取文件也比较简单,直接open加read函数就可以完成了。
#读取存储的txt文本文件
html = open('c:\\Users\\ Desktop\\page.txt', 'r').read()提取信息并进行数据清洗
京东的商品评论中包含了很多有用的信息,我们需要将这些信息从页面代码中提取出来,整理成数据表以便进行后续的分析工作。这里应该就是整个过程中最苦逼的数据提取和清洗工作了。我们使用正则对每个字段进行提取。对于特殊的字段在通过替换等方式进行提取和清洗。
下面是提取的第一个字段userClient,也就是用户发布评论时所使用的设备类型,这类的字段提取还比较简单,一行代码搞定。查看一下提取出来的字段还比较干净。使用同样的方法我们分别提取了以下这些字段的内容。
#使用正则提取userClient字段信息 userClient=re.findall(r',"usefulVoteCount".*?,"userClientShow":(.*?),',html) #使用正则提取userLevel字段信息 userLevel=re.findall(r'"referenceImage".*?,"userLevelName":(.*?),',html) #使用正则提取productColor字段信息 productColor=re.findall(r'"creationTime".*?,"productColor":(.*?),',html) #使用正则提取recommend字段信息 recommend=re.findall(r'"creationTime".*?,"recommend":(.*?),',html) #使用正则提取nickname字段信息 nickname=re.findall(r'"creationTime".*?,"nickname":(.*?),',html) #使用正则提取userProvince字段信息 userProvince=re.findall(r'"referenceImage".*?,"userProvince":(.*?),',html) #使用正则提取usefulVoteCount字段信息 usefulVoteCount=re.findall(r'"referenceImage".*?,"usefulVoteCount":(.*?),',html) #使用正则提取days字段信息 days=re.findall(r'"usefulVoteCount".*?,"days":(.*?)}',html) #使用正则提取score字段信息 score=re.findall(r'"referenceImage".*?,"score":(.*?),',html)</pre>
还有一些字段比较负责,无法通过正则一次提取出来,比如isMobile字段,有些值的后面还有大括号。这就需要进一步的提取和清洗工作。
#使用正则提取isMobile字段信息 isMobile=re.findall(r'"usefulVoteCount".*?,"isMobile":(.*?),',html)

使用for循环配合替换功能将字段中所有的}替换为空。替换完成后字段看起来干净多了。
#替换掉最后的}
mobile=[]
for m in isMobile:
n=m.replace('}','')
mobile.append(n)
productSize字段中包含了胸围和杯罩两类信息,为了获得独立的杯罩信息需要进行二次提取,将杯罩信息单独保存出来。
#使用正则提取productSize字段信息 productSize=re.findall(r'"creationTime".*?,"productSize":(.*?),',html)

使用for循环将productSize中的第三个字符杯罩信息提取出来,并保持在cup字段中。
#提取杯罩信息
cup=[]
for s in productSize:
s1=s[3]
cup.append(s1)

创建评论的日期信息仅依靠正则提取出来的信息还是比较乱,无法直接使用。因此也需要进行二次提取。下面是使用正则提取出的结果。
#使用正则提取时间字段信息 creationTime1=re.findall(r'"creationTime":(.*?),"referenceName',html)

日期和时间信息处于前20个字符,在二次提取中根据这个规律直接提起每个条目的前20个字符即可。将日期和时间单独保存为creationTime。
#提取日期和时间
creationTime=[]
for d in creationTime1:
date=d[1:20]
creationTime.append(date)

在上一步日期和时间的基础上,我们再进一步提取出单独的小时信息,方法与前面类似,提取日期时间中的第11和12个字符,就是小时的信息。提取完保存在hour字段以便后续的分析和汇总工作。
#提取小时信息
hour=[]
for h in creationTime:
date=h[10:13]
hour.append(date)

最后要提取的是评论内容信息,页面代码中包含图片的评论信息是重复的,因此在使用正则提取完后还需要对评论信息进行去重。
#使用正则提取评论信息 content=re.findall(r'"guid".*?,"content":(.*?),',html)
使用if进行判断,排除掉所有包含图片的评论信息,已达到评论去重的目的。
#对提取的评论信息进行去重
content_1=[]
for i in content:
if not "img" in i:
content_1.append(i)完成所有字段信息的提取和清洗后,将这些字段组合在一起生成京东商品评论数据汇总表。下面是创建数据表的代码。数据表生成后还不能马上使用,需要对字段进行格式设置,例如时间和日期字段和一些包含数值的字段。具体的字段和格式设置依据后续的分析过程和目的。这里我们将creationTime设置为时间格式,并设置为数据表的索引列。将days字段设置为数值格式。
#将前面提取的各字段信息汇总为table数据表,以便后面分析
table=pd.DataFrame({'creationTime':creationTime,'hour':hour,'nickname':nickname,'productColor':productColor,'productSize':productSize,'cup':cup,'recommend':recommend,'mobile':mobile,'userClient':userClient,'userLevel':userLevel,'userProvince':userProvince,'usefulVoteCount':usefulVoteCount,'content_1':content_1,'days':days,'score':score})
#将creationTime字段更改为时间格式
table['creationTime']=pd.to_datetime(table['creationTime'])
#设置creationTime字段为索引列
table = table.set_index('creationTime')
#设置days字段为数值格式
table['days']=table['days'].astype(np.int64)#查看整理完的数据表 table.head()

这里建议再次保存清洗和预处理完的数据表。我们这里将数据表保存为csv格式。到了这一步可以选择在Excel中完成后续的数据分析和可视化过程,也可以继续在python中完成。我们这里选择继续在python中完成后续的数据分析和可视化工作。
#保存table数据表
table.to_csv('jd_table.csv')数据分析及可视化
分月评论数据变化趋势
首先查看京东商品评论的时间变化趋势情况,大部分用户在购买商品后会在10天以内进行评论,因此我们可以近似的认为在一个月的时间维度中评论时间的变化趋势代表了用户购买商品的变化趋势。
按月的维度对数据表进行汇总,并提取每个月的nickname的数量。下面是具体的代码和分月数据。
#对数据表按月进行汇总并生成新的月度汇总数据表
table_month=table.resample('M',how=len)
#提取按月汇总的nickname
month=table_month['nickname']
数据范围从2015年11月到2016年11月。使用柱状图对分月数据进行可视化。从图表中可以看到2016年6月是评论的高峰,也可以近似的认为这个时间段是用户购买该商品的高峰(6月18日是京东店庆日)。排除2016年6月和不完整的11月数据,整齐趋势中冬季评论量较低,夏季较高。这是由于该商品的季节属性导致的,超薄胸罩更适合夏天佩戴(这个属性我们是在用户的评论中发现的,在京东的商品介绍中并不明显,只在标题中以”薄杯”说明)。
#绘制分月评论数量变化趋势图
plt.rc('font', family='STXihei', size=9)
a=np.array([1,2,3,4,5,6,7,8,9,10,11,12,13])
plt.bar([1,2,3,4,5,6,7,8,9,10,11,12,13],month,color='#99CC01',alpha=0.8,align='center',edgecolor='white')
plt.xlabel('月份')
plt.ylabel('评论数量')
plt.title('分月评论数量变化趋势')
plt.legend(['评论数量'], loc='upper right')
plt.grid(color='#95a5a6',linestyle='--', linewidth=1,axis='y',alpha=0.4)
plt.xticks(a,('15-11','12','16-01','02','03','04','05','06','07','08','09','10','11'))
plt.show()
通过筛选将数据表分为使用移动设备和未使用移动设备两个表格,再分别查看和对比评论变化趋势。
#在table表中筛选使用移动设备的条目并创建新表
mobile_t=table.loc[table["mobile"] == "true"]
#在table中筛选没有使用移动设备的条目并创建新表
mobile_f=table.loc[table["mobile"] == "false"]
#按月汇总使用移动设备的数据
mobile_t_m=mobile_t.resample('M',how=len)
#按月汇总不使用移动设备的数据
mobile_f_m=mobile_f.resample('M',how=len)
#提取使用移动设备的按月汇总nickname
mobile_y=mobile_t_m['nickname']
#提取没有使用移动设备的按月汇总nickname
mobile_n=mobile_f_m['nickname']从结果中可以看出使用移动设备进行评论的用户在所有的时间段中都要明显高于使用PC的用户。
#绘制PC与移动设备评论数量变化趋势图
plt.subplot(2, 1, 1)
plt.plot(mobile_y,'go',mobile_y,'g-',color='#99CC01',linewidth=3,markeredgewidth=3,markeredgecolor='#99CC01',alpha=0.8)
plt.ylabel('移动设备评论数量')
plt.title('PC与移动设备评论数量变化趋势')
plt.subplot(2, 1, 2)
plt.plot(mobile_n,'go',mobile_n,'g-',color='#99CC01',linewidth=3,markeredgewidth=3,markeredgecolor='#99CC01',alpha=0.8)
plt.xlabel('月份')
plt.ylabel('PC评论数量')
plt.show()
24小时评论数量变化趋势
按小时维度对评论数据进行汇总,查看用户在24小时中的评论变化趋势。这里需要说明的是24小时趋势只能反映用户登录京东商城的趋势,并不能近似推断用户购买商品的时间趋势。
#按24小时分别对table表中的nickname进行计数
hour_group=table.groupby('hour')['nickname'].agg(len)从24小时评论趋势图来看,发布商品评论的趋势与作息时间一致,并且每日的闲暇时间是发布评论的高峰。如早上的8点,中午的12点和晚上的22点,是一天24小时中的三个评论高峰点。
#汇总24小时评论数量变化趋势图
plt.rc('font', family='STXihei', size=9)
a=np.array([1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23])
plt.bar([1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23],hour_group,color='#99CC01',alpha=0.8,align='center',edgecolor='white')
plt.xlabel('24小时')
plt.ylabel('评论数量')
plt.title('24小时评论数量变化趋势')
plt.legend(['评论数量'], loc='upper right')
plt.grid(color='#95a5a6',linestyle='--', linewidth=1,axis='y',alpha=0.4)
plt.xticks(a,('0','1','2','3','4','5','6','7','8','9','10','11','12''13','14','15','16','17','18','19','20','21','22','23'))
plt.show()
将24小时的评论数量分为移动设备和未使用移动设备,查看并对比这两者的变化趋势情况。
#在使用移动设备的表中按24小时对nickname进行计数
mobile_y_h=mobile_t.groupby('hour')['nickname'].agg(len)
#在没有使用移动设备的表中按24小时对nickname进行计算
mobile_n_h=mobile_f.groupby('hour')['nickname'].agg(len)移动设备的评论数量在24小时中的各个时间段都要高于PC的评论数量,并且在晚间更加活跃,持续时间高于PC端。这里我们产生了一个疑问,在一天中的工作时间段中,大部分用户都会在电脑旁,但为什么这些时间段里移动设备的评论数量也要高于PC端呢?这是否与胸罩这个产品的私密性有关联。用户不希望别人看到自己购买的商品或评论的内容,所以选择使用移动设备进行评论?
#汇总PC与移动设备24小时评论数量变化趋势
plt.subplot(2, 1, 1)
plt.plot(mobile_y_h,'go',mobile_y_h,'g-',color='#99CC01',linewidth=3,markeredgewidth=3,markeredgecolor='#99CC01',alpha=0.8)
plt.ylabel('移动设备评论数量')
plt.title('PC与移动设备24小时评论数量变化趋势')
plt.subplot(2, 1, 2)
plt.plot(mobile_n_h,'go',mobile_n_h,'g-',color='#99CC01',linewidth=3,markeredgewidth=3,markeredgecolor='#99CC01',alpha=0.8)
plt.xlabel('24小时')
plt.ylabel('PC评论数量')
plt.show()
用户客户端分布情况
前面的分析中,我们看到使用移动设备进行评论的用户要远高于PC端的用户,下面我们对用户所使用的设备分布情况进行统计。首先在数据表中按用户设备(userClient)对nickname字段进行计数汇总。
#在table表中按userClient对数据进行汇总
userClient_group=table.groupby('userClient')['nickname'].agg(len)从用户客户端分布情况来看,移动端的设备占大多数,其中使用iphone的用户要高于Android用户。由于微信购物和QQ购物单独被分了出来,无法确定设备,因此单独进行对比。使用微信购物渠道的用户要高于QQ购物。
#汇总用户客户端分布情况
plt.rc('font', family='STXihei', size=9)
a=np.array([1,2,3,4,5,6])
plt.bar([1,2,3,4,5,6],userClient_group,color='#99CC01',alpha=0.8,align='center',edgecolor='white')
plt.xlabel('客户端分布')
plt.ylabel('评论数量')
plt.title('用户客户端分布情况')
plt.legend(['评论数量'], loc='upper right')
plt.grid(color='#95a5a6',linestyle='--', linewidth=1,axis='y',alpha=0.4)
plt.ylim(0,300)
plt.xticks(a,('PC','Android','iPad','iPhone','微信购物','QQ购物'))
plt.show()
购买后评论天数分布
在购买后评论天数方面,我们将用户发布评论与购买的时间间隔分为7组,分别为购买后1-5天内,5-10天内,10-15天内,15-20天内,20-25天内,25-30天内,以及大于30天。然后统计并对比用户在不同时间区间内发布评论的数量情况。
#设置分组条件,并对table表中的days字段进行分组
bins = [0, 5, 10, 15, 20, 25, 30, 92]
day_group = ['5天', '10天', '15天', '20天', '25天','30天','大于30天']
table['day_group'] = pd.cut(table['days'], bins, labels=day_group)
#按新设置的分组对数据进行汇总
days_group=table.groupby('day_group')['nickname'].agg(len)从图表中看出,购买后5天以内是用户发布评论的高峰,也就我们之前推测评论时间趋势近似于购买时间的依据。随着时间的增加评论数量逐渐下降。
#绘制用户购买后评论天数分布图
plt.rc('font', family='STXihei', size=9)
a=np.array([1,2,3,4,5,6,7])
plt.bar([1,2,3,4,5,6,7],days_group,color='#99CC01',alpha=0.8,align='center',edgecolor='white')
plt.xlabel('购买后天数')
plt.ylabel('发布评论数量')
plt.title('购买后评论天数分布')
plt.legend(['评论数量'], loc='upper right')
plt.grid(color='#95a5a6',linestyle='--', linewidth=1,axis='y',alpha=0.4)
plt.ylim(0,300)
plt.xticks(a,('5天','10天','15天','20天','25天','30天','大于30天'))
plt.show()
商品评分分布情况
京东商城对商品按5星评分划分为好评,中评和差评三个等级。我们这里来看下用户5星评分的分布情况。在数据表中score字段中的值表示了用户对胸罩产品的打分情况。我们按打分情况对数据进行汇总。
#在table表中按score对数据进行汇总
score_group=table.groupby('score')['nickname'].agg(len)
#绘制用户评分分布情况图
plt.rc('font', family='STXihei', size=9)
a=np.array([1,2,3,4,5])
plt.bar([1,2,3,4,5],score_group,color='#99CC01',alpha=0.8,align='center',edgecolor='white')
plt.xlabel('评分分布')
plt.ylabel('评论数量')
plt.title('用户评分分布情况')
plt.legend(['评论数量'], loc='best')
plt.grid(color='#95a5a6',linestyle='--', linewidth=1,axis='y',alpha=0.4)
plt.ylim(0,700)
plt.xticks(a,('1星','2星','3星','4星','5星'))
plt.show()从图表中可以看出,大部分用户对商品的评分是5星。4星以下的几乎没有。但从另一个维度来看,在用户对最有用评论的投票(usefulVoteCount)中得票最多的是一个1星的评论。

用户胸罩尺码分布情况
在胸罩的尺寸方面包含两个信息,一个是胸围尺寸,另一个是罩杯。我们在前面的清洗过程中对杯罩创建了单独的字段。下面只对这个字段进行汇总统计。
#在table 表中按cup对数据进行汇总
cup_group=table.groupby('cup')['nickname'].agg(len)从图表中可以看出,评论用户中最多的是B杯罩,其次为C杯罩,D和E的用户数量较少。
#绘制用户胸罩尺码分布图
plt.rc('font', family='STXihei', size=9)
a=np.array([1,2,3,4])
plt.bar([1,2,3,4],cup_group,color='#99CC01',alpha=0.8,align='center',edgecolor='white')
plt.xlabel('尺码')
plt.ylabel('评论数量')
plt.title('用户胸罩尺码分布情况')
plt.legend(['评论数量'], loc='upper right')
plt.grid(color='#95a5a6',linestyle='--', linewidth=1,axis='y',alpha=0.4)
plt.ylim(0,350)
plt.xticks(a,('B','C','D','E'))
plt.show()
胸罩颜色偏好分布
这款胸罩共分为三个颜色,红色,肤色和黑色。我们按颜色对评论数据进行汇总,查看用户对不同胸罩颜色的偏好情况。
#在table表中按productColor对数据进行汇总
color_group=table.groupby('productColor')['nickname'].agg(len)从不同颜色的评论数量上来看,大部分用户购买的是肤色,购买红色和黑色的用户数量明显少于肤色。
#绘制用户颜色选择分布图
plt.rc('font', family='STXihei', size=9)
a=np.array([1,2,3])
plt.bar([1,2,3],color_group,color='#99CC01',alpha=0.8,align='center',edgecolor='white')
plt.xlabel('颜色分布')
plt.ylabel('评论数量')
plt.title('用户颜色选择分布')
plt.legend(['评论数量'], loc='upper right')
plt.grid(color='#95a5a6',linestyle='--', linewidth=1,axis='y',alpha=0.4)
plt.ylim(0,600)
plt.xticks(a,('红色','肤色','黑色'))
plt.show()
不同尺码用户对胸罩颜色偏好对比
在前面杯罩尺寸和颜色偏好的基础上,我们将两维度进行交叉分析,查看并对比不同杯罩尺码用户在颜色选择上是有规律或明显差异。这里使用数据透视表,将杯罩尺寸设置为行,颜色设置为列,对nickname进行计数。
#使用数据透视表对胸罩尺码和颜色进行交叉分析 color_size=pd.pivot_table(table,index=["cup"],values=["nickname"],columns=["productColor"],aggfunc=len,fill_value=0)
从数据透视表中分别提取出不同尺寸杯罩用户购买的颜色数据。
#提取B,C,D,E尺码的颜色分布 b=color_size.ix['B'] c=color_size.ix['C'] d=color_size.ix['D'] e=color_size.ix['E']
将不同杯罩尺寸用户对颜色的选择分布绘制成四个图表,进行对比和分析。
#汇总不同胸罩尺码颜色分布图
plt.rc('font', family='STXihei', size=9)
plt.subplot(2, 2, 1)
plt.bar([1,2,3],b,color=["#EE9788","#E2D4C9","#151419"],alpha=0.8,align='center',edgecolor='white')
plt.title('B Cup')
plt.xticks(a,('红色','肤色','黑色'))
plt.subplot(2, 2, 2)
plt.bar([1,2,3],c,color=["#EE9788","#E2D4C9","#151419"],alpha=0.8,align='center',edgecolor='white')
plt.title('C Cup')
plt.ylim(0,200)
plt.xticks(a,('红色','肤色','黑色'))
plt.subplot(2, 2, 3)
plt.bar([1,2,3],d,color=["#EE9788","#E2D4C9","#151419"],alpha=0.8,align='center',edgecolor='white')
plt.title('D Cup')
plt.xticks(a,('红色','肤色','黑色'))
plt.subplot(2, 2, 4)
plt.bar([1,2,3],e,color=["#EE9788","#E2D4C9","#151419"],alpha=0.8,align='center',edgecolor='white')
plt.title('E,Cup')
plt.xticks(a,('红色','肤色','黑色'))
plt.show()在下面的图表中,B,C,D,E四个杯罩的用户选择肤色的数量都要高于另外两种颜色。整体差别并不明显。如果非要说有什么差别的话,C杯罩用户更偏好红色?D杯罩更喜欢黑色?这个结论明显站不住脚。但有一点可以说,虽然黑色显瘦但E杯罩的用户中没有人选择黑色。

D&E Cup用户城市分布情况
最后我们再看看下D杯罩和E杯罩用户的城市分布情况,在数据表中并不是所有的评论都有城市信息。因此按城市统计出来的数据可能并不准确,仅供参考。
首先从数据表中筛选出cup值为D和E的数据,并保存在新的数据表中。
#从table表中提取cup尺寸为D或E的数据条目并创建新表 table_big=table.loc[(table["cup"] == "D")|(table["cup"] == "E")]
在新的数据表中按用户所在城市(userProvince)进行汇总。查看不同城市D和E杯罩的数量。
#按城市对数据进行计数汇总
city_group=table_big.groupby('userProvince')['nickname'].agg(len)将汇总结果绘制为图表,从图表来看,数量最多的为未知城市,排除未知城市,北京和广东的数量遥遥领先,其次为四川和河南。
#汇总D和E Cup城市分布图
plt.rc('font', family='STXihei', size=9)
a=np.array([1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24])
plt.barh([1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24],city_group,color='#99CC01',alpha=0.8,align='center',edgecolor='white')
plt.xlabel('评论数量')
plt.ylabel('城市')
plt.title('D Cup和E Cup城市分布')
plt.legend(['评论数量'], loc='upper right')
plt.grid(color='#95a5a6',linestyle='--', linewidth=1,axis='x',alpha=0.4)
plt.yticks(a,('未知','上海','云南','内蒙古','北京','四川','天津','宁夏','安徽','山东','广东','江西','江苏','江西','河北','河南','浙江','湖北','湖南','甘肃','福建','辽宁','重庆','青海','香港'))
plt.show()
胸罩评论内容语义分析
前面我们分别对数据表中的字段进行了统计和分析,文章最后我们对商品的评论内容进行语义分析,看看大家在这700+条评论中都在说些什么。
好好先生购买比例
在人工查看了一些评论内容后,我们发现一些有意思的信息。有一部分评论是老公或男朋友发的,这说明一些好好先生会帮老婆或女友购买胸罩。那么这部分用户的比例有多少呢?
我们把评论中包含有关键词“老婆”和“女朋友”的评论单独保存在出来。
#筛选包含”老婆”和”女朋友”的评论
content_2=[]
for i in content_1:
if "老婆"in i or "女朋友"in i:
content_2.append(i)查看这些包含关键词的评论内容,确实是老公和男朋友来购买胸罩并且发布的评论。
#查看评论内容 content_2

经过计算,在这款胸罩产品的评论中,由老公或男朋友购买的比例仅为2.35%。
#计算老公或男朋友购买胸罩的比例 len(content_2)/len(content_1)*100 2.3545706371191137
商品评论关键词分析
回归到商品评论分析,我们使用结巴分词对所有胸罩的评论信息进行了分词,并提取了权重最高的关键词列表。
#文本数据格式转换
word_str = ''.join(content_1)
#提取文字关键词
word_rank=jieba.analyse.extract_tags(word_str, topK=20, withWeight=True, allowPOS=())
#转化为数据表
word_rank = pd.DataFrame(word_rank,columns=['word','rank'])
#查看关键词及权重
word_rank.sort('rank',ascending=False)从高权重关键词列表来看,用户评论以正面信息为主,”不错”,”舒服”,”喜欢”等主观感受的正面评论权重较高。

结语
本篇文章我们从商品评论信息的抓取,清洗到分析和数据可视化实现了一个完整的闭环。整个过程中数据的清洗和预处理是最为复杂也是耗时最多的工作。由于抓取的数据量较少,只有700+条数据。因此里面的一些结论可能没有代表性,结论也未必准确,仅供参考。
—【所有文章及图片版权归 蓝鲸(王彦平)所有。欢迎转载,但请注明转自“ 蓝鲸网站分析博客”。】—
↧
↧
微店 MySQL 自动化运维实践
前言
互联网时代,数据库如何满足敏捷开发,敏捷交付的要求。传统靠DBA人肉执行的方式,在面对大量业务需求时,DBA手速再快,记忆力再好估计也不能提供好的数据库服务。在介绍自动化运维之前,我们来了解下是怎么使用数据库的。
数据库的使用方式主要有两种:
应用混合部署(实例):有新数据库需求时,很多人都会选择找个实例,建个数据库和帐号提供给业务。好处是能快速提供数据库服务,这种方式在数据库运维的过程中会出现一些问题:第一,相互影响,个别应用有问题会影响所有数据库;第二, 应用DB的性能指标(qps, tps, rt...)不能获取;第三,定位问题源困难;第四,资源使用不合理。为了解决以上问题,最终会有拆库的过程,拆过库的同学都知道,一个拆库动作需要确认很多东西,所花费的时间是非常多的,过程中容易产生故障。
应用独享(实例):在虚拟化,微服务深入人心的今天,应用独享实例是数据库给出的解决办法。我们做到的是所有应用独享实例(分库分表的应用如:分成32个库的应用,业务初期阶段会分布在几个实例中,业务确实需要更多资源时再进行自动化拆库扩容)。这种方式需要大量的实例,传统单机单实例的运维体系就需要演变成单机多实例的方式。
由此引出会有一系列问题需要解决:如何快速提供数据库服务?如何避免数据库资源合理分配?数据库监控怎么做?多实例数据库HA怎么做?
MySQL的标准化与自动化
我们实现的MySQL自动化运维体系能够解决规模化的痛点,主要包括实例创建、部署、监控、备份、HA切换、迁移、扩容等的自动化,所有模块的主发点是要能“自动化”的方式运作,尽量少的人为参与。
一、标准化
数据库上了一定规模后,数据库的各方面都需要标准规范起来,才能接下去做自动化。实例上的标准化我们主要做了以下几点:
1.应用独享实例
2.数据库M<==>S结构,备库不提供业务流量(异地容灾除外)
很多人会选择一主多备,备库提供读流量。这种架构引起的故障挺多的,因为备库一定会存在延时,备库机器也会挂掉。事实上大部分时候流量都在主库是没问题,如果确实主库压力真的太大怎么办,我们应该及时发现问题并作出应对(方法可以是缓存+拆库)。
3.MySQL标准化(带thread_pool 功能MySQL)
数据库版本一致
“相同”的my.cnf(除个别个性参数如server_id,buffer_pool_size等)
文件目录一致
二、构建MySQL自动化运维体系
一套很好的大规模运维体系DBManage,整体思路是让一切自动化起来,不需要打通机器间的信任关系,避免或减少人为参与。

1.多实例创建
一台机器上面开启多个不同的端口,运行多个MySQL服务进程,共用MySQL程序,使用不同配置文件,提供服务。
关键点:
“相同”的my.cnf(除个别个性参数如server_id,buffer_pool_size等)
数据文件目录标准化
创建实例(1.初始化一个标准的数据库,2.新建实例通过rsync控制速率,通过修改 " my.cnf " 文件新建不同实例,因为mysql_install_db安装新实例会占用过多IO)
2. 元数据与监控
数据库监控没有采用类似“lepus”的方式,中心控制的方式对于规模化精细华数据库管理冲突。中心化存在问题1:增加实例需要手动录入;问题2:不能获取响应时间RT(tcprstat);问题3:不能获取主机性能数据等等。我们采用自研 db_agent 实现实例的自动发现,各项元数据及性能数据采集,告别人工处理。
每台数据库服务器上运行db_agent;自动发现实例,自动采集实例数据,主机数据,磁盘数据,自动添加监控。db_agent主要实现以下功能。
采集实例信息(数据库列表,复制信息,表元数据等等)
心跳更新(每秒更新,因为show slave status的延时是不可靠的)
数据库性能数据( QPS, TPS......)
数据库响应时间RT(tcprstat)
实时慢SQL
主机性能数据(告别zabbix)
3. 备份
数据库机器部署备份脚本(不区分是否主备机器),告别手动配置。
只备份备库(备份前判断脚色)
多实例并发控制(控制速率及时间)
直接写入hdfs 或server(推荐hdfs存储)
4. 本地执行agent
远程操作DB机器(创建实例,恢复数据库,etc),通过自定义一些消息调起DB机器对应脚本进行操作
5. 监控告警
基于db_agent采集数据,性能画图及告警。性能数据写入graphite
6. MySQL高可用
传统的使用MHA做MySQL HA架构是比较通用的方案,主要特点:通过Health Check 监控MySQL集群,应用通过VIP访问MySQL,VIP通过keepalive选主。这里不展开这种方式和一些改进型(zookeeper +MHA)的痛点,主要讲下多实例下基于zookeeper是怎么实现MySQL自动化高可用。
改造后的HA架构,跟通常架构的区别在于我们去掉了MySQL集群里的VIP,使用VDDS替代;完全去掉MHA。通过zookeeper分布式,实现ha_console的高可用。

整个流程是
VDDS(微店分布式数据库) 新建应用配置
ha_agent向zookeeper注册临时节点,并实时更新实例信息。
{
"source_db_role": "slave",
"master_instance": "192.168.1.12_3306",
"repl_status": "ok",
"h_time_delay": 0,
"repl_delay": 0,
"last_change_time": "2016-10-15-01:00:45"
}
ha_console根据zookeeper节点信息构造切换元数据(包括延时,切换对象,复制状态)
"192.168.1.11_3306": "{
"source_db_role": "master",
"master_instance": "192.168.1.12_3306",
"repl_status": "ok",
"h_time_delay": 0,
"repl_delay": 0,
"last_change_time": "2016-10-15-01:00:45"
}"
ha_console监听alive目录临时节点
alive目录临时节点消失进行切换(判断延时及复制状态,不符合条件不切换),切换VDDS和数据库
切换前记录切换信息(slave:master_log_file: mysql-bin.000007,exec_master_log_pos: 57830。主库恢复后,用来生成日志解析)
场景一:实例Crash,实例所在的服务器正常运行,ha_agent运行正常
实例Crash,ha_agent 正常运行,主动删除zookeeper 临时节点,ha_console 判断数据库角色,是主库走切换流程。原实例起来之后,作为备库运行。
场景二:实例所在的主机Crash。(实例和ha_agent同时Crash)
此时,由于ha_agent和实例同时Crash,zookeeper到ha_agent间的通讯失败。zookeeper 等待超过租约的时间,ha_console 判断数据库角色,是主库走切换流程。原实例起来之后,作为备库运行。
场景三:实例正常,网络异常
网络异常会发生大量实例掉线或部份异常。大量节点异常:ha_console判断时间范围内异常实例数量,超过阀值不进行切换,同时切换过程:切换脚本会去判断数据库状态,避免误切。(zookeeper client 连接掉线后,尽管实例及ha_agent正常运行,节点不能重用必须等待超时)
特点:完全不需要人工建入,切换元数据自动构建,所有实例自动注册,构造完整的切换元数据,避免了繁锁的配置或配置出错导致不能切换。
7.DBTask
通过DBTask 替代人工操作。实现了数据库创建,配置VDDS, 数据库迁移,拆库扩容,恢复等等。整体思路是分解动作,每个脚本干一件事,再串起所有脚本。以数据库迁移为例我们可以分解为各个子任务,串起任务就是一个完整的自动化数据库迁移任务。
数据库迁移:
申请可用资源
实例创建
恢复备库A
恢复备库B
配置数据源(VDDS)
切换前检查
切换
清除VDDS配置
关闭老实例
数据库资源申请:
申请可用资源
实例创建
新建库,MySQL帐号
配置数据源(VDDS)
成果及展望
全套自动化运维体系采用:后台由python+shell+go(实时慢sql解析部分);前端采用laravel+angularjs。 目前单机日常环境运行100+实例,agent的资源占用不多;业务申请数据库资源<1分钟完成;自动化拆库(部份老的合在一起的还是要拆的:sob:)等等。另外随着MySQL自动化运维的深入,慢慢的发现这将会演变数据库成私有云平台。对于如何更好的服务业务,如何诊断业务数据库等等都需要我们去完善。
参考资料
python socket通信:
https://github.com/chris-piekarski/python-json-socket
python hdfs
https://pypi.python.org/pypi/hdfs/
响应时间(rt):
https://github.com/Lowercases/tcprstat
python zookeeper:
https://github.com/python-zk/kazoo
go tidb解析sql 中的表(用来合并分表)
https://github.com/pingcap/tidb

↧
智慧医疗,需要的不只是大数据

本月初,由微软亚洲研究院和中文信息学会语言与知识计算专业委员会联合主办,成都市青羊区人民政府提供支持的 “知识图谱与智慧医疗(成都)论坛” 在成都举行。论坛共分为“知识图谱与智慧医疗学术论坛”、“智慧医疗产业与市场论坛”和“行业专家座谈”三个环节,分别邀请了人工智能学术专家、临床医学专家、智慧医疗行业专家、投资机构及政府相关职能部门进行深入交流。
此次论坛从学术研究、政府政策和医疗产业多方面着重探讨了知识图谱和人工智能在医疗领域应用的构想、资源、技术、方案、策略以及待研究的问题和挑战,以此促成医学界、学术届和产业界之间的学术交流,探索未来在医疗领域大规模应用人工智能的合作模式。本文节选了本次论坛部分内容与大家进行分享。想了解论坛全部内容请点击阅读原文,或直接访问网址: http://www.msra.cn/zh-cn/research/healthcare/chengdu-healthcare-forum/
从精准医学大数据到智能医疗
在上午的“知识图谱与智慧医疗学术论坛”上,来自复旦大学生物医学研究院的刘雷教授带来了题为“从精准医学大数据到智能医疗”的主题演讲。

科学家们已经逐步发现,针对遗传学和基因的研究能够更好地指导我们的医疗发展:对不同个体使用不同药物和采取不同的治疗方法很可能产生不同的结果,那么,如何确保为每一个病人找到最优的治疗方案、针对病人的个性化特征来决定治疗方案?这些问题的答案很可能就写在每个人的基因里。
精准医学指的是基于大样本研究获得疾病分子机制的知识体系,依据组学数据和患者的个体特征,借助现代遗传学、分子影像学、生物信息学和临床医学等知识来实现疾病的精准预防、精准诊断和精准治疗,因人而异确定治疗方案和药物的用法用量,从而达到提高医疗的有效性、减少治疗方案副作用的目标 。刘雷教授以“美国精准医学计划”作为开场,介绍了国内外主要的“精准医学”研究方案。毫无疑问,精准医学集成了现代医学科技发展的知识与技术体系,体现了医学科学的发展趋势,也代表了临床实践的发展方向。

从上图可以看出,精准医学的实现主要分为四个阶段,目前每一阶段都还有很长的路要走。而针对目标3,知识图谱技术可以很好地解决精准医疗大数据的资源整合、存储、利用与共享平台建设,即疾病研究精准医学知识库构建。
建立知识库在精准医学研究中的重要性不言而喻,这恰恰也是现阶段研究热点所在。而在大数据的背景下,知识库的建立在技术上仍然面临多重难点。例如,如何将不同层次的知识(包括分子层面、药物、临床体征、疾病以及环境等这些不同层次)进行整合,或者是基础概念的整合,又或是概念之间关系的整合等。

作为总结,刘雷教授表示,如今我们看到计算机技术在医疗上的应用越来越广泛,而这背后始终坚持的是从数据到信息再到知识的“中心法则”,正因如此,计算机技术才能造福更多人。
知识挖掘对分级诊疗的智能辅助
在下午的智慧医疗产业与市场论坛环节,来自微软亚洲研究院数据挖掘与企业智能化组的研究员纪蕾与大家分享了“知识挖掘对分级诊疗的智能辅助”问题。相关内容在 《培养一个人类医生至少需要八年,那么人工智能呢?》中也有介绍。

目前,微软亚洲研究院已经与国内多家医院和医疗机构合作进行试点,基于微软提供的Azure云服务,为医生打造人工智能医生助手,帮助提高基层医生的工作能力、提升工作效率。现阶段,该项目由微软亚洲研究院提供算法和解决方案,对接医院需求,医生与研究员共同从事临床试验。研究员们为每个医生搭建了属于他们自己的人工智能医生助手,医生助手会以微信服务号等多种不同的形式协助医生,并且这一协助将贯穿在治疗前、治疗中和治疗后的整个就医体验中。

那么,这样一个人工智能的医生助手都能做些什么呢?其中包括知识库辅助学习(帮助基层医生培训)、知识库辅助问诊(辅助基层医生临床)、常识型问题自动回复和自动随访(包括人文关怀和异常提醒)等功能。

不久前,微软亚洲研究院数据挖掘与企业智能化组发布了 Microsoft Concept Graph和Microsoft Concept Tagging模型,力图从大数据中挖掘知识,用于帮助机器更好地理解人类交流并且进行语义计算。在这项研究的基础上,微软亚洲研究院的研究组利用知识挖掘的API针对医疗数据,包括海量的医学文献、匿名诊疗记录等进行数据挖掘,建立医疗知识库,使得不同的医疗问题都有对应的专业解答。与此同时,研究员们还针对互联网搜索数据建立了用户搜索意图的知识库。例如在病人提出“糖尿病不应该吃什么?”和“糖尿病的饮食”这类问题的时候,知识库能准确将这类问题映射到“糖尿病应遵循的饮食习惯”上来。通过结合医疗知识库和用户意图的知识库,两者可以互相学习、形成闭环。

在整个系统流程中,从知识库建立,到实体识别与链接和知识计算,虽然研究面临着诸多技术挑战,但研究员们仍希望,这样一套人工智能医生助手能够真正帮助医生提高效率、改善医患关系,让人们获得更好的诊疗体验。
知识图谱与智慧医疗
活动最后的“行业专家座谈”环节,由微软亚洲研究院数据挖掘与企业智能化组资深研究经理闫峻主持,四位嘉宾参与,嘉宾分别是武汉大学俞思伟教授、哈尔滨工业大学汤步洲教授、大数医达邓侃博士和万方数据程煜华博士,这些嘉宾从自己的专业背景出发分享了他们对知识图谱与智慧医疗的见解。

知识图谱是如何推动智慧医疗发展的呢?这背后有着算法层面、数据层面和应用层面的多重原因。从算法层面来说,深层神经网络技术不仅在图像和语音识别领域有着显著的帮助,用在自然语言处理等文本分析问题上也有同样让人欣喜的表现,因此基于深层神经网络技术的知识图谱在数据挖掘的质量上也有着不断的提高 。其次是数据,数据对知识图谱的构建至关重要,海量的数据能让知识图谱积累更多的知识,从而构建更完整的知识图谱。最后从应用层面来说,近年来随着人工智能技术的发展,聊天机器人(chatbot)这种人机交互方式日益普及,让研究者们看到了更多知识图谱应用的空间。只要拥有各种垂直领域的知识,聊天机器人就能更好地帮助人们完成某些具体的任务。因此,知识图谱与医疗垂直信息的结合,让人们有机会一窥智慧医疗的身影。
除了知识图谱本身,智慧医疗还有很大的发展空间,而计算机与医疗的结合,同样还有着丰富的无限可能。
智慧医疗狭义的定义是CDSS (clinical decision support systems),通过输入病情描述,包括症状和化验指标等,输出诊断结果。输出的诊断结果分为两个不同的阶段,首先是根据有限的结果给出可能的疾病判断,第二步是删选掉不太靠谱的疾病,进一步提高诊断准确性,从而解决下一步的路径的问题,例如还需要做什么化验和检查等。而从在线预约挂号,到智能分诊等种种就医过程的改善,则都可以被视为广义的智慧医疗——为人们提供更多更便捷的医疗服务。此外还涉及到医疗的信息化问题。因为即使到今天为止,医生也很难将自己看过的所有病人的记录进行整理。而对病人来说,也鲜有完整的从出生到现在的诊疗记录。由于这些信息上的局限,医生在科研方面也备受限制。从这些角度来讲,智慧医疗还有很长的路要走。知识图谱只是一小步,前面还有很多步等着计算机技术携手医疗一起前进。

↧
阿里巴巴向 Apache基金会捐赠移动开发框架Weex
12月15日,阿里巴巴宣布将移动开源项目 Weex 捐赠给 Apache 基金会开始孵化,Weex 有望成为中国移动领域的首个Apache顶级项目,这意味着中国移动技术开始反哺世界。据悉,这也是继JStorm、RocketMQ 之后,阿里向 Apache 捐赠的第三个项目。
![]()
2016 年 12 月 15 日,阿里巴巴宣布将移动开源项目 Weex 捐赠给 Apache 基金会开始孵化。
Weex 是阿里自研的高性能跨平台移动开发框架,最大的特点是解决了频繁发版和多端研发两大痛点,一套 Web 代码完美适配 iOS、Android、H5、Web 等多端,极大地解放开发者的同时又保证了用户体验。
去年双11的秘密武器 Weex,今年 6 月底正式开源,与全球开发者共享中国的移动互联网技术成果。除了轻量、高性能、可扩展、一次撰写多端运行等诸多优势,Weex 还提供了强大的调试工具协助开发者排查问题。
![]()
2016 年 6 月 30 日,阿里无线技术团队宣布 Weex 正式开源后兴奋地合影留念。
除阿里移动技术力量外,社区贡献者也踊跃参与,包括著名前端框架 Vue.js 创始人在内的多位技术大牛已经开始参与 Weex 的改进;众安保险、苏宁、优酷、饿了么等企业用户也在积极的接入之中。
“Weex 不仅应用灵活、性能强大,而且能让前端开发者最大程度复用现有技术积累,帮助我们用最少成本设计全新的跨平台架构体系,并尽快进入实施阶段。”众安保险技术总监陈天予反馈到:“Weex 积极拥抱 Web 标准,专注于 Native 渲染层优化的细致工作,也清晰地展示了这个项目的自身定位和发展方向。”
据悉,Weex 目前正在迁移整个开发环境到 Apache 研发基础设施, 阿里将会和 Apache 社区专家一起加快 Weex 的开发进度,并将采用更加严谨的版本发布策略。可以预见,未来会有更多来自全球的移动开发者从中受益。
来自: 手机淘宝技术团队MTT
感谢 mengyidan1988投递这篇资讯
已有 0人发表留言,猛击->> 这里<<-参与讨论
ITeye推荐


2016 年 12 月 15 日,阿里巴巴宣布将移动开源项目 Weex 捐赠给 Apache 基金会开始孵化。
Weex 是阿里自研的高性能跨平台移动开发框架,最大的特点是解决了频繁发版和多端研发两大痛点,一套 Web 代码完美适配 iOS、Android、H5、Web 等多端,极大地解放开发者的同时又保证了用户体验。
去年双11的秘密武器 Weex,今年 6 月底正式开源,与全球开发者共享中国的移动互联网技术成果。除了轻量、高性能、可扩展、一次撰写多端运行等诸多优势,Weex 还提供了强大的调试工具协助开发者排查问题。

2016 年 6 月 30 日,阿里无线技术团队宣布 Weex 正式开源后兴奋地合影留念。
除阿里移动技术力量外,社区贡献者也踊跃参与,包括著名前端框架 Vue.js 创始人在内的多位技术大牛已经开始参与 Weex 的改进;众安保险、苏宁、优酷、饿了么等企业用户也在积极的接入之中。
“Weex 不仅应用灵活、性能强大,而且能让前端开发者最大程度复用现有技术积累,帮助我们用最少成本设计全新的跨平台架构体系,并尽快进入实施阶段。”众安保险技术总监陈天予反馈到:“Weex 积极拥抱 Web 标准,专注于 Native 渲染层优化的细致工作,也清晰地展示了这个项目的自身定位和发展方向。”
据悉,Weex 目前正在迁移整个开发环境到 Apache 研发基础设施, 阿里将会和 Apache 社区专家一起加快 Weex 的开发进度,并将采用更加严谨的版本发布策略。可以预见,未来会有更多来自全球的移动开发者从中受益。
来自: 手机淘宝技术团队MTT
感谢 mengyidan1988投递这篇资讯
已有 0人发表留言,猛击->> 这里<<-参与讨论
ITeye推荐
↧
容器内应用日志收集方案
容器化应用日志收集挑战
应用日志的收集、分析和监控是日常运维工作重要的部分,妥善地处理应用日志收集往往是应用容器化重要的一个课题。
Docker处理日志的方法是通过docker engine捕捉每一个容器进程的STDOUT和STDERR,通过为contrainer制定不同log driver 来实现容器日志的收集,缺省json-file log driver是将容器的STDOUT/STDERR 输出保存在磁盘上,然后用户就能使用docker logs <container>来进行查询。
在部署一个传统的应用的时候,应用程序记录日志的方式通常记录到文件里, 一般(但不一定)会记录到/var/log目录下。应用容器化后,不同于以往将所有日志放在主机系统的统一位置,日志分散在很多不同容器的相互隔离的环境中。
如何收集应用写在容器内日志记录,有以下挑战:
1) 资源消耗
如果在每个容器运行一个日志收集进程, 比如logstatsh/fluentd 这类的日志工具,在主机容器密度高的时候,logstatsh/fluentd这类日志采集工具会消耗大量的系统资源。上面这种方法是最简单直观的,也是最消耗资源的。
2) 应用侵入
一些传统应用,特别是legacy 系统,写日志机制往往是没法配置和更改的,包括应用日志的格式,存放地址等等。日志采集机制,要尽量避免要求修改应用。
3) 日志来源识别
采用统一应用日志收集方案,日志分散在很多不同容器的相互隔离的环境中,需要解决日志的来源识别问题。
日志来源识别的功能借助了rancher平台为container_name的命名的规则特性,可以做到即使一个容器在运行过程中被调度到另外一台主机,也可以识别日志来源。
容器化应用日志收集方案
下面是我们设计的一个低资源资源消耗、无应用侵入、可以清楚识别日志来源的统一日志收集方案,该方案已经在睿云智合的客户有成功实施案例。

在该方案中,会在每个host 部署一个wise2c-logger,wise2C会listen docker engine的event,当有新容器创建和销毁时,会去判断是否有和日志相关的local volume 被创建或者销毁了,根据lables,wise2c-logger 会动态配置logstatsh的input、filter 和output,实现应用日志的收集和分发。
1) 应用如何配置
应用容器化时候,需要在为应用容器挂载一个专门写有日志的volume,为了区别该volume 和容器其它数据volume,我们把该volume 定义在容器中,通过volume_from 指令share 给应用容器,下面是一个例子:demo应用的docker-compose file

web-data 容器使用一个local volume,mount到/var/log目录(也可以是其它目录),在web-data中定义了几个标签, io.wise2c.logtype说明这个容器中包含了日志目录,标签里面的值elasticsearch、kafka可以用于指明log的output或者过滤条件等。
那么我们现在来看下wiselogger大致的工作流程:

监听新的日志容器->获取日志容器的type和本地目录->生成新的logstash配置:
1)wise2c-looger 侦听docker events 事件, 检查是否有一个日志容器创建或者被销毁;
2)当日志容器被创建后(通过container label 判断), inspect 容器的volume 在主机的path;
3)重新配置wise2c-logger 内置的logstatsh 的配置文件,设置新的input, filter 和output 规则。

这里是把wise2c-logger在rancher平台上做成catalog需要的docker-compose.yml的截图,大家可以配合上面的流程描述一起看一下。
优化
目前我们还在对Wise2C-logger 作进一步的优化:
1)收集容器的STDOUT/STDERR日志
特别是对default 使用json-file driver的容器,通过扫描容器主机的json-file 目录,实现容器STDIN/STDERR日志的收集。
2)更多的内置日志收集方案
目前内置缺省使用logstatsh 作日志的收集,和过滤和一些简单的转码逻辑。未来wise2C-logger 可以支持一些更轻量级的日志收集方案,比如fluentd、filebeat等。
Q & A
Q:有没有做过性能测试?我这边模块的日志吞吐量比较大。比如在多少量级的日志输出量基础上,主要为logger模块预留多少系统资源,保证其正常稳定工作?
A:没有做过很强的压力,但是我们现在正常使用倒没碰上过性能上的瓶颈。我们现在没有对logger做资源限制,但是能占用300~400M内存,因为有logstash的原因。
Q:「生成日志容器」是指每个应用容器要对应一个日志容器?这样资源消耗不会更大吗?k8s那种日志采集性能消耗会比这样每个应用容器对应一个日志容器高么?
A:是指每个应用容器对应一个日志容器。虽然每个应用有一个日志容器,但是,日志容器是start once的,不会占用运行时资源。
Q:你说的start once是什么意思?我说占资源是大量日志来的时候,那么多日志容器要消耗大量io的吧,CPU使用率会上升,不会影响应用容器使用CPU么?
A:不会,日志容器只生成一下,不会持续运行。
Q:怎么去监听local volume?
A:可以监听文件目录,也可以定时请求docker daemon。
Q:直接用syslog driver,能做到对应用无侵入么?
A:启动容器的时候 注明使用Syslog driver的参数即可,这样几乎没有额外资源占用。
Q:这种方案是不是要保证应用容器日志要输出到/var/log下啊?
A:不是,可以随意定义,logstah可以抓syslog。
Q:syslog driver能收集容器内的日志文件么?容器内不同流向的日志能区分么?
A:容器内应用的本地日志syslog可以收集,分流同样可以完成,但是容器内的本地日志这个我个人觉得跟容器环境下的应用无本地化、无状态化相悖吧。
Q:最后你说到,重新配置logstash中配置文件,看上去感觉你又是通过wiselog这个容器去采集所有日志的?只不过是动态配置logstash里面参数。
A:是的,现在收集工作是logstash来完成的,单纯的文件收集,可选的方案还挺多的,也没有必要再造轮子了。
Q:那这个方案其实有个疑问,为什么不学k8s那种,直接固定那目录,通过正则表达式去采集日志文件,而要动态这么做?有什么好处吗?目前我感觉这两套方案几乎一样。
A:为了减少对应用的侵入。因为很多用户的现有系统不能再修改了,这样做也是为了减少用户现有程序的修改,为了最重要的“兼容现有”。
Q:除了kibana还有没别的可视化方案?
A:针对es来说,还没有别的更好的方案。
Q:如果是挂载log目录,logstash就可以去宿主机收集了,还需要别的插件做什么?
A:通过容器可以识别出来这个应用的业务上的逻辑,可以拿到service名称。
Q:有的应用输出的log名都是一样的,不会有冲突吗,比如我启动2个容器在一个宿主机上,都往xx.log里写入会有问题。
A:不会,给每一个应用容器配一个日志卷容器就可以解决这个问题。这个问题也是我们出方案时一个棘手的问题。所以这个方案的一个好处就是,每一个应用的都可以随意设置日志目录,不用考虑和别的应用冲突,也不会和同宿主机同一应用冲突。
Q:上次听别人说全部把日志扔到标准输出里,不知道靠谱不?
A:有人报过这种处理方式,日志量大时,docker daemon会崩溃。
↧
↧
英语听力你为什么就是听不懂?

文/江北禾公子 图/网络
说到听力听不懂的话题,简直哀鸿遍野,很多人都叫苦不迭,甚至“谈听力而色变”。常常一段音频播下来,我们只能隐约听到几个简单的单词,基础稍微好一些的人能听懂音频的大概意思,但若说到像听母语一样通篇听清楚,可能大多数的英语学习者都无法企及。
可偏偏在诸多英语考试中,听力都占据很多的分值。如果大学英语四级考试的听力你可以通过类似“三短一长选最长,三长一短选最短”的“蒙答案攻略”来勉强及格,那么BEC、高级口译、雅思这些考试中如果你的听力不过关,基本上就满盘皆输了。
听力听不懂的原因有很多,总结起来无非是以下几点。
首先,你的词汇量太少。
音频播放的内容中有太多的词汇你都不明白是什么意思,又怎么可能听得懂呢?这是最为普遍,也最为基础的一个问题。
曾经我在听BBC的时候,一篇新闻播下来发现自己什么也没听明白,直到播放结束整个人都是蒙的。后来对照文本材料的时候发现,有太多陌生的单词。
我们从初一开始学习英语的时候老师就总是给我们强调: 如果把英语学习的过程比作打造一栋建筑物,那么单词就是一砖一瓦。其重要程度可见一斑,无论如何,想要学好英语,单词关都是一定要过的。
第二,耳朵没有受过训练,觉得语速太快。
很多英语学习者发现一篇听力听完了,语速快到脑子根本来不及反应,更别提抓住音频内容。很多人都以为这是“天赋”使然,但殊不知这是因为你的耳朵没有受到过系统的训练。
在过去的英语学习生涯中,我们会分析句子结构,懂得语法时态,知道某道选择题该选择哪个介词,可是我们很少开口说,也几乎没有什么机会听到原汁原味的英语。说白了,口耳用得太少,没有受过系统性训练,语速稍快一些便觉得脑子如云山雾罩。
第三,语言逻辑及文化差异等。
另外,还有一些其他的原因导致听不懂,例如不懂英语俚语,听不清弱读和连读,中外表达方式的不同以及没有养成英语思维等等。

图片发自简书App
既然知道原因,那么如何解决呢?
我们分析了很多听不懂英语的原因,但这绝不是给你的放弃寻找借口。绝不是让你觉得既然我单词量不够,既然我跟不上语速,既然我没有英语思维,那干脆放弃吧,英语的听力那么难。分析听不懂的原因,自然是要找到对应的方法使我们能够对英语听力驾轻就熟。
单词量不够这个问题很简单,扩充词汇量背单词就可以了。不管你是买来英语单词书背,还是通过大量的阅读来收纳学习陌生单词从而扩充单词量,又或者你在课余时间通过看美剧、听英文歌的方式来学习新单词,无论通过哪种方法,只要你在朝着这个目标努力就好。我的单词量来源是除了背单词书,还会用笔记本来收录一些阅读中遇到的陌生单词,以及一些听力中遇到的单词,在我大学四年的英语学习过程中,这样的笔记本有四本,里面标得密密麻麻。
关于语速太快,耳朵不能适应,那就磨练你的耳朵。先从简单的材料开始听起,坚持精听。VOA慢速英语、step by step 、新概念英语一,无论选用哪种练习材料,由慢变快,由浅入深,由易变难,循序渐进式练习,让耳朵渐渐适应听力的节奏,慢慢地你会发现你的大脑能迅速反应过来听到的内容是什么。
至于听不懂弱读、连读、俚语,没有很好的英语思维,那就涉猎尽可能广泛,业余时间看看美剧,听听英文歌,既能休闲娱乐,又可以提高英语学习的兴趣,了解欧美文化。如果有条件的话可以交一两个外籍朋友,现在网络上已经有一些中外交友网站了,可以在线和外国朋友一起聊天。英文歌也是很好的学习素材,同时也可以作为休闲娱乐的途径。大学时期我有一个外教老师,她很喜欢搜集各种英文歌,把歌词变成填空题让我们边听边填空,那真是我的英语学习生涯中最感兴趣的事。即便是后来大学毕业了,我在听英文歌曲的时候,也喜欢设想自己在做填空题。
不管听不懂的原因有多么复杂,都能通过大量的持之以恒的练习来有效解决。在这个过程中,你只需要做好一件事,那就是坚持听,运用正确的方法坚持去听,去训练自己的耳朵,慢慢地你会发现自己的进步是惊人的。
END
更多精彩请关注“江北禾公子”
Hi,我是禾公子,爱好写作的理想主义者,外表沉静内心住着追风少年。喜欢我的文章请点赞(。ò ∀ ó。),互撩请点关注,壕请任意打赏,么么哒~(^з^)-
↧
卧底炒股工厂90天,揭秘“超超短线”交易内幕
- 卧底炒股工厂90天,揭秘“超超短线”交易内幕
- 2016-12-16 13:56文 /南方周末已阅 25093
三个月前,深圳前海大概率资产管理有限公司交易员王明接受了一项特殊的任务——去佛山一家炒股工厂卧底。
大概率资产管理着数亿元的阳光私募基金产品。对于市场上逐渐流行的T+0工厂交易模式及“稳赚不赔”的口号,大概率资产总经理杨济源感到很惊诧,他决定让王明去找一家T+0工厂卧底。
中国A股实行的是T+1交易制度,即当日买进的股票,要到下一个交易日才能卖出。国际上流行的T+0交易制度,是指当日买进的股票可以当日卖出。
T+0交易在2015年股灾之前曾一度非常流行。当时,根据交易所规则,融资融券业务可进行当天融券还券,交易者可以直接从券商融到券,从而在账户中开展T+0交易,当天再把融到的券归还。
2015年8月,交易所发布通知,修改融资融券交易实施细则,将融券由原先的T+0改为T+1,禁止当天融券还券,交易者借到的证券必须在T+1才可以偿还,这堵死了利用融资融券进行T+0的生意。
然而,2016年以来大盘持续低迷,网下打新热度高涨,这又让T+0工厂重新焕发生机。按照交易所规则,投资者在网下参与打新股必须持有1000万元之上的股票市值,这使得许多打新基金或者大散户买入并长期持有某些风险低的股票作为打新底仓,T+0工厂得以帮这些客户打理底仓股票保值增值。
1.“打怪”工厂
2016年9月底,王明在女朋友的介绍下来到佛山一家T+0工厂应聘,他女朋友在当地某家证券公司营业部工作。
这家公司的办公室位于佛山一座新开发的办公楼里,足有两百多平米空间,摆着二十多张办公桌。每个桌子上都竖立五六台电脑,屏幕后面坐着的大多是头发蓬松的20岁左右的年轻人,也有家庭妇女模样的人。办公室里,呼喊声不时响起,就像打网络游戏的战队队员们,在喊着口号一起打怪。
虽然做的是股票买卖,但这家工厂的交易模式是雇佣大量交易员操作的日内回转交易,因此也被市场称为T+0工厂。
王明被带到一个隔间中,等待公司领导的面试。不一会,领导走进来,指示应聘者们坐到电脑前,限定一分钟时间,用电脑小键盘输入数字,结束后上报结果。作为电游高手的王明的成绩为153,而坐在他旁边的年轻小伙成绩竟然高达两百多。
领导坐下来与王明单独谈话,问他是否打电脑游戏。为了赢得这个工作机会,王明有意介绍了自己过去的股票投资经历,没想到领导却流露几分不满说,“你最好把你以前的交易经验都抛掉,公司会给新员工做培训,我们的模式是稳赚不赔的。”
在后来的交往中王明发现,这个二十多岁的领导,每天收盘都会仔细查看员工们当天的交易记录,一旦哪位员工出现交易错误,就会被严厉批评,并且被要求写书面的总结。对于员工们提出的业务问题,这位领导也毫不吝惜时间予以解答。
相比王明见过的其他私募基金负责人,这位领导几乎从不提起宏观经济趋势、行业景气度、股票估值这类名词,挂在嘴边的更多是“正T”、“反T”、“勾头”、“龙一龙二”、“一波牛”、“八十度角下跌”等土里土气的术语。
领导周围的座位中,是交易团队的核心,其中几个同事能得到更多的关照,他们被分配到更大额度的账户,被允许进行交易的股票数量也更多。王明后来才慢慢知道,中年妇女样子的人是领导的姐姐,旁边的中年男人是其姐夫,其他的也都是亲戚。领导就是本地人,以前没有正式职业,经常混迹于网吧中打游戏。
王明被安排坐在角落的位置里,紧邻着公司里唯一的女员工。她手速也能达到150左右,在第一个月的培训中,用模拟账户进行交易的成绩名列前茅。但是,在此后的实盘交易中,她的成绩排名却一落千丈,远比不上同期进入的王明。每天下班后,她与同事们一样各自早早回家,因为这个工作完全没有底薪,唯一的报酬只有交易股票赚取的业绩提成,以她的业绩,每月的收入才几百块钱。在年景最好的2015年,有的交易员年收入可以达到200万元。
2.超超短线”交易秘籍
一个月的培训和模拟后,T+0工厂将账户分给员工们进行交易,账户总额的90%是股票,10%是现金,显示着10只左右股票,股数各不相同。王明被分配到的账户总市值为20万元左右,有2万元左右的现金,其余是700股新华保险、2000股中国中车、4000股广汇能源等,每只股票的市值都在2万-3万元。
交易员们的任务是,通过频繁交易,在收盘的时候,保证账户里的股票数量不变、现金增加,T+0工厂根据增加的现金给交易员们分配业绩提成。
基本的原理是,交易员在股价低的时候用账户内的现金买入一定数量的某只股票,在这只股票价格上涨之后,再卖出同样数量的这只股票,这样,就能保证收盘时账户里股票数量不变而现金增加。反向交易也是同样原理,在股票价格高的时候先卖出一定数量股票,当股票价格下跌之后,再买回同样数量的股票。由于账户中原来就持有特定的股票,因此在这些股票上,就可以实现日内回转交易,这就是T+0交易的精髓。
王明记得最成功的交易是在11月21日交易新华保险。
11月21日,一开盘,保险股开始集体猛涨,“龙一彪啦”、“龙二彪啦”,交易员们吆喝着互相提醒。王明桌子上的5台电脑屏幕,其中一台就是显示着中国人寿的分时走势图,这就是龙一,龙二就是新华保险。
几秒钟之间,王明就迅速完成了交易,所有现金买入新华保险,9:30到9:42,短短十几分钟的时间里,新华保险几乎以竖直的角度拉升,涨幅从开盘不到1%迅速蹿升到6.96%,而就在9:42的分时线上 第一个技术“勾头”出现的时候,王明迅速卖出相同数量的股票。这一笔交易,王明赚到了超过6个百分点,在很短的时间内,几乎吃到了这一波的所有涨幅。
周围的交易员收益都在4个百分点之上。
这是T+0工厂在此前培训中教授的三大战法之一,此前1个月里王明们反复训练并熟练掌握。
三大战法的名字让王明印象深刻:
突破买进一波牛法,看龙一买龙二法,杀跌抄底法。突破买进就是在股价突然上涨拉升的时候及时买入,仅赚一波上涨,当分时线上显示出拐点的“勾头”时,立刻卖出。
第二招就是利用板块联动的原理,当一个板块龙头启动时,就及时买入手中拥有的板块个股。
第三招就是抄底的策略,当某只股票在分时图上出现70-80度角的急速下跌,跌幅超过2个百分点,当感觉跌速放慢或者跌不动的时候,及时买入,反弹上升的图线出现第一个“勾头”的时候,立刻卖掉。
11月11日上午10:08,中国中车的股价突然拉升,王明眼疾手快迅速买入,仅仅3分钟的时间里,涨幅从0.67%扩大到2%;10:11,“勾头”出现,王明立刻卖出。
同样是在11月11日,在交易东兴证券时,王明用上了第二招。当天下午刚刚开盘,证券板块突然拉升,“龙一”方正证券在10分钟之内涨幅就已经超过8.59%,王明迅速买入“龙二”东兴证券,并在涨幅达到4.11%时及时卖出。
在11月3日乐视网的交易中,王明用上了第三招。此前一天乐视网已经经历超过7个点的下跌,在这一天10:30-10:40的10分钟内,乐视网的股价急速下挫,跌幅超过3.3%,王明就在这个时候买入股票,乐视网股价随后反弹,11:18,股价反弹近2个百分点,王明卖出股票。
每天的14:30之后,公司也允许交易员们个人发挥,做一些反T或者卖空交易,也就是把这三种招式反过来用在做空上,先卖出股票,等股价下跌了再买回来。王明听说在2016年初熔断的时候,很多T+0工厂交易员利用做空赚了很多钱。
王明使用的交易软件是T+0工厂专门定制的,当交易员的账户出现1%的损失时,该账户就会被强制止损,交易员会被停止交易,之后静默一天,写总结。因此,交易员们在交易过程中神经高度紧绷,一旦判断失误,股票出现2-3分钱亏损,就立刻止损卖出,王明也曾听到过公司规定,如果造成亏损,要求交易员自己交罚款弥补,但并没有见过哪个交易员真正被处罚。交易员们的原则是,没机会就不交易,就不会造成亏损,尽量在有把握时才交易。
“现在A股的交易已经进入微生物领域了,这种超超短线在几十秒内解决战斗,”大概率资产总经理杨济源对南方周末说,“此前理解最短的短线,无非也是尾盘买入,下一个交易日开盘卖出。”
3.产业链
根据与T+0工厂之间的约定,王明的工作没有底薪,但是可以获得管理账户盈利部分的20%作为酬劳,而T+0工厂一般跟客户约定,盈利部分的50%给予客户,这样工厂就可以获得其余30%的盈利。
王明所在团队核心成员,有些管理的账户资产能达到1000万元,而工厂模式平均月盈利率在3%左右,则总的盈利能够达到30万,给客户分红15万,给交易员业绩提成6万元,其余9万则是工厂的盈利。
像王明这种新进入工厂的员工能够被分配到20万左右的账户,做了1年以上的交易员能被分到500万元之上的账户。
T+0工厂的生产最离不开的生产资料就是股票、资金。除了操盘团队的办公室,王明还去过T+0工厂业务团队的办公室,在那里, 销售人员们根据从证券公司营业部等渠道拿到的股票大户名单,逐个联系,推销说可以代客理财,帮助客户在不改变被套住股票数量的情况下,实现账户盈利,承诺保本,并且利润当天结算。
“营业部肯定喜欢,因为可以增加交易佣金,我们公司也收到过销售电话,问我们愿不愿意把被套的股票借给他们做T+0,他们支付利息和费用。”大概率资产总经理杨济源对南方周末说。
“为了把限售股拿出来赚取利润,华东地区某上市公司大股东曾想找T+0工厂合作,走访考察了一圈之后,最后自己开办了一家T+0工厂。”王明说。
除此之外,T+0工厂另一个不可获取的生产资料是软件系统。王明所在的T+0工厂是与杭州某T+0工厂合资成立,从杭州方面获得的软件及技术,那边的创始人团队是做美股出身。 这种定制软件可以把不同客户账户中的股票和现金整合起来,切割成不同的小账户,分配给交易员,从王明使用的交易端无法看到客户账户情况,还具备亏1%止损的功能。
正是凭借这种软件,T+0工厂才能实现为不同客户、不同来源的股票进行工厂化交易。
12月1日中国联通涨停,但是,王明和同事们在当天的交易中却基本没有赚到钱,因为这次的涨停过程中,出现了许多“勾头”,这让王明的招式失效了。另外,王明发现最近离开T+0工厂的人越来越多,盈利率在下降,因此为了保证核心成员能够赚到足够的钱,只有裁掉一些人员,把账户向某些人集中,提高他们的管理规模。
2016年12月,当王明完成卧底任务,回到深圳前海大概率资产管理有限公司重新担任交易员时,与他一批进入T+0工厂的员工大部分已经被淘汰或自动离职,新的一批人正在接受培训。
证监会也开始打击T+0工厂的生意。2016年10月,证监会发布《机构监管情况通报》指出,部分机构与个人违规提供“股票回转交易”服务,涉嫌非法开展证券活动。此后,证监会协调相关部门启动“打非”程序,排查相关嫌疑证券账户。
《通报》同时公布,根据线索,证监会机构部安排上海、广东、湖南、四川等地证监局进行了专项核查,发现上海地区个别机构存在回转交易情形。而据媒体报道,总部位于北京的中央汇金旗下的一家老牌券商,这类业务开展的规模最大,在客户和T+0工厂之间中介联络,坐收佣金提成。T+0工厂及违规的营业部在北京、上海、广州等多地广泛存在。(文中王明为化名)
财联社声明:文章内容仅供参考,不构成投资建议。投资者据此操作,风险自担。
![]()
- 分享到:
![]()
- 2016-12-16 18:54
- 小石头券商
- 为什么不玩期货
分享你的评论?请先 登录。


↧
利用消息推送提高APP留存率的四个步骤
如何提高用户留存率,是app运营人员苦思冥想的重点难题之一,蝉大师发现许多的开发者团队,APP运营团队,在为自己每天的‘新增用户’数量而深感自豪时,却苦恼的发现,这所有的新增用户中,只有很小一部分坚持到了90天。

有这样一位开发者,第一天,他的新增用户留存率是21%,但这一数字在第90天后,下降到1.89%。差的留存率意味着我们辛苦获得的用户只提供了短期的APP用户数量的增长,最后人都走了,就别提什么长期价值了。
当留存率过低时,高质量的消息推送是提高留存率的措施之一,通过本文,你可以了解到:
1、如何提高用户选择允许启用推送消息的机率
2、发送推送通知,可以将留存率提高20%。
3、吸引68%的第一周用户,即使处于休眠状态。
4、个性化推送通知,享受高7倍的保留率。
下面,你准备好了吗? 让我们一起来看看利用消息推送增加留存率的四个步骤吧。
一、在请求获取推送权限之前要注意什么
我们知道APP推送通知可以提高留存率,但是呢,在用户还没有选择允许我们向他推送消息之前,这个功能是没作用的。实事求是的说,只有42%的ios用户选择允许APP向他推送通知。因此,如果我们想利用消息推送来提高留存率的话,那么首先是要想办法提高用户的选择允许的机率。
在请求获取推送权限之前要注意的是, 默认情况下,iOS会在用户启动新应用程序时向用户提供一系列系统提示。 这些提示包括APP需要访问用户的位置,联系人列表等等权限。这时候,如果用户不知道这款新下载的APP对他有什么具体价值的话,那么他们会拒绝这些请求,哪怕其中一些请求对用户而言是有意义的,如推送通知。
所以在这种情况下,您的推送请求会在这些其他权限请求中非常的容易丢失,如果用户反复点击“不允许”,我们将永远失去这个机会。

如果我们选择在用户注册帐号或解锁游戏后,再请求获取推送权限呢?这个时候我们的应用已经初步向用户证明了价值,相信可以使用户更容易接受推送通知的请求,如果有可能的话,可以通过应用内消息发送解释关于消息推送的信息,而不是通过的系统提示,这样的效果会更好。只不过现在国内许多的APP都没有这个功能。
二、发送有价值的推送消息
推送通知是与用户互动的有效方式之一,从长期来看,一款发送推送知的应用都不会有太差的留存率。可是应该发送什么类型的推送通知?这是最棘手的一部分,不当的消息推送有可能会导致用户卸载APP,所以我们应该尽可能的发送有价值的邮件。
这里有几个建议:
1、购物类app,提醒用户他们经常浏览的类别中有哪些打折的商品。
2、旅行类app,通知用户旅行的最后一分钟的事件变更情况,例如航班延误。
3、音乐类app,通知用户他们最喜欢的歌手刚刚发布了一个新专辑。
这些消息的关键是他们创造价值而不是惹恼收件人,惹恼用户的代价是巨大的,谁也不希望因为给用户发了一个推送消息而导致被卸载吧?
三、使休眠用户接受相关消息
如果第一周您的app只有10%的用户在使用,打开率虽然这么低,但并不意味着其它90%的用户卸载了应用程序。这些大部分用户只是休眠。他们可能似乎对您的应用程序不感兴趣,但如果您充分吸引他们,向他们展示您的产品的价值的话,事情有可能向好的方面发展。(此饼图提供了一个有用的可视化)

直到您的休眠用户卸载您的应用程序之前,您仍然有机会赢回他们。 不夸张的说,使用推送通知可以重新激活超过三分之二的用户群。
推送通知的内容应遵循这几点:有帮助,个性化,不要垃圾。
这里的区别是时间,这是至关重要的,如果你的app,用户仍然觉得有新鲜感,那么我们要做的只不过是,找一个恰当的时间利用消息推送,去说服或者说是去证明app的价值。
四、个性化您的推送通知的内容
一般来说,个性化推送比通用推送更有价值。个性化内容可以包括从基于用户的浏览历史的推荐项目到从互联网提取的本地天气数据的任何内容。上文中其实蝉大师aso优化平台已经提到了相关个性化通知的内容,比如A喜欢张某的歌,我们可以向A推送张某的新专辑;比如B喜欢李某的歌,我们可以用B推送关于李某新专辑的消息。而这些,都是通过简单的用户浏览历史便可以获取到的信息。
如何个性化您的发送时间?
这要求开发者或者说APP运营要深入的分析用户的使用习惯,选择用户在最有可能打开应用的时间点推送消息,但个性化的高低水平有时候并不能手动实现,不停的AB测试是通用方法,国外的这方面是借助智能算法。

通过上文我们可以了解到正确的APP消息推送对于APP的打开率、留存率都是非常的重要的。这四个实用步骤希望可以帮到大家,其中如果你在发出推送通知选择接受请求之前主导用户的话,那么我们将更容易提高用户的选择‘允许推送’的机率。
本文由ASO蝉大师https://www.chandashi.com/原创,如需转载,请注明出处,否则禁止转载!
↧
过于在意别人想法,如何克服?
过于在意别人想法,如何克服?
这一点一直令我很苦恼,我也一直想极力摆脱。但到后来不管怎么尝试却都只令我变得愈发敏感,愈发的在意别人。
通过不断地摸索,直到两年前我才彻底的摆脱了别人对我的看法的影响,我成为了一个无条件地接纳自我,不会被任何的评判与对比影响的活的很轻松的人。
在这里,我将我的经验分享给你。全文一共八千多字,我相信看完这篇文章后,你就能够放下对于别人看法的在意了。

在我很小的时候,我的父母总会以一些很严苛的标准来要求我,他们总是告诉我:你还不够好,你还不够优秀。
他们也很少会夸赞我,给予我正面的评价,总是会拿我和别人家的孩子作对比。
这就造成了我从小以来一直都是: 以别人的评判标准来看待自己,试图去满足别人的期待。
别人对我的赞同或否定都会对我的情绪造成很大的影响。
不知道、也不会去表达自己的需求。
在某种程度上,我还会有一些讨好别人的倾向。
后来踏入咨询行业,接触了很多也是被过于在意别人的看法而困扰的来访者,我发现几乎是所有的这类人都有一个共同点: 童年时总是被父母或抚养者要求成为他们所期待的人。
这一点是导致我们总是会过度在意别人看法的根本原因。
我们和父母的相处模式几乎是造就我们未来的一切认知、行为模式的模板。但也要意识到,这是也只是一个模板而已,在我们今后的成长过程中,我们和别人的相处与互动,令我们的这些认知和行为获得了反馈和强化,由此,「在意别人的看法」才真正内化为我们的一个「基本习惯」与「核心信念」。
随着心理学的发展与迅速普及,许多心理学的概念被大众所熟知,而很多概念在传播过程中不可避免的被夸大和绝对了。「原生家庭」这个词就是其中之一。
人类的归因倾向就是习惯于在根源处寻找答案,所以「原生家庭」这个词就几乎成了公认的心理病症的根本原因。
但实际上我们必须意识到,童年经历只是导致我们的问题的一个「触发因素」而不是全部的原因,事实上在我们成长过程中对于我们童年行为与认知模式的强化和重复才是导致我们问题的主要因素。
「在小的时候会被父母要求成为他们所期待的人」,有这样童年经历的人并不在少数,但还是有很多人虽然有这样的经历,却并没有在长大后成为像你我一样会过度在意别人看法的人。
这说明了什么?
这说明了原生家庭的确令我们在一开始产生了这些问题,但在成长的过程中我们完全是有机会、也能够摆脱我们的这种认知模式的。
比如说你拥有了一群接纳你的伙伴、你在学校里成绩很好不断地从别人那里获得正反馈就形成了「无条件自尊」、你力气很大你们班的同学都很怕你等等,这些都是有可能改变我们的认知模式的外因。
另一方面,即使你已经清清楚楚、完完整整的知道了你童年时和你父母的相处方式,你明确的了解了你父母对你的哪些做法令你变得这样在意别人的看法。
但是然后呢?
然后如果你想彻底改变这个问题,还是要从你「现在」的认知与行为模式入手,只有把你的认知与行为习惯改变了,问题才能够解决。
并且,甚至是我们只需要把你的认知行为习惯改变了,即便我们不知道原因,那你照旧能够完全摆脱这个问题对你的困扰。
所以说了这么多是要你理解什么呢?
是要你理解, 不要把所有的问题都归结于过去,归结于原生家庭,原生家庭是导致你现在问题的触发因素,但也只是一个触发因素,仅此而已。
有非常多的人会把所有的问题都推给原生家庭,并非常悲痛的说:我真的没有办法放下,我真的很痛苦,我好难过。都是过去的错。
把问题完全归结于原生家庭的唯一好处就是,你可以说所有的错误都是父母造成的,这样你就能继续逃避自己的责任和你应该去面对的问题,这样你就能变得很“轻松”了。
我们必须意识到,去追究是谁的错、追究什么原因,这对我们的问题的解决,并没有任何的用处。
我们要做的只是针对问题,寻找解决办法,然后做出改变,问题就解决了。
如果你只会痛苦的哭诉“我好难过”而什么都不做,这才是导致你不断地被问题影响的根本原因。
在明确了唯有付出行动才能解决问题这个前提之后,我们来看一看导致你过度在意别人看法的「直接原因」。这些直接原因是我们解决问题的关键。
- 过度在意别人看法的一个最重要的直接原因是:害怕得罪别人。
毋庸置疑,这是任何一个会过度在意别人看法的人的潜意识里都有的一个核心信念。
你害怕和别人起冲突,你害怕别人对你发火,你害怕别人冷落你,你害怕别人对你使用暴力,你害怕别人抛弃你。
而这一切害怕的本质,都是对于「死亡危险」的恐惧。
这种恐惧来自于我们问题的触发因素:父母要求我们成为他们期待的人。在童年时期,父母是我们能够生存下去的唯一保障,得不到父母的认可,无法满足父母的期待,这就意味着我们有被他们抛弃的风险。而对于儿童来说,被父母抛弃,就意味着死亡。
对于这种死亡风险的恐惧促使着我们不得不去试图满足父母的期待。
2. 自卑。
导致自卑的原因是多种多样的。自卑的人基本都会过度的在意别人对自己的看法。所以自卑和过度在意别人的看法这两者是一个交叉作用的关系。
3. 敏感
敏感意味着一个人的心理承受能力差,容易受伤,容易多想。
4. 将自己与别人对比。
只要你将自己和别人对比,就必然会对你造成伤害。
「不停地令自己变强,不停的令自己变得更完美,从而能在将自己与别人对比的时候胜过对方」是无法解决这个问题的。
不管你变得多强大,不管你变得多好,这个世界上绝对还是会存在着比你更好的人。这也就意味着你总会有不如人的地方,你总是会受到挫败。
所以最根本的是,一开始就要意识到你根本没有丝毫拿自己与别人比较的必要性,放弃了对比,也就没有了痛苦。
5. 不能接纳自我。
人的自尊有三种模式。
一种是「依赖性自尊」,即依靠别人的评判标准来看待自己。在得到别人的赞美与认同时会非常的开心,在被别人否定和拒绝时会嫉妒的难过。
会「过度在意别人的看法」的人就是属于「依赖性自尊」。
第二种是「独立性自尊」,即不再依靠外在的评判标准和他人的目光来看待自己,而是完全的遵照自己的标准和要求来看待自己。
但独立性自尊的人在有些时候也会因给自己制定了太高的标准而产生挫败。
第三种是「无条件自尊」,即不需要任何理由,不需要任何评判标准,不需要任何的条件,我完全的尊重和接纳自己。
只有这种自尊,才是真正的自尊。
有条件的自尊本质上只是在玩「找到一个标准,满足这个标准」从而自我安慰的把戏罢了。
所以当一个不能够接纳他自己的时候,他的内心就是空洞无物的,他无法从自身内部获得支撑,而不得不从外界寻求认同和力量。
6. 试图成为别人。
人都有一个理想自我,理想自我与现实自我之间的差距,是导致非常多的神经症问题产生的根本原因。
不论是我们的文化还是父母和长辈的教诲,都是在教我们成为一个“别人”,从来没有人告诉过我们:做你自己就好。
试图去成为“别人”,试图变得“更好”“更完美”“更有钱”“和更多的异性发生关系”这些是驱使很多人存活着的动力,但这些本质上只不过是满足了你的一种虚假的幻想而已。
对于绝大多数人而言,他们终其一生都活在这种幻想里,他们一辈子都是在为了外界的评判标准而活,他们为了成为“别人”而浪费了属于他们“自己”的一生。
以上这六个直接原因,只要你能彻底将其中的一个问题解决,那么你基本上就能够不再去在意别人对你的看法了。
但在无人指导的情况下,你想解决自己的问题其实是非常难的。你没有目标,也没有方法。你可能也没有执行力,很难坚持下去。
在这里,我将我这些年所有的经验和思考全部分享出来,我会从所有的角度全方位的帮你建立起一个自信,自尊,自爱的核心信念,如果你能够将以下这些信念内化,那么你不需要做很多就能够逐渐的改变自己的问题。
你所需要做的,是将以下的这部分内容每天晚上看一遍,直到你彻底理解为止。
而等你理解了,问题自然而然的也就解决了。
1. 别人没那么在乎你,也没那么关心你。
虽然在文字的表述上是“太过在意别人的看法”,其实这本质上指的是“过度的自我关注”。
也就是说问题的实质根本不在于别人怎么看你,而是你自己将别人对你的看法看的太重要,将别人对你的看法所导致的后果看的太重要。
实际上你必须清楚地意识到这一点:并没有多少人在关注你,也并没有多少人对你有什么“看法”。
你想一想,你对别人又有多少的看法呢?即便是你对某个人有些看法,但这个看法又能持续多久?那么你的看法又会对别人造成什么影响?
你对别人的看法根本就没有什么实质性的影响,假如说产生了什么影响,那根本的原因也是因为那个人“在意”你的想法,所以他才会有所应对。
反过来在你身上也是同理,别人对你的看法这本身就是一种「非实质性」的影响。
所以你看:你因为害怕别人别人对你的看法所造成的影响——所以你才会在意别人对你的看法。
而如果你不在意别人对你的看法——那么别人对你的看法就不会对你造成什么影响。
你明白了?
看法始终只是看法而已。
而如果你说:那别人骂我是傻X怎么办?别人欺负我怎么办?别人排挤我怎么办?
那这就是关乎你“懦弱”的问题了,当别人对你产生「实质伤害」的时候,这就已经不再是「别人对你的看法」的问题范畴内,你要做的是捍卫自己的权利,去反抗欺负你的人,或者在的确是你很傻X的时候改掉你的那些愚蠢的做法。
我们要知道: 太过在意别人的看法的对立面是「不在意别人的看法」,而不是「彻底的、绝对的、完全拒绝别人的看法」。
不在意只是意味着你不会被别人的看法影响,也不会被别人的看法伤害。但你仍然会正视,面对,并且接受别人对你的看法。
假如说是因为你在宿舍随地大小便这种过度的行为而导致了别人对你的不满,那么你要做的是修正自己的行为而不是无视别人的看法。
所以一个重要的前提是,你要能够在客观的层面上分清楚你的行为是否对别人造成了伤害或者影响,如果不违背法律和最基本的道德,也没有伤害或影响到他人,那么你才可以完全无视别人的看法。
2. 对于你而言,在这个世上你自己才是最重要的。别人和别人的看法,都不重要。
每一次当我告诉我的来访者们“他们自己才是最重要的”时,几乎无一例外他们都会回答我:“这样也太自私了吧?”“可是我父母生养我很不容易啊!”“那她是我最好的朋友哎!”“可是我真的很爱我的男朋友啊!”
每当我听到这样的回答时,我都会忍不住在心底心疼这些人一把,看看「社会意识」已经把这些人伤害到什么地步了,他们竟然完全没有自爱自尊的意识。
在我们的社会环境中,始终在强调集体主义,强调助人为乐,强调要为别人考虑,我们将为自己的立场考虑、表达和满足自己的需求定义为自私,并且整个社会都在或明或暗的对“自私”持批判性的态度。
这就和为什么太懂事的孩子长大了往往不幸福的原因是一样的,一个人如果没有勇敢的、坦然的满足自己的“自私”的心态,而只会一味的照顾和满足别人的感受,那他将永远不可能获得幸福。
因为快乐的本质就是对自身欲望和需求的满足,你必须将自己的需求放在首位,你的整个人生基调才可能是幸福的。
如果你时刻想着别人,时刻去迎合与满足别人,你的需求和欲望就会被长期的压抑,久而久之,你就会忘了自己究竟想要什么,忘了自己喜欢什么,这个时候的你,本质上就和行尸走肉并无二异了。
无论任何一个人,他活在这世上首先是为了他自己。你这一生会不断地遇到许多人,会有无数的人随意的向你发表他们对你的看法。他们对你的看法重要吗?
事实上一点儿都不重要,现在你身边的绝大多数人都可能会在三年、五年后消失,对于你而言,这些人只不过是你生命中的一些过客而已,所以你有什么必要去奉承和讨好这些对于你一点儿都不重要的人?你有什么必要去在意这些过客们的看法呢?
你这时候可能会想:但我的好朋友/我的老公她们会陪我一辈子的啊,他们对于我而言是很重要的人呀!
没有错,这些人的确对你很重要,但重要和你要牺牲自己去迎合别人之间没有丝毫的关联。
这个人对于你很重要,但你没有必要“丧失自尊”的去迎合他。
更何况你也清楚,你和这些“重要”的人也许要共同陪伴一辈子呢,难道你愿意一辈子都在委屈自己去迎合他人吗?
从最根本的层面上来讲,别人根本一点儿都不重要,你活着本身就是为了你自己。如果你不能够为了自己而活,那么你这一生就相当于是枉过一生而已。只有为了你自己而活的生命,才是真正有意义的。
我可以告诉你的是:你完全有权利自私,你也天经地义的应该把自己放在首位。如果你选择尊重自己,不过度在意别人,你会活得轻松快乐很多;
如果你继续去迎合别人,继续去在别人面前“表演”,继续去试图成为一个别人所期待的人,你就会继续现在的这种痛苦。
你是要轻松地自私着,还是要痛苦的迎合着呢?
3. 把你自己的需求放在第一位。不要委屈自己成全别人。
有太多太多的人不会、也不敢表达自己的需求,而这一点是非常普遍的造成许多人非常痛苦的原因。
他们会在无比愤怒的时候面对着伤害他们的人却无法骂出哪怕一句脏话,无法攻击对方哪怕一下,无法表露出哪怕一丁点儿带有攻击性的情绪。
他们仿佛天生就被训练的会去理解别人的立场,会去照顾别人的感受,会去满足别人的需求。
但是你想一想,又有谁理解了你的立场,谁照顾了你的感受,谁满足了你的需求呢?
你并没有任何的必要,也并没有任何外界的压力和束缚在令你不得不在意别人的想法和感受啊。
你说但是社会潜移默化的有很多规则,有别人会评判你。
问题是这些规则和评判对于别人而言也是一样存在的,为什么别的人就不会这么在意这些社会规则和别人的眼光呢?
归根结底还是在于你给自己套上了枷锁,你给了自己太多了限制,你不敢去迈出那一步,你把别人的眼光和评价看的太过重要了。
只需要尝试一次,只需要尝试一下不去在意那别人的看法,只需要尝试着满足一次你自己的需求,只需要一次,当别人惹恼了你的时候你骂出一句“你给我滚”,只需要一次,当你父母要求你满足他们的期待时你坚定的告诉他们:我自己的未来我自己做主。
只需要这一次,你试试看,自己会不会死,天会不会塌下来,你所幻想的那些恐怖究竟存不存在。
或者即便是你朋友愣住也和你生气了,你父母恨铁不成钢的说你太不懂事。
那又怎样呢?
所以为什么就不能够和他们争吵?为什么就不能坚持你自己的想法?为什么一旦别人反对你你就马上按照别人说的去做呢?
如果你因为“我说了他们不让啊”“可是他们不理解我”“我说不过他们”这种理由而不能坚持自己的做法,我只能说你的一切痛苦,完全是你自己在自作自受。
你自己的决定,别人让或者不让,别人理解或者不理解,别人说的多么有理,这和你有什么关系?
我问你,别人不让你吃好吃的,别人不让你去做你想做的工作,别人不让你和别人起冲突,凭什么?
别人有什么资格控制你?
或者说,你为什么要按照别人对你的要求去做事情?
他不让就让他不让去,他不理解就不理解呗,他说的有理就让他有理,他不接受就让他不接受。
你自己的决定,关别人屁事?
4. 不要害怕得罪别人。
我知道看到这里很多人会担心:但我要是真得罪了别人,那怎么办?
你要意识到: 不害怕得罪别人不意味着你要刻意去得罪别人啊。不害怕只是说即便发生了冲突,你也会去面对这个冲突,即便别人不开心,那就让他不开心去。而不是刻意找茬,刻意去得罪别人。
对于现在的你而言,你会因为害怕得罪别人而刻意小心翼翼的去注意自己的言行举止,会为了和别人不起冲突而压抑自己,会为了不让别人对你产生不好的看法而去为别人的错误负责。
而不害怕只是让你放松下来,让你回到正常人的程度,不会故意惹事,但如果出现了冲突,就要就事论事,是你的错误,你承担;不是你的错误,就绝对不会去忍受。
所以虽然在语言的表述上是:不要害怕得罪别人。而本质其实是: 能够就事论事的分清问题的边界。
如何分清责任边界,详见我的这篇文章: 分清责任边界|每个人只能为自己负责
5. 放弃“成为更好的人”“努力变得更优秀”的这种幻想。
好的,坏的,对的,错的,这些都不重要。你想要的,才是最重要的。
没错,我在建议你放弃变得更好,放弃努力,放弃变优秀。
而且试图变得更好,试图变得更优秀,试图变得更成功的这种信念是导致你的痛苦和不幸福的一个很重要的根源。
整个社会,整个人类世界都在推崇和鼓励你要去努力,要变得更好。
于是你开始对自己不满意,你开始讨厌自己,你开始强烈的不能接纳自己。
于是你开始自我否定,开始去追逐社会规定的那些优秀的定义,开始试图去迎合别人的看法,你因此变得很焦虑,你被对自己的不满和自己驱使着不断地向前走,你以为只要达成那些目标你就能轻松了,你就到达终点了,你就圆满了。
但是这一刻却始终不能到来,而你却一直被一种焦虑感控制和驱使着,这样你变得越来越着急,你觉得必须尽快到达那个终点,只有到达那个终点,只有变得更优秀了你才能不再这么焦虑,于是这种着急和焦虑会令你变得越来越浮躁,你会发现你离那些目标越来越远。
而有那么一些人即便是侥幸到达了他所自以为的那个终点,但到达的那一刻他却发现自己好像并没有体会到想象中的那种喜悦和满足,他也并没有放轻松,焦虑与痛苦始终还是如影随形。而他这个时候所体会到的很可能只是一种无边的空虚。
所以你有没有想过,追求外界的标准,追求别人的认可与赞同,追求变得所谓的“更优秀”其实一开始就是一条会伤害你的道路呢?
马斯洛提出人有五种需求,最高层的需求叫做自我实现。
这个「自我实现」指的就是「做“你自己”想做的事」「完成“你自己”的使命感」「追求“你自己”存在的意义」。
而你一直在试图满足“外在”的标准,这和你的本能需求无疑是背道而驰的。
真正的进步与提升是你基于接纳自我的基础上去完成你的目标,满足你的需求,你只是想做这件事情,仅此而已。
就像你吃一份你喜欢的冰淇淋,画一幅你想画的花,追一个你爱上的姑娘一样,这都是非常自然而然的事情,而不是为了达到一个怎样的标准,能够给自己贴上一个“优秀”或“厉害”的标签。
你也不会着急,充满焦虑,为了填补匮乏和焦虑而不停地催促自己,你会完全的放松,不疾不徐的按照你的节奏去做事,去生活。
成为“你自己”,而不是成为“优秀或卓越”,这才是自我实现的涵义,这也是你存活这一世的根本意义。
我相信看到这里,你的认知层面已经受到了一定的冲击,你也能够对你现在的看待你和别人的关系的方式有了一定的反思。
但是核心信念的改变,也只是停留在认知的层面上。知行合一,才能真正将你的问题解决。
对于你要在行动层面上做出的改变,我给出你如下的建议:
1. 将你所在意的别人对你的看法记录下来,然后尝试着去做出不被别人的看法所影响的行动。
“过于在意别人的看法”这本身是一个意识层面的问题。
别人对你有看法,这是一个客观事实,你改变不了。你很在意别人的想法,这对于你的意识而言,也是一个客观存在,我们短时间内可能没办法一时将其消除。
但是你可以控制的是你自己的行为和做法,你要做的就是, 即便你的意识层面很在意别人对你的看法,但你的行动层面依然能够不受其影响。
比如说,小赵认为你扎丸子头不好看。你以往的做法是就不扎丸子头了。而你接下来要练习的就是继续扎丸子头。
我知道对你来说很难,但克服这个困难本身就是你成长的过程。你要做的本来就是要去克服自己的心理障碍,而不是把这些困难和心理障碍和困难当成你不去做事情的理由。
你要记得,你不做某件事的理由只有两个:一个是你不想,一个是不可能完成。
困难不在这两者之内,当你尝试着克服一次这种不敢扎丸子头的恐惧时,你就已经是在客服“太过在意别人的看法”这个问题了。
2. 尝试着与别人起最少三次的冲突,并绝对的坚持你自己的决定,而不被别人说服。
我知道绝大多数的人看到这个练习都会本能的抗拒而不会去做。
但不需要过多的解释,只要是能做去尝试这个练习的人,就一定能摆脱过于在意别人的看法的问题。
3. 尝试表达出自己的需求与感受。
“我没有时间帮你!”
“如果你不能够像一个朋友一样尊重我,那我也没有必要去尊重你。”
“在我小时候你们伤害了我很多,所以不要再继续试图控制我,我不要再去任由你们摆布,今后我要过自己的生活。”
“我希望你能够多关注我,多陪陪我。”
“你要求我理解你,但为什么你却并没有理解我?即便是我理解你,但你对我造成了伤害,我就有权利拒绝你。”
“别他妈的再对我评头论足,我他妈想做什么是我自己的事,和你们这帮傻X有个鸡毛关系。”
“不!”
是不是有好多类似于这样的话在你的心中憋了好久了?但每次总是非常难以把这些话说出口?
其实你知道自己的需要是什么,或者说最起码的,你肯定知道自己不想要的是什么。
你只是难以拒绝,不敢拒绝,也不会拒绝罢了。
那么你接下来要练习的,就是把这些你以往不敢说的话痛快的说出来,你要做的是不再委屈你自己,不再去照顾和体谅别人,不再被别人所控制,而是明确你的界限,捍卫你自己的立场,将你自己先保护好。
很多人说找不到、不知道自己想要的是什么,但你只有能够坚定的拒绝那些你不想要的,你才能够坚定的维护好那些你自己所想要的。
寻找自己真正想做的事,追求自我实现,这本身就是一件非常难的事情。你可以先从拒绝自己不想要的开始做起,拒绝的多了,那些你想要的,也就会慢慢的明晰。
《明朝那些事儿》最后说:这世上只有一种成功,就是用你喜欢的方式度过一生。
这句话对我的影响一直重大而深刻,在许多年的生存,工作,搬迁,交际,追逐,选择的过程中,这句话始终在提醒着我:你活着是为了你自己,你对于自己负有完全的责任。金钱也好,名声也好,地位也好,这些都会诱惑和吸引着你的“社会我”。但你始终要记得,你不是社会的奴隶,你也不是社会的工具,你更不是社会的一个零件。
归根结底,活着就是三个字:
做自己。
以上。
说明:
1. 左岸读书_blog by 左岸 © From 2008 致力于美好的读书体验。
2. 手机访问: http://wap.zreading.cn
3. 微博: http://weibo.com/zreading
4. 左岸.思文.群号: 188145065
5. 还有: 人生旅图和 冷知识
6. 微信:zreading
7.
| 您可能也喜欢: |
 怪力乱神-写给我思念的中国 怪力乱神-写给我思念的中国
|
| 有人说富二代值得羡慕,我说你大错特错了
|
| 就要摆事实,讲道理
|
| 写给女儿弯弯的一封信 | 左岸读书 | Page 2
|
| 坟场里的一捆柴火
|
| 无觅 |
↧
↧
分布式系统常用思想和技术总结
http://blog.arganzheng.me/posts/thinking-in-distributed-systems.html
分布式系统常用思想和技术总结
February 10, 2014
一、分布式系统的难点
分布式系统比起单机系统存在哪些难点呢?
1. 网络因素
由于服务和数据分布在不同的机器上,每次交互都需要跨机器运行,这带来如下几个问题:
1. 网络延迟:性能、超时
同机房的网络IO还是比较块的,但是跨机房,尤其是跨IDC,网络IO就成为不可忽视的性能瓶颈了。并且,延迟不是带宽,带宽可以随便增加,千兆网卡换成万兆,只是成本的问题,但延迟是物理限制,基本不可能降低。
这带来的问题就是系统整体性能的降低,会带来一系列的问题,比如资源的锁住,所以系统调用一般都要设置一个超时时间进行自我保护,但是过度的延迟就会带来系统的RPC调用超时,引发一个令人头疼的问题:分布式系统调用的三态结果:成功、失败、超时。不要小看这个第三态,这几乎是所有分布式系统复杂性的根源。
针对这个问题有一些相应的解决方案:异步化,失败重试。 而对于跨IDC数据分布带来的巨大网络因素影响,则一般会采用数据同步,代理专线等处理方式。
2. 网络故障:丢包、乱序、抖动。
这个可以通过将服务建立在可靠的传输协议上来解决,比如TCP协议。不过带来的是更多的网络交互。因此是性能和流量的一个trade off。这个在移动互联网中更需要考虑。
2. 鱼与熊掌不可兼得——CAP定律
CAP理论是由Eric Brewer提出的分布式系统中最为重要的理论之一:
- Consistency:[强]一致性,事务保障,ACID模型。
- Availiablity:[高]可用性,冗余以避免单点,至少做到柔性可用(服务降级)。
- Partition tolerance:[高]可扩展性(分区容忍性):一般要求系统能够自动按需扩展,比如HBase。
CAP原理告诉我们,这三个因素最多只能满足两个,不可能三者兼顾。对于分布式系统来说,分区容错是基本要求,所以必然要放弃一致性。对于大型网站来说,分区容错和可用性的要求更高,所以一般都会选择适当放弃一致性。对应CAP理论,NoSQL追求的是AP,而传统 数据库追求的是CA,这也可以解释为什么传统数据库的扩展能力有限的原因。
在CAP三者中,“可扩展性”是分布式系统的特有性质。分布式系统的设计初衷就是利用集群多机的能力处理单机无法解决的问题。当需要扩展系统性能时,一种做法是优化系统的性能或者升级硬件(scale up),一种做法就是“简单”的增加机器来扩展系统的规模(scale out)。好的分布式系统总在追求”线性扩展性”,即性能可以随集群数量增长而线性增长。
可用性和可扩展性一般是相关联的,可扩展行好的系统,其可用性一般会比较高,因为有多个服务(数据)节点,不是整体的单点。所以分布式系统的所有问题,基本都是在一致性与可用性和可扩展性这两者之间的一个协调和平衡。对于没有状态的系统,不存在一致性问题,根据CAP原理,它们的可用性和分区容忍性都是很高,简单的添加机器就可以实现线性扩展。而对于有状态的系统,则需要根据业务需求和特性在CAP三者中牺牲其中的一者。一般来说,交易系统类的业务对一致性的要求比较高,一般会采用ACID模型来保证数据的强一致性,所以其可用性和扩展性就比较差。而其他大多数业务系统一般不需要保证强一致性,只要最终一致就可以了,它们一般采用BASE模型,用最终一致性的思想来设计分布式系统,从而使得系统可以达到很高的可用性和扩展性。
CAP定律其实也是衡量分布式系统的重要指标,另一个重要的指标是性能。
一致性模型
主要有三种:
- Strong Consistency(强一致性):新的数据一旦写入,在任意副本任意时刻都能读到新值。比如:文件系统,RDBMS,Azure Table都是强一致性的。
- Week Consistency(弱一致性):不同副本上的值有新有旧,需要应用方做更多的工作获取最新值。比如Dynamo。
- Evantual Consistency(最终一致性):一旦更新成功,各副本的数据最终将达到一致。
从这三种一致型的模型上来说,我们可以看到,Weak和Eventually一般来说是异步冗余的,而Strong一般来说是同步冗余的(多写),异步的通常意味着更好的性能,但也意味着更复杂的状态控制。同步意味着简单,但也意味着性能下降。
以及其他变体:
- Causal Consistency(因果一致性):如果Process A通知Process B它已经更新了数据,那么Process B的后续读取操作则读取A写入的最新值,而与A没有因果关系的C则可以最终一致性。
- Read-your-writes Consistency(读你所写一致性):如果Process A写入了最新的值,那么 Process A的后续操作都会读取到最新值。但是其它用户可能要过一会才可以看到。
- Session Consistency(会话一致性):一次会话内一旦读到某个值,不会读到更旧的值。
- Monotonic Read Consistency(单调一致性):一个用户一旦读到某个值,不会读到比这个值更旧的值,其他用户不一定。
等等。
其中最重要的变体是第二条:Read-your-Writes Consistency。特别适用于数据的更新同步,用户的修改马上对自己可见,但是其他用户可以看到他老的版本。Facebook的数据同步就是采用这种原则。
二、分布式系统常用技术和应用场景
- consistent hashing [with virtual node]:一致性哈希,数据分布
- vector clock:时钟向量,多版本数据修改
- Quorum W+R>N [with vector clock]:抽屉原理,数据一致性的另一种解决方案。时钟向量,多版本数据修改。
- Merkle tree [with anti-entropy]:数据复制
- MVCC:copy-on-write与snapshot
- 2PC/3PC:分布式事务
- Paxos:强一致性协议
- Symmetry and Decentralization:对称性和去中心化。对称性(symmetry)简化了系统的配置和维护。去中心化是对对称性的延伸,可以避免master单点,同时方便集群scale out。
- Map-Reduce:分而治之;移动数据不如移动计算。将计算尽量调度到与存储节点在同一台物理机器上的计算节点上进行,这称之为本地化计算。本地化计算是计算调度的一种重要优化。
- Gossip协议:节点管理
- Lease机制:
consistent hashing:一致性哈希,解决数据均衡分布问题
我们通常使用的hash 算法是hash() mod n,但是如果发生某个节点失效时,无法快速切换到其他节点。为了解决单点故障的问题,我们为每个节点都增加一个备用节点,当某个节点失效时,就自动切换到备用节点上,类似于数据库的master和slave。但是依然无法解决增加或删除节点后,需要做hash重分布的问题,也就是无法动态增删节点。这时就引入了一致性hash的概念 ,将所有的节点分布到一个hash环上,每个请求都落在这个hash环上的某个位置,只需要按照顺时针方向找到的第一个节点,就是自己需要的服务节点。当某个节点发生故障时,只需要在环上找到下一个可用节点即可。

一致性hash算法最常用于分布式cache中,比如注意的memcached。Dynamo也用其作为数据分布算法,并且对一致性算法进行了改进,提出了基于虚拟节点的改进算法,其核心思路是引入虚拟节点,每个虚拟节点都有一个对应的物理节点,而每个物理节点可以对应若干个虚拟节点。
关于一致性hash的更多内容,可以参考笔者另一篇博文: Memcached的分布式算法学习。
这篇文章也可以看看: 某分布式应用实践一致性哈希的一些问题
virtual node
前面说过,有的Consistent Hashing的实现方法采用了虚拟节点的思想。使用一般的hash函数的话,服务器的映射地点的分布非常不均匀。因此,使用虚拟节点的思想,为每个物理节点(服务器)在continuum上分配100~200个点。这样就能抑制分布不均匀,最大限度地减小服务器增减时的缓存重新分布。
Quorum W+R>N:抽屉原理,数据一致性的另一种解决方案
N: 复制的节点数,即一份数据被保存的份数。 R: 成功读操作的最小节点数,即每次读取成功需要的份数。 W: 成功写操作的最小节点数 ,即每次写成功需要的份数。
所以 W+R>N的意思是:对于有N份拷贝的分布式系统,写到W(W<=N)份成功算写成功,读R(R<=N)份数据算读成功。
这三个因素决定了可用性,一致性和分区容错性。W+R>N可以保证数据的一致性(C),W越 大数据一致性越高。这个NWR模型把CAP的选择权交给了用户,让用户自己在功能,性能和成本效益之间进行权衡。
对于一个分布式系统来说,N通常都大于3,也就说同一份数据需要保存在三个以上不同的节点上,以防止单点故障。W是成功写操作的最小节点数,这里的写成功可以理解为“同步”写,比如N=3,W=1,那么只要写成功一个节点就可以了,另外的两份数据是通过异步的方式复制的。R是成功读操作的最小节点数,读操作为什么要读多份数据呢?在分布式系统中,数据在不同的节点上可能存在着不一致的情况,我们可以选择读取多个节点上的不同版本,来达到增强一致性的目的。
NWR模型的一些设置会造成脏数据和版本冲突问题,所以一般要引入vector clock算法来解决这个问题。
需要保证系统中有max(N-W+1,N-R+1)个节点可用。
关于NWR模型,建议阅读 分布式系统的事务处理,写的很通俗易懂。
vector clock:时钟向量,多版本数据修改
参见 分布式系统的事务处理,写的很通俗易懂。
lease机制
chubby、zookeeper 获得lease(租约)的节点得到系统的承诺:在有效期内数据/节点角色等是有效的,不会变化的。
lease机制的特点:
- lease颁发过程只需要网络可以单向通信,同一个lease可以被颁发者不断重复向接受方发送。即使颁发者偶尔发送lease失败,颁发者也可以简单的通过重发的办法解决。
- 机器宕机对lease机制的影响不大。如果颁发者宕机,则宕机的颁发者通常无法改变之前的承诺,不会影响lease的正确性。在颁发者机恢复后,如果颁发者恢复出了之前的lease 信息,颁发者可以继续遵守lease的承诺。如果颁发者无法恢复lease信息,则只需等待一个最大的lease超时时间就可以使得所有的lease都失效,从而不破坏lease机制。
- lease机制依赖于有效期,这就要求颁发者和接收者的时钟是同步的。
- 如果颁发者的时钟比接收者的时钟慢,则当接收者认为lease已经过期的时候,颁发者依旧认为lease有效。接收者可以用在lease到期前申请新的lease的方式解决这个问题。
- 如果颁发者的时钟比接收者的时钟快,则当颁发者认为lease已经过期的时候,可能将lease颁发给其他节点,造成承诺失效,影响系统的正确性。对于这种时钟不同步,实践中的通常做法是将颁发者的有效期设置得比接收者的略大,只需大过时钟误差就可以避免对lease的有效性的影响。
工程中,常选择的lease时长是10秒级别,这是一个经过验证的经验值,实践中可以作为参考并综合选择合适的时长。
双主问题(脑裂问题)
lease机制可以解决网络分区问题造成的“双主”问题,即所谓的“脑裂”现象。配置中心为一个节点发放lease,表示该节点可以作为primary节点工作。当配置中心发现primary有问题时,只需要等到前一个primary的lease过期,就可以安全地颁发新的lease给新的primary节点,而不会出现“双主”问题。 在实际系统中,若用一个中心节点作为配置中心发送lease也有很大的风险。实际系统总是使用多个中心节点互为副本,成为一个小的集群,该小集群具有高可用性,对外提供颁发lease的功能。chubby和zookeeper都是基于这样的设计。
chubby一般有五台机器组成一个集群,可以部署成两地三机房。chubby内部的五台机器需要通过Paxos协议选取一个chubby master机器,其它机器是chubby slave,同一时刻只有一个chubby master。chubby相关的数据,比如锁信息,客户端的session信息等都需要同步到整个集群,采用半同步的做法,超过一半的机器成功就可以回复客户端。最后可以确保只有一个和原有的chubby master保持完全同步的chubby slave被选取为新的chubby master。
Gossip协议
Gossip用于P2P系统中自治节点获悉对集群认识(如集群的节点状态,负载情况等)。 系统中的节点定期互相八卦,很快八卦就在整个系统传开了。 A、B两个节点八卦的方式主要是:A告诉B知道哪些人的什么八卦;B告诉A这些八卦里B知道哪些更新了;B更新A告诉他的八卦...... 说是自治系统,其实节点中还有一些种子节点。种子节点的作用主要是在有新节点加入系统时体现。新节点加入系统中,先与种子节点八卦,新节点获得系统信息,种子节点知道系统中多了新节点。其他节点定期与种子节点八卦的时候就知道有新节点加入了。 各个节点互相八卦的过程中,如果发现某个节点的状态很长时间都没更新,就认为该节点已经宕机了。
Dynamo使用了Gossip协议来做会员和故障检测。
2PC、3PC、Paxos协议: 分布式事务的解决方案
分布式事务很难做,所以除非必要,一般来说都是采用最终一致性来规避分布式事务。
目前底层NoSQL存储系统实现分布式事务的只有Google的系统,它在Bigtable之上用 Java语言开发了一个系统 Megastore,实现了两阶段锁,并通过Chubby来避免两阶段锁协调者宕机带来的问题。Megastore实现目前只有简单介绍,还没有相关论文。
2PC
实现简单,但是效率低,所有参与者需要block,throughput低;无容错,一个节点失败整个事务失败。如果第一阶段完成后,参与者在第二阶没有收到决策,那么数据结点会进入“不知所措”的状态,这个状态会block住整个事务。
3PC
改进版的2PC,把2PC的第一个段break成了两段: 询问,然后再锁资源,最后真正提交。3PC的核心理念是:在询问的时候并不锁定资源,除非所有人都同意了,才开始锁资源。
3PC比2PC的好处是,如果结点处在P状态(PreCommit)的时候发生了Fail/Timeout的问题,3PC可以继续直接把状态变成C状态(Commit),而2PC则不知所措。
不过3PC实现比较困难,而且无法处理网络分离问题。如果preCommit消息发送后两个机房断开,这时候coordinator所在的机房会abort,剩余的participant会commit。
Paxos
Paxos的目的是让整个集群的结点对某个值的变更达成一致。Paxos算法是一种基于消息传递的一致性算法。Paxos算法基本上来说是个民主选举的算法——大多数的决定会成个整个集群的统一决定。
任何一个点都可以提出要修改某个数据的提案,是否通过这个提案取决于这个集群中是否有超过半数的结点同意(所以Paxos算法需要集群中的结点是单数)。这个是Paxos相对于2PC和3PC最大的区别,在2f+1个节点的集群中,允许有f个节点不可用。
Paxos的分布式民主选举方式,除了保证数据变更的一致性之外,还常用于单点切换,比如Master选举。
Paxos协议的特点就是难,both 理解 and 实现 :(
关于2PC,3PC和Paxos,强烈推荐阅读 分布式系统的事务处理。
目前大部分支付系统其实还是在2PC的基础上进行自我改进的。一般是引入一个差错处理器,进行差错协调(回滚或者失败处理)。
MVCC:多版本并发控制
这个是很多RDMS存储引擎实现高并发修改的一个重要实现机制。具体可以参考:
Map-Reduce思想
1. 分而治之
2. 移动数据不如移动计算
如果计算节点和存储节点位于不同的物理机器则计算的数据需要通过网络传输,此种方式的开销很大。另一种思路是,将计算尽量调度到与存储节点在同一台物理机器上的计算节点上进行,这称之为本地化计算。本地化计算是计算调度的一种重要优化。
经典论文和分布式系统学习
Dynamo
HBase
LSM Tree
- LSM(Log Structured Merge Trees)是B+ Tree一种改进
- 牺牲了部分读性能,用来大幅提高写性能
- 思路:拆分树
- 首先写WAL,然后记录数据到入到内存中,构建一颗有序子树(memstore)
- 随着子树越来越大,内存的子树会flush到磁盘上(storefile)
- 读取数据:必须遍历所有的有序子树(不知数据在哪棵子树)
- Compact:后台线程对磁盘中的子树进行归并,变成大树(子树多了读得慢)
事实上,lucene的索引机制也类似 Hbase的LSM树。也是写的时候分别写在单独的segment,后台进行segement合并。
http://blog.csdn.net/cxzhq2002/article/details/21738803
已有 0人发表留言,猛击->> 这里<<-参与讨论
ITeye推荐
↧
日本电影票房Top10全是二次元
转眼间2016年即将过去,各种盘点又集中出炉。今天我们注意到一个有些特别的榜单——日本本土电影票房排名。这份榜单特殊之处在于其所收录的今年日本票房最高的10部电影中全部都是于漫画、动画相关的影片。其中, 6部剧场版动画,3部漫画改编真人电影,还有1部特摄,而且借助《你的名字》和《新哥斯拉》两部作品的高票房成绩。
而如果展望明年的日本电影市场的话就会发现,二次元依旧是绝对主力。不算《名侦探柯南》、《哆啦A梦》、《精灵宝可梦》这样的年货剧场版,明年还有《刀剑神域》剧场版、改编自真人日剧的《花火》,以及基于《JOJO》、《亚人》、《银魂》、《钢之炼金术师》等漫画改编真人电影上映。

↧
[原]online db如何做字段扩充
声明:部分内容来自网络收集
需求
线上User表目前存在四个字段user(uid, name, passwd, nick),现在需要增加两个字段age, sex,变为user(uid, name, passwd, nick, age, sex)
背景
目前user表数据量较大,且并发请求量较大
解决方案:
方案一、
alter table add column
优势:方案最为简单
因为背景以及交代了,数据量较大,且并发请求高,MySQL在alter table时会锁表,且数据量较大,导致锁表时间过长,无法接受
方案二、
在项目上线初期,预留字段
优势:可以在需要扩展表字段的时候,自动使用预留的字段,因为字段在第一次建表时已经创建了,因此不需要扩充,直接使用已经存在的字段
劣势:1、预留字段的数量无法确定,预留多了,浪费存储空间,预留少了,未来还是要在表上增加字段(只是推迟了时间)
2、预留的字段只能定义为varchar类型的可辩字符串,无法支持其他类型字段,如果需要检索,varchar类型建立索引非理想方案
3、预留字段,字段名称不具有语义化,例如在建立初期,可能叫ext1、ext2等,但是ext1、ext2不具有语义化,后期维护沟通成本高
方案三
使用纵表存储用户信息,例如之前用户数据
uid | key | value |
|---|---|---|
| 1 | name | 张三 |
| 1 | passport | 123 |
| 1 | nick | NULL |
| 2 | name | 李四 |
| 2 | passport | 431 |
| 2 | nick | aaa |
需要扩展age, sex时,数据存储格式如下
uid | key | value |
|---|---|---|
| 1 | name | 张三 |
| 1 | passport | 123 |
| 1 | nick | NULL |
| 2 | name | 李四 |
| 2 | passport | 431 |
| 2 | nick | aaa |
| 3 | name | 王五 |
| 3 | passport | 123 |
| 3 | nick | NULL |
| 3 | age | 11 |
| 3 | sex | 1 |
优势:
1、可以随意新增字段,字段可以无限扩展
2、新旧数据可以同时存在
劣势:
1、同一个用户,单行数据变为多行存储,数据量翻倍
2、在key列不能建立索引(建立索引无不能起到检索作用),只能在uid列建立索引,检索方式太单一
方案四、
版本号+通用列
最开始上线的时候,版本为0,此时只有passwd和nick两个属性,那么数据为
uid | name | version | ext |
|---|---|---|---|
| 1 | 张三 | 0 | {"passport":"123",“nick”:NULL} |
| 2 | 李四 | 0 | {"passport":"431",“nick”:"aaa"} |
当需要扩展新字段时,将新数据版本升级为1,新增加age, sex两个字段,数据变为
uid | name | version | ext |
|---|---|---|---|
| 1 | 张三 | 0 | {"passport":"123",“nick”:NULL} |
| 2 | 李四 | 0 | {"passport":"431",“nick”:"aaa"} |
| 3 | 王五 | 1 | {"passport":"431",“nick”:"aaa","age":3,"sex":1} |
优势:
1、不需要做在线DDL,字段可以无限扩展(但是总长度不能超过768个字节)
2、新数据和老数据可以共存
3、迁移方便,可以线上写个脚本慢慢将老数据修改为新版本数据,并将version修改为1
劣势:
1、无法检索(虽然MySQL5.7开始支持JSON和JSON所以,目前本人未进行实际的性能测试)
2、ext列存在大量冗余的key,虽然可以将Key的值缩短,但是会降低key的语义
当然,也有一些将ext这种扩展信息存储在类似mongodb的NoSQL数据库中。
方案五、
新表+触发器+迁移数据+rename
基本原理是:
(1)先创建一个扩充字段后的新表user_new(uid, name, passwd, age, sex)
(2)在原表user上创建三个触发器,对原表user进行的所有insert/delete/update操作,都会对新表user_new进行相同的操作(这个操作有些公司也侵入到代码层面来实现)
(3)分批将原表user中的数据insert到新表user_new,直至数据迁移完成
(4)删掉触发器,把原表移走(默认是drop掉)
(5)把新表user_new重命名(rename)成原表user,扩充字段完成。
优势:整个过程不需要锁表,可以持续对外提供服务
劣势:
1、整个过程需要进行数据的迁移,如果数据量较大,可能周期较长
2、变更过程中,可能存在数据冲突
3、通过提供触发器或者代码来实现两次insert/delete/update操作,如果是建立触发器,会影响原表性能。
方案六、
增加1对1关联的扩展表
例如原来user(uid, name, passwd, nick)
新建一个user_ext表user(uid, age, sex)
通过uid进行一对一的关联
优势:
1、在不对原表进行任何操作的情况下,实现字段扩展
2、可持续对外提供服务,user表中历史数据,可以通过脚本在user_ext慢慢补齐或者在代码存在添加默认值,更新的时候做merge操作补齐
劣势:
1、两张表需要做join操作,在大量数据情况下,存在性能瓶颈。(互联网公司一般严格限制join的使用)
2、user_ext表未来也存在扩展字段的问题。
目前,如果存在对online db进行DDL时,一般公司都会采用第五种方案,虽然操作步骤比较多,周期较长,但是其优势也比较明显,不会增长数据量、不会丢失关系型数据库特性等等
作者:yangfei001 发表于2016/12/17 16:30:36 原文链接
阅读:7 评论:0 查看评论
↧